
Modélisation statistique
01. Inférence statistique
2024
Étude d’une population
La loi d’une population (qui décrit les valeurs possibles et leur fréquence/probabilité) contient toute l’information nécessaire.

Variabilité échantillonale

Histogrammes de 10 échantillons aléatoires simples de taille 20 tirés d’une loi uniforme.
Nature des données
- Est-ce que les données forment un échantillon aléatoire simple ou pas?
- si oui, elles sont représentatives et on peut généraliser les conclusions à toute la population
- Est-ce que le “traitement” est assigné de manière aléatoire?
- si oui, on parle de données expérimentales (plutôt qu’observationnelles).

Observationel versus expérimental
Sans ajustement supplémentaire, on ne peut tirer de conclusions ou d’énoncés de cause à effet avec des données observationnelles.

1. Examens de conduite en Grande-Bretagne
Est-ce que les examens pratiques de conduite en Grande-Bretagne sont plus faciles dans les régions à faible densité de population? Source: The Guardian, August 23rd, 2019
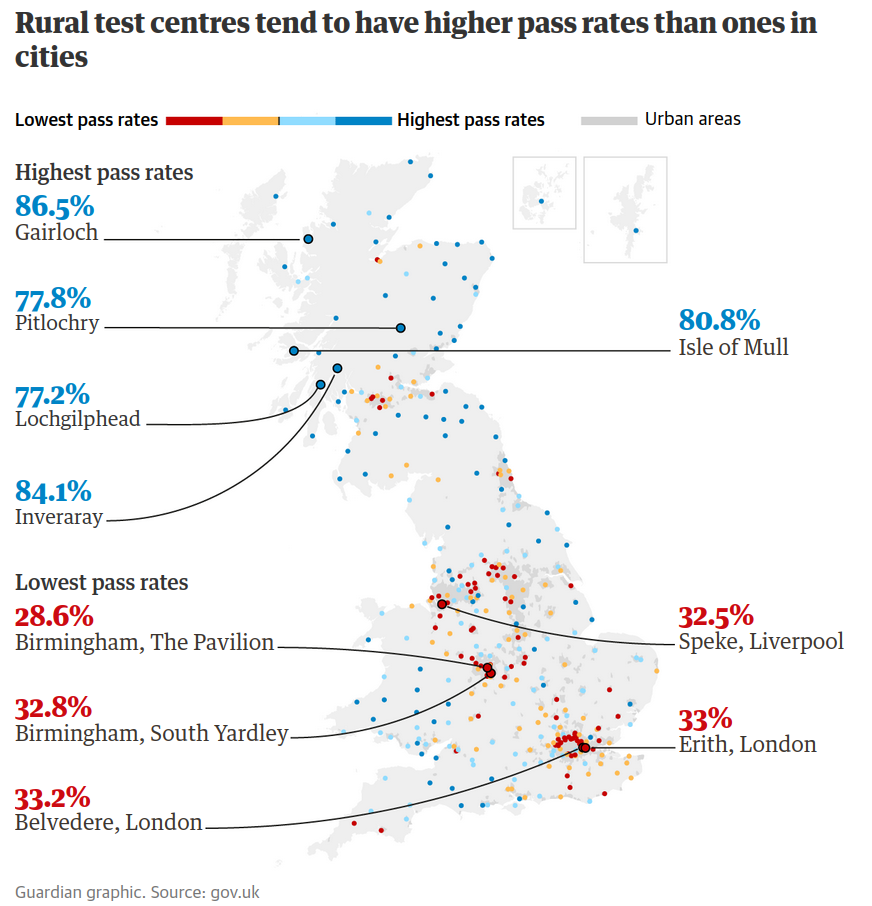
Modèle: régression binomiale logistique. Données gbconduite, paquet R hecmodstat.
2. Sécurité routière et distraction dues aux montres intelligentes

Modèle: Analyse de variance pour données répétées, ou tests nonparamétrique de Friedman. Données BRLS21_T3, paquet hecedsm.
Brodeur et al. (2021)
Une expérience intra-sujet a été menée dans un simulateur de conduite où 31 participants ont reçu des messages textuels et y ont répondu sous quatre scénarios: ils ont reçu des notifications (1) sur un téléphone portable, (2) sur une montre intelligente et (3) sur un haut-parleur, puis ont répondu oralement à ces messages. Ils ont également (4) reçu des messages textes où ils devaient répondre par texte aux notifications.
3. Perception environnemental des emballages plastiques

Sokolova, Krishna, et Döring (2023)
Huit études documentent le biais de perception du respect de l’environnement selon lequel les consommateurs jugent les emballages en plastique enrobés d’un emballage carton superflu plus respectueux de l’environnement que les emballages en plastique identiques sans carton.
Modèle: régression linéaire avec contrastes. Données SKD23_S2A, paquet hecedsm
4. Tests A/B et titres des nouvelles
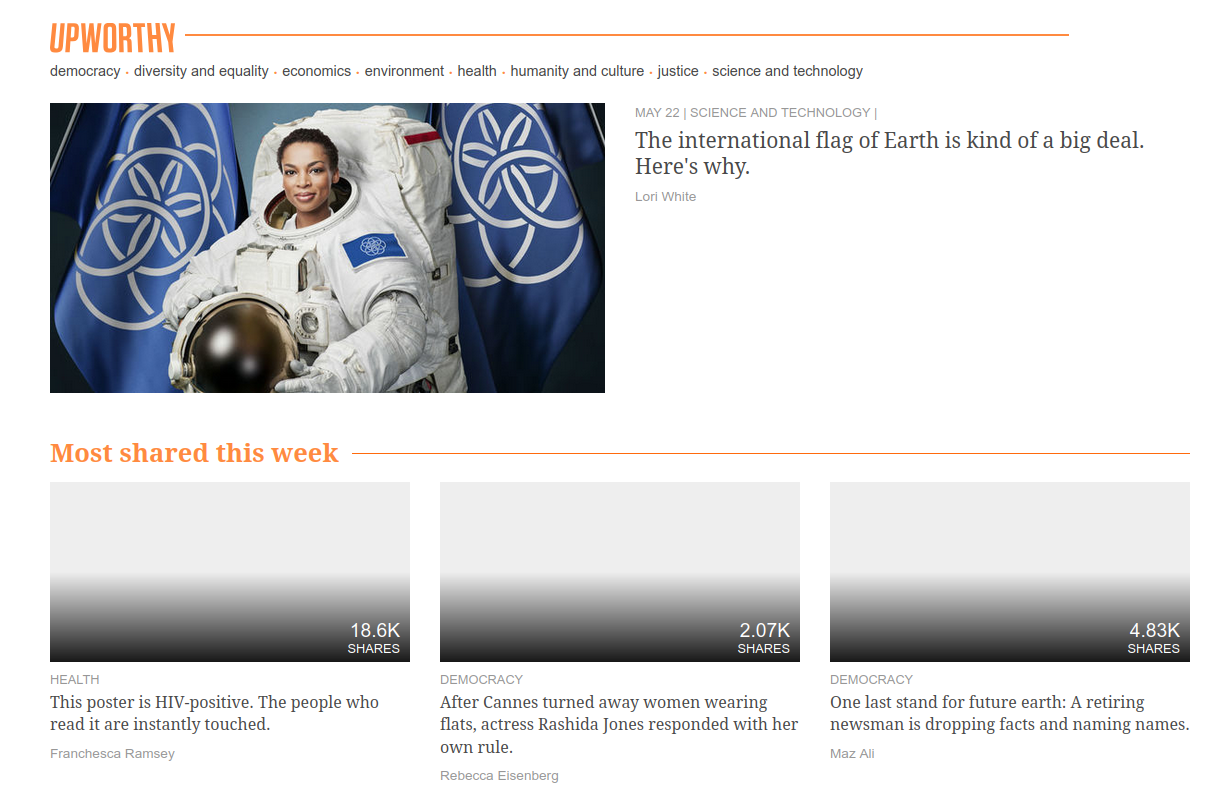
Upworthy.com, un éditeur de médias américain, a révolutionné la publicité en ligne en effectuant des tests A/B systématiques pour comparer les différentes formulations des titres, l’emplacement du texte et de l’image afin de déterminer ce qui attire le plus l’attention.
Les archives de recherche d’Upworthy (Matias et al. 2021) contiennent les résultats de 22743 expériences, avec un taux moyens de clics de 1.58% (écart type de 1.23%).
Modèle: régression Poisson avec décalage. Données upworthy_sesame, paquet hecbayes.
5. Impact de la visioconférence sur la créativité
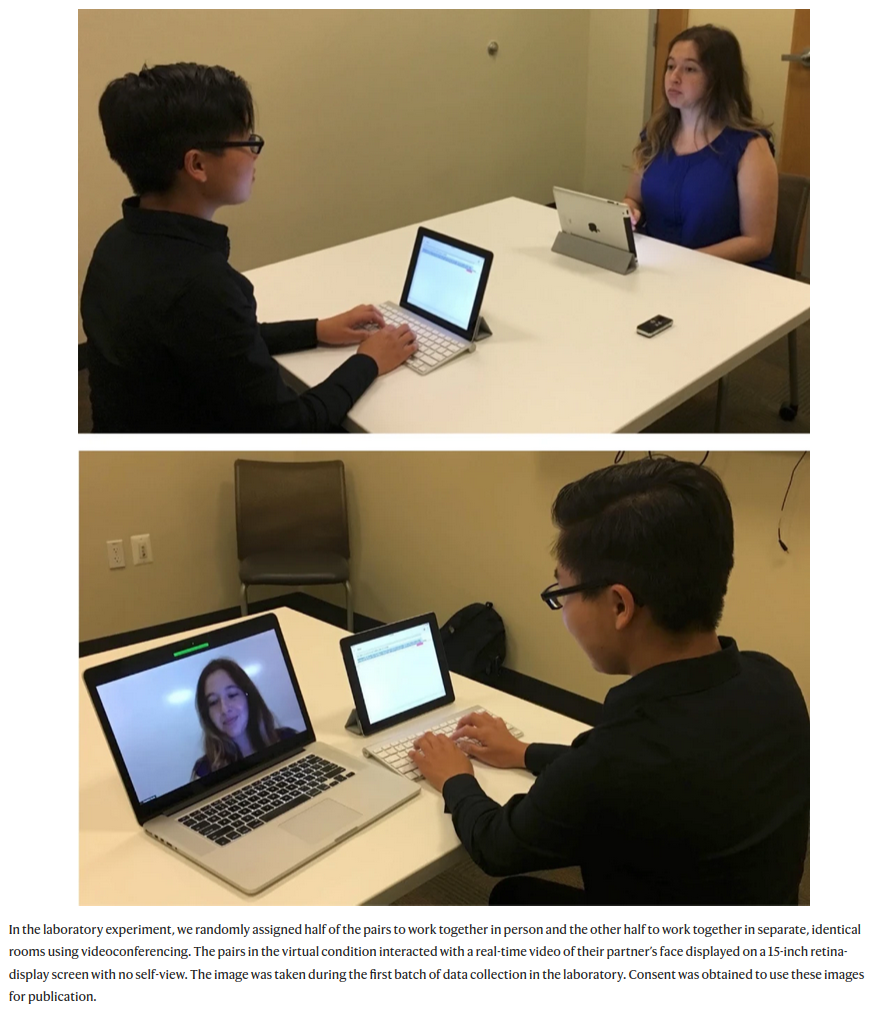
Brucks et Levav (2022)
Dans une étude en laboratoire et une expérience sur le terrain dans cinq pays (en Europe, au Moyen-Orient et en Asie du Sud), nous montrons que la vidéoconférence inhibe la production d’idées créatives […]
Nous démontrons que la vidéoconférence entrave la production d’idées parce que les communicants se concentrent sur l’écran, ce qui incite à une focalisation cognitive plus étroite. Nos résultats suggèrent que l’interaction virtuelle a un coût cognitif pour la génération d’idées créatives.
- Modèle 1: régression linéaire avec matrice d’équicorrélation/MANOVA. Données
BL22_E, paquethecedsm - Modèle 2: régression binomiale ou binomiale négative. Données
BL22_L, paquethecedsm.
6. Suggestion des montants pour les dons de charité
Moon et VanEpps (2023)
Dans sept études, nous démontrons que les suggestions de montants, où on propose des choix multiples sur le montant à donner (par exemple, 5\(, 10\) ou 15$), augmentent les contributions par rapport aux contributions libres.
Nos résultats offrent de nouvelles perspectives conceptuelles sur la façon dont ces propositions augmentent les contributions, ainsi que des implications pratiques pour les organisations caritatives afin d’optimiser les contributions.
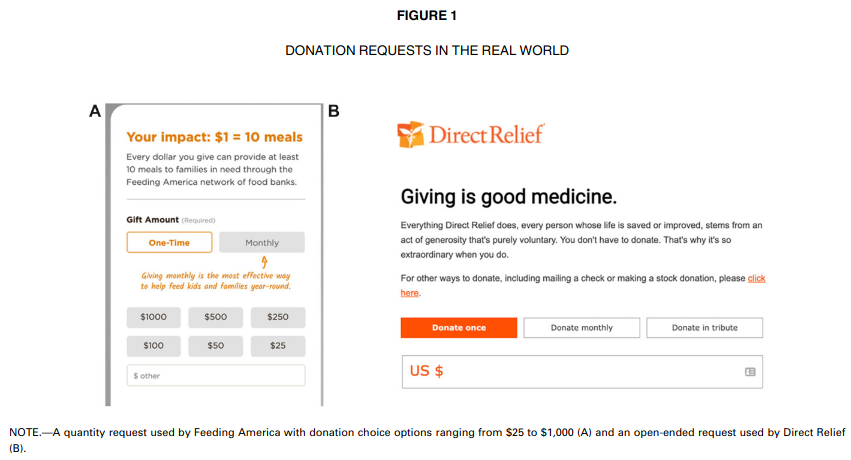
Modèle: régression Tobit de type II, régression Poisson. Données MV23_S1 du paquet hecedsm.
7. Décisions intégrées dans l’achat en ligne
Duke et Amir (2023)
Les clients doivent souvent décider de la quantité à acheter. La présente étude présente et compare le format de vente quantitatif-séquentiel, dans lequel les acheteurs prennent séparément les décisions d’achat et de quantité, avec le format de vente quantitatif-intégré, dans lequel les acheteurs prennent simultanément la décision d’acheter ou non et la quantité à acheter. Bien que les détaillants utilisent souvent le format séquentiel, nous démontrons que le format intégré peut augmenter les ventes.
Une expérience sur le terrain menée auprès d’une grande entreprise technologique a montré que l’intégration des quantités permettait d’augmenter considérablement les ventes, de plus d’un million de dollars par an.
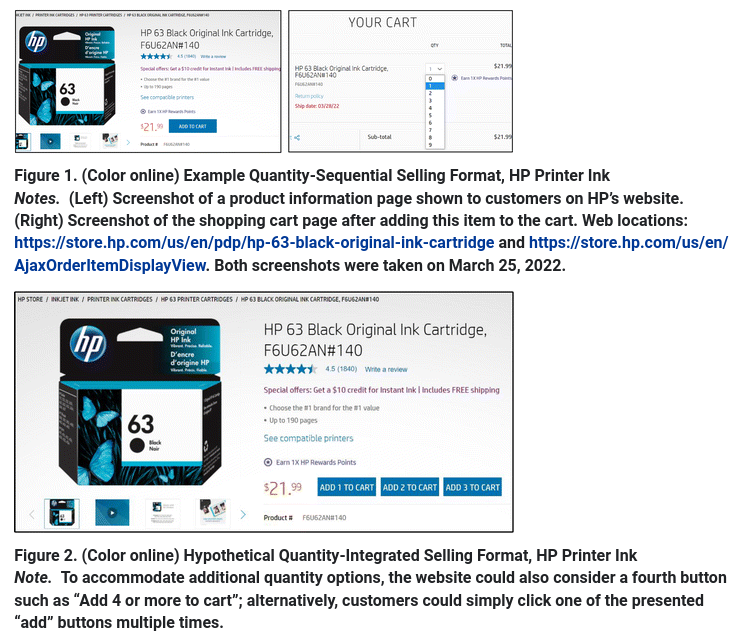
Modèle: régression logistique. Données DA23_E1, paquet hecedsm
8. Prix de l’essence en Gaspésie
Des maires ont demandé à la Régie de l’énergie d’enquête sur un possible cartel de l’essence en Gaspésie, où les prix au détail étaient anormalement élevés. Le rapport a conclu que les prix étaient plus élevés qu’attendu, mais que le nombre de détaillants par capita était plus élevé, ce qui réduisait les volumes de ventes et pouvait expliquer l’augmentation des marges observées.

Modèle: régression linéaire avec erreurs autorégressives. Données renergie, paquet hecmodstat.
Variabilité échantillonale
On ne peut comparer des statistiques sans prendre en compte l’incertitude inhérente due à la leur estimation à l’aide d’un échantillon aléatoire.

Figure 1: Cinq échantillons de taille 10 tirés d’une même population de moyenne \(\mu\) (ligne horizontale). Les segments colorés donnent les moyennes des sous-groupes.
Le signal et le bruit
Plus le rapport signal/bruit est important, plus notre capacité à détecter des différences existantes est grande.

Accumulation de l’information
À mesure que l’on collecte plus d’observations et que la taille de l’échantillon augmente, on peut mieux discriminer.

Figure 2: Histogrammes de données tirées d’une loi uniforme (haut) et d’une loi non-uniforme (bas) pour des tailles d’échantillons de 10, 100, 1000 and 10 000 (de gauche à droite).
Analogie du procès

Figure 3: Capture d’écran du drame Douze hommes en colère (1957)
Exemple: texter en marchant
Le centre de recherche en expérience utilisateur de HEC Montréal, le Tech3Lab, a effectué une étude sur la distraction causée le fait de texter en marchant.

Lois nulles

Figure 4: Approximation normale (traitillé) et basée sur les permutations (ligne pleine) pour une statistique de test. La valeur de la statistique observée sur l’échantillon est représentée par une droite verticale.
À quoi s’attendre pour les valeurs-\(p\)?
Si on répèt l’expérience avec des échantillons aléatoires simples, on s’attend à ce que les valeurs-\(p\) soit uniformes si \(\mathscr{H}_0\) est vraie et que la loi nulle est calibrée.
Sous l’alternative, les valeurs-\(p\) auront tendance à être plus petites.

Figure 5: Densité empirique des valeurs-p sous l’hypothèse nulle (gauche) et sous une alternative avec un rapport signal/bruit de 0.5 (droite).
Illustration du concept de puissance

Figure 6: Comparaison de la loi nulle (ligne pleine) et d’une alternative spécifique pour un test-\(t\) (ligne traitillée). La puissance correspond à l’aire sous la courbe de la densité de la loi alternative qui est dans la zone de rejet du test (en blanc). Le panneau du milieu représente l’augmentation de la puissance suite à l’augmentation de la taille d’effet (différence moyenne entre groupes plus élevée) sous l’hypothèse alternative. Le panneau de droite correspond à un scénario alternatif avec la même taille d’effet, mais une taille d’échantillon ou une précision plus grande.
Estimation: c’est pas du gâteau
On distingue entre notre objectif (estimand, par exemple la moyenne \(\mu\)), la recette ou formule (estimateur) et la sortie (estimé, une valeur numérique).



Propriétés fréquentistes des intervalles de confiance

Figure 8: Intervalles de confiance à 95% pour la moyenne d’une population normale standard pour 100 échantillons aléatoires. En moyenne, 5% de ces intervalles (en rouge) n’incluent pas la vraie valeur de la moyenne de zéro.
Références
![]()
Brodeur, Mathieu, Perrine Ruer, Pierre-Majorique Léger, et Sylvain Sénécal. 2021. « Smartwatches are more distracting than mobile phones while driving: Results from an experimental study ». Accident Analysis & Prevention 149: 105846. https://doi.org/10.1016/j.aap.2020.105846.
Brucks, Melanie S., et Jonathan Levav. 2022. « Virtual communication curbs creative idea generation ». Nature 605 (7908): 108‑12. https://doi.org/10.1038/s41586-022-04643-y.
Duke, Kristen E., et On Amir. 2023. « The Importance of Selling Formats: When Integrating Purchase and Quantity Decisions Increases Sales ». Marketing Science 42 (1): 87‑109. https://doi.org/10.1287/mksc.2022.1364.
Matias, J. Nathan, Kevin Munger, Marianne Aubin Le Quere, et Charles Ebersole. 2021. « The Upworthy Research Archive, a time series of 32,487 experiments in U.S. media ». Scientific Data 8 (195). https://doi.org/10.1038/s41597-021-00934-7.
McCullagh, P., et J. A. Nelder. 1989. Generalized linear models. Second edition. London: Chapman & Hall.
Moon, Alice, et Eric M VanEpps. 2023. « Giving Suggestions: Using Quantity Requests to Increase Donations ». Journal of Consumer Research 50 (1): 190‑210. https://doi.org/10.1093/jcr/ucac047.
Sokolova, Tatiana, Aradhna Krishna, et Tim Döring. 2023. « Paper Meets Plastic: The Perceived Environmental Friendliness of Product Packaging ». Journal of Consumer Research 50 (3): 468‑91. https://doi.org/10.1093/jcr/ucad008.
Comment modéliser