data(college, package = "hecmodstat")
mod <- lm(salaire ~ sexe + echelon + service, data = college)
summary(mod)$r.squared # R-carré dans la sortie
## [1] 0.4
y <- college$salaire # vecteur de variables réponse
yhat <- fitted(mod) # valeurs ajustées ychapeau
cor(y, yhat)^2 # coefficient R-carré
## [1] 0.4Modélisation statistique
05. Modèles linéaires (coefficient de détermination)
2024
Propriétés de la corrélation linéaire
Le signe de la corrélation détermine le signe de la pente (à la baisse pour \(\rho\) négatif, à la hausse pour \(\rho\) positive).
Si \(\rho>0\) (ou \(\rho<0\)), les deux variables sont positivement (négativement) associées, ce qui veut dire que \(Y\) augmente (diminue) en moyenne avec \(X\).
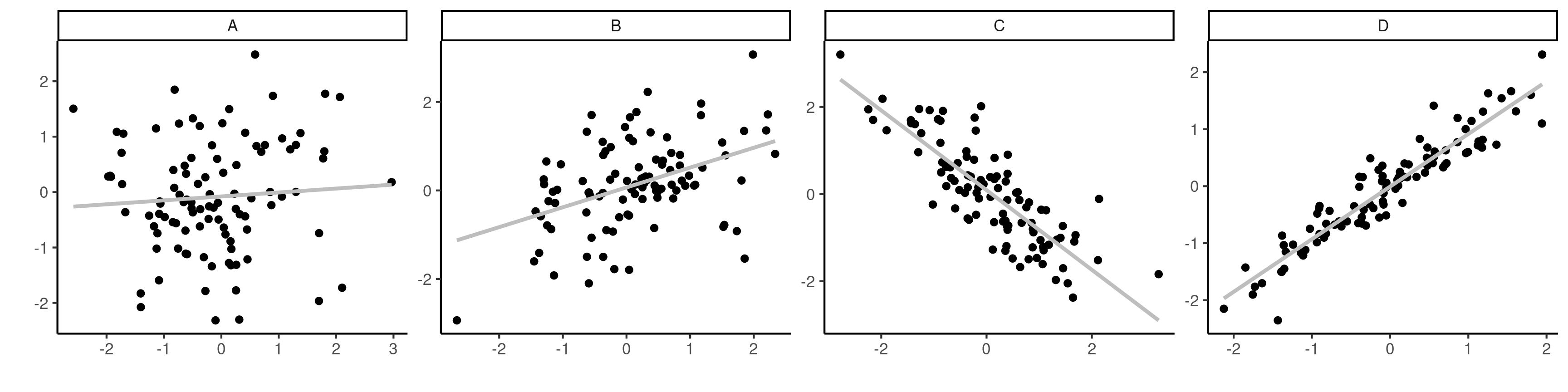
Figure 1: Nuages de points d’observations avec des corrélations de \(0.1\), \(0.5\), \(-0.75\) et \(0.95\) de \(A\) jusqu’à \(D\).
Corrélation et indépendance
- Les variables indépendantes ont une corrélation nulle (mais pas nécessairement l’inverse).
- Une corrélation linéaire de zéro indique seulement qu’il n’y a pas de dépendance linéaire entre les variables.
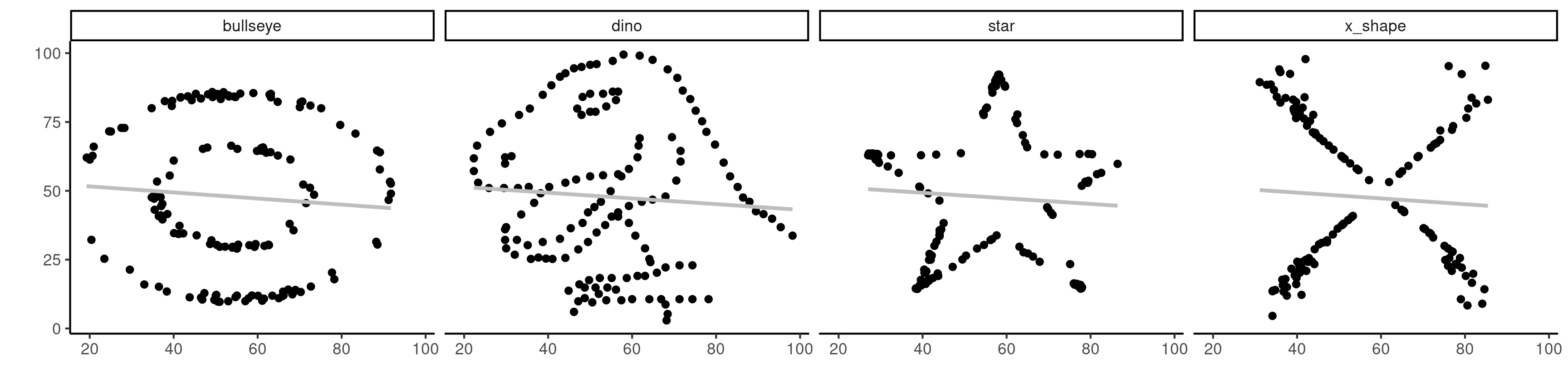
Figure 2: Quatre jeux de données avec des statistiques descriptives identiques, dont une corrélation linéaire de \(-0.06\).
Coefficient de détermination
On peut démontrer que le coefficient de détermination \(R^2\) est le carré de la corrélation linéaire entre la variable réponse \(\boldsymbol{y}\) et les valeurs ajustées \(\widehat{\boldsymbol{y}}\), \[R^2 = \mathsf{cor}^2(\boldsymbol{y}, \widehat{\boldsymbol{y}}).\]
- \(R^2\) prend toujours des valeurs entre \(0\) et \(1\).
- \(R^2\) n’est pas une mesure de la qualité de l’ajustement: le coefficient est non-décroissant à mesure que la dimension de \(\mathbf{X}\) augmente. Autrement dit, le plus de variables explicatives on ajoute, le plus grand le \(R^2\).
![]()