
Statistical modelling
01. Statistical Inference
2024
Studying a population
The population distribution (describing possible outcomes and their frequencies) encodes everything we could be interested in.
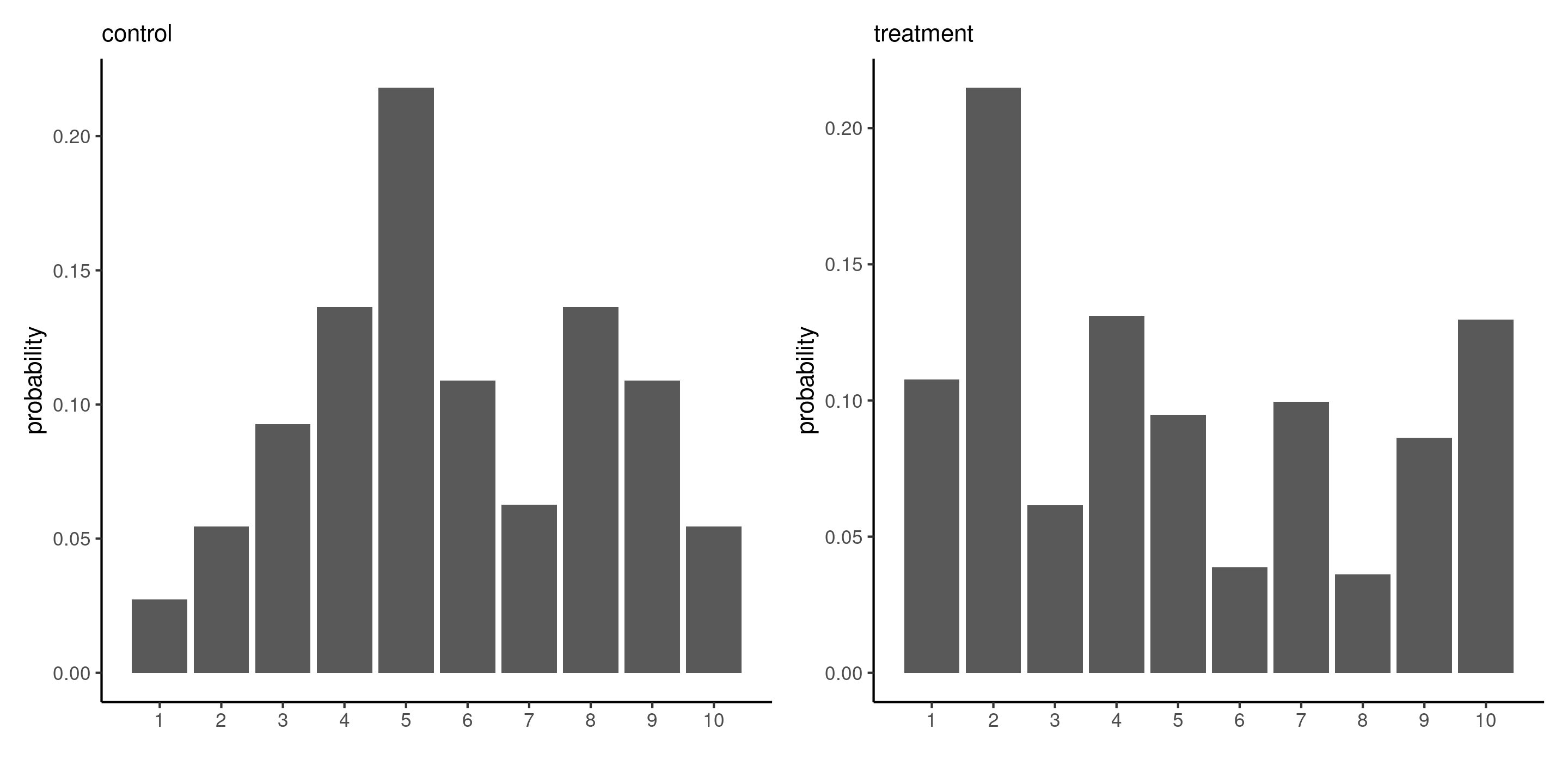
Sampling variability
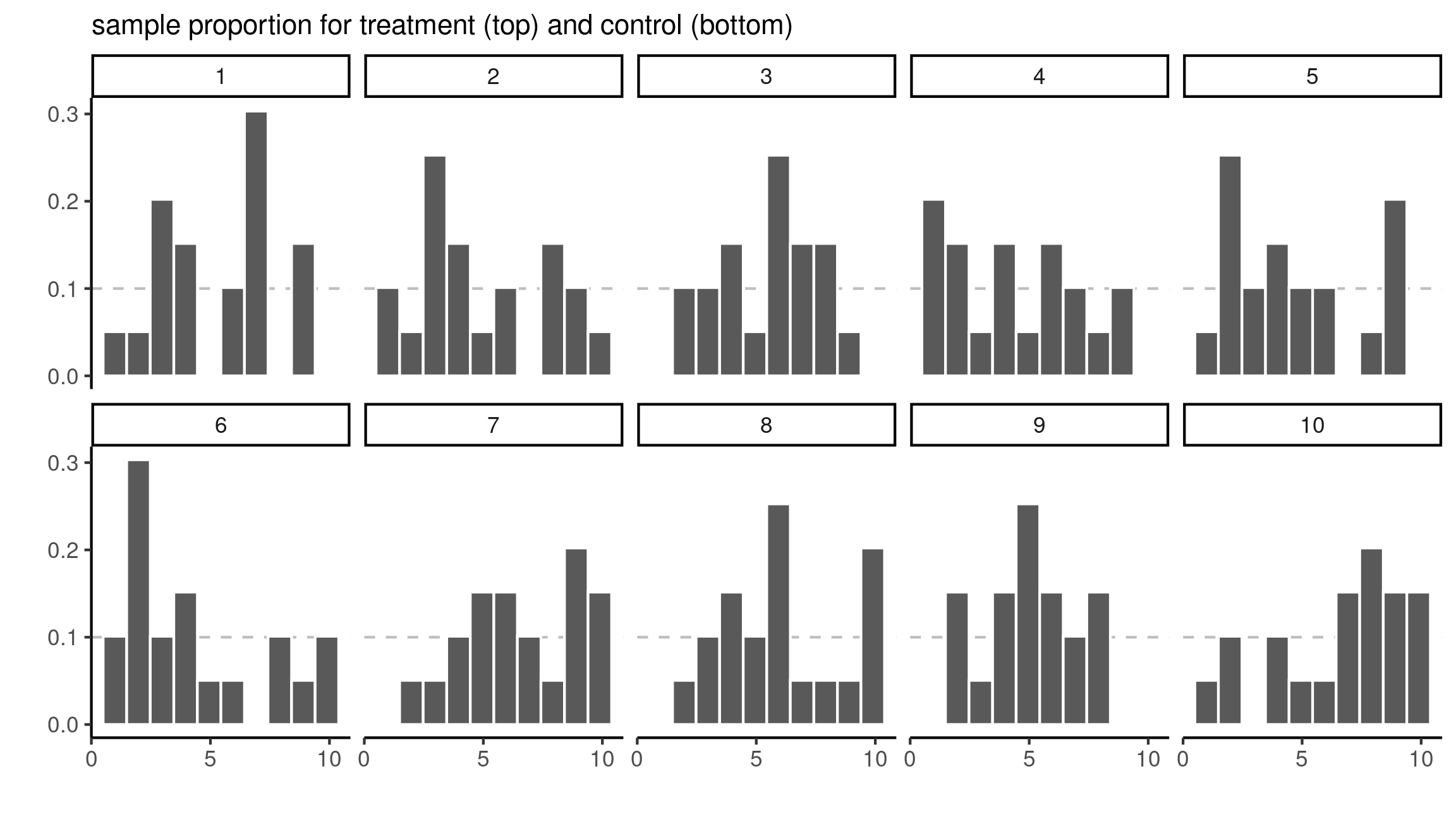
Histograms for 10 random samples of size 20 from a discrete uniform distribution.
Nature of data
- Are data from a random sample of the population or not?
- if so, can generalize conclusions.
- Is there a “treatment” randomly allocated?
- if so, data are experimental (as opposed to observational).

Observational vs experimental
Without further adjustment, we cannot draw causal statements from observational data.
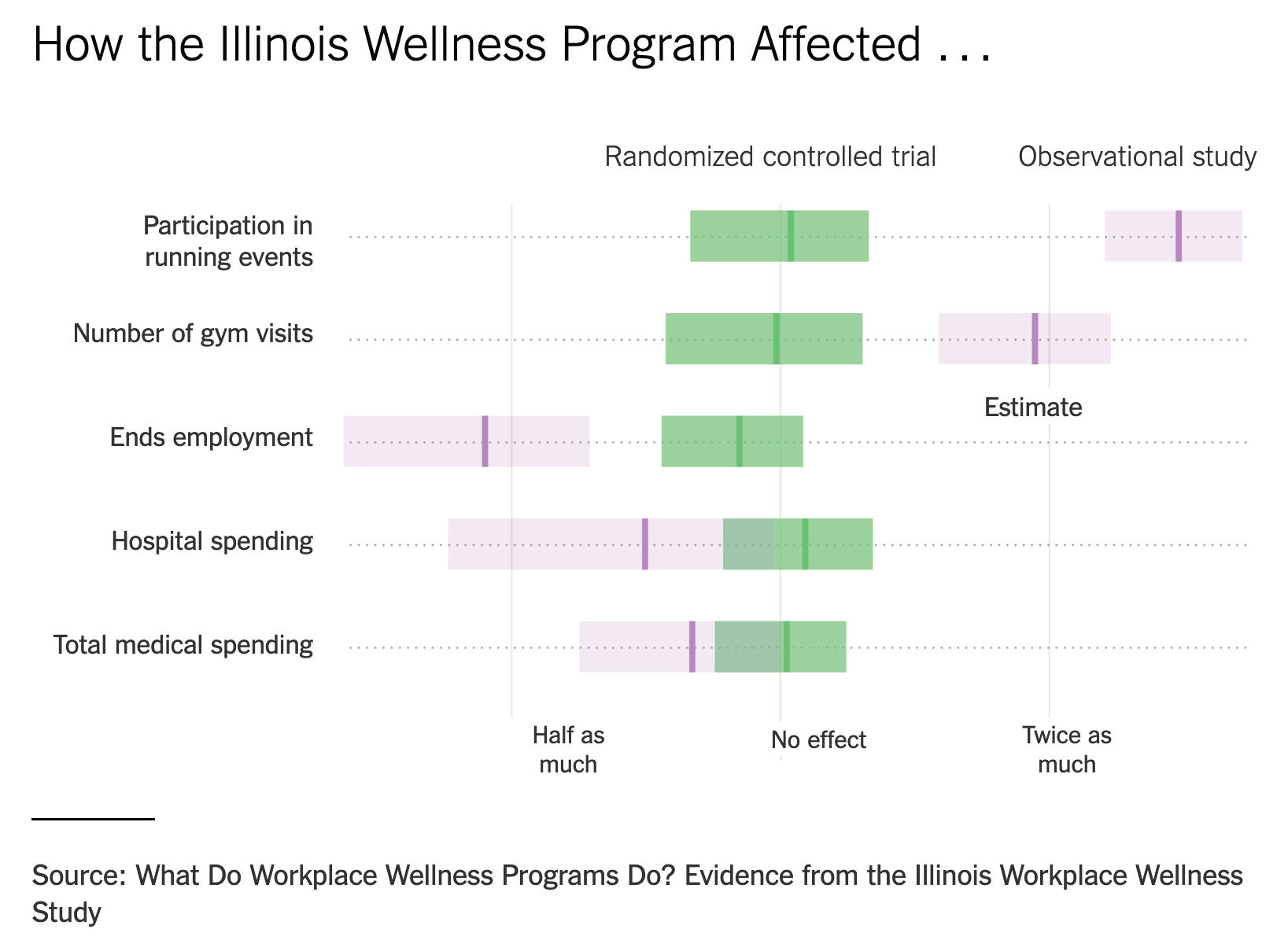
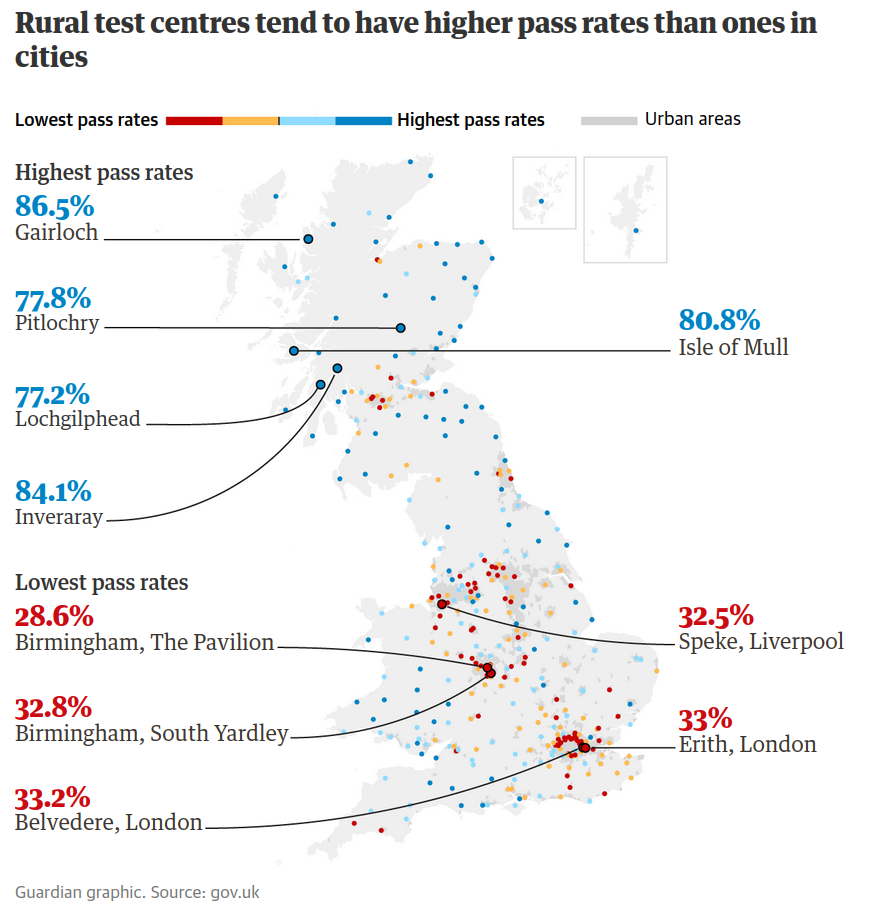
1. Driving exams in Great Britain
Are driving tests easier if you live in a rural area? Source: The Guardian, August 23rd, 2019
Model: binomial logistic model. Data gbdriving, R package hecstatmod.
2. Road safety and distraction due to smartwatches

Models: Within-subject ANOVA (repeated measures) with pairwise paired t-tests or nonparametric tests (Friedman + Wilcoxon signed-rank test). Dataset BRLS21_T3, package hecedsm.
Brodeur et al. (2021)
A within-subject experiment was conducted in a driving simulator where 31 participants received and answered text messages under four conditions: they received notifications (1) on a mobile phone, (2) on a smartwatch, and (3) on a speaker, and then responded orally to these messages. They also (4) received messages in a “texting” condition where they had to reply through text to the notifications.
3. Perceived environmental friendliness of packages

Sokolova, Krishna, and Döring (2023)
Eight studies (N = 4103) document the perceived environmental friendliness (PEF) bias whereby consumers judge plastic packaging with additional paper to be more environmentally friendly than identical plastic packaging without the paper.
Model: linear regression/ANOVA with custom contrasts. Dataset SKD23_S2A, package hecedsm
4. A/B tests and news headlines
Upworthy.com, a US media publisher, revolutionized headlines online advertisement by running systematic A/B tests to compare the different wording of headlines, placement of text and image to figure out what catches attention the most.
The Upworthy Research Archive (Matias et al. 2021) contains results for 22743 experiments, with a click through rate of 1.58% on average and a standard deviation of 1.23%.
Model: Poisson regression with offset. Data upworthy_sesame, package hecbayes.
5. Impact of videoconferencing on idea generation

Brucks and Levav (2022)
In a laboratory study and a field experiment across five countries (in Europe, the Middle East and South Asia), we show that videoconferencing inhibits the production of creative ideas […]
we demonstrate that videoconferencing hampers idea generation because it focuses communicators on a screen, which prompts a narrower cognitive focus. Our results suggest that virtual interaction comes with a cognitive cost for creative idea generation.
- Model: Linear regression with compound symmetry covariance/MANOVA. Dataset
BL22_E, packagehecedsm - Model: Binomial regression, dataset
BL22_Lfrom packagehecedsm.
6. Suggesting amounts for donations
Moon and VanEpps (2023)
Across seven studies, we provide evidence that quantity requests, wherein people consider multiple choice options of how much to donate (e.g., $5, $10, or $15), increase contributions compared to open-ended requests.
Our findings offer new conceptual insights into how quantity requests increase contributions as well as practical implications for charitable organizations to optimize contributions by leveraging the use of quantity requests.
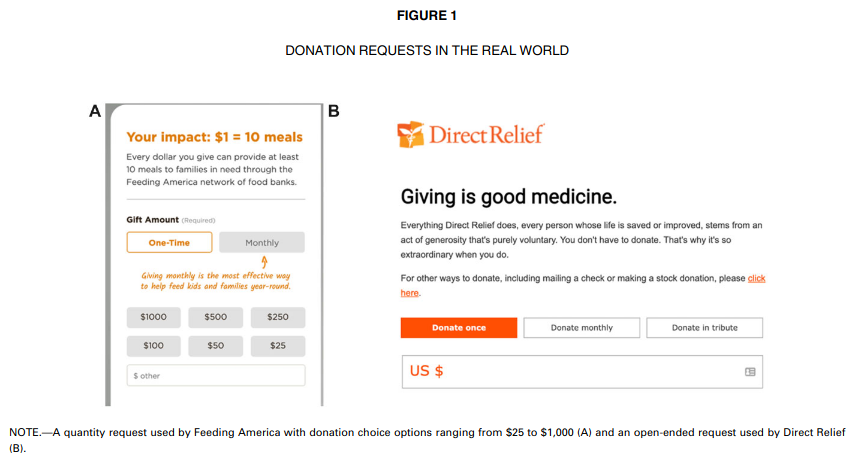
Model: Tobit type II regression and Poisson regression (independence test), data MV23_S1 from package hecedsm.
7. Integrated decisions in online shopping
Duke and Amir (2023)
Customers must often decide on the quantity to purchase in addition to whether to purchase. The current research introduces and compares the quantity-sequential selling format, in which shoppers resolve the purchase and quantity decisions separately, with the quantity-integrated selling format, where shoppers simultaneously consider whether and how many to buy. Although retailers often use the sequential format, we demonstrate that the integrated format can increase purchase rates.
A field experiment conducted with a large technology firm found that quantity integration yielded considerably higher sales, amounting to an increase of more than $1 million in annual revenue.
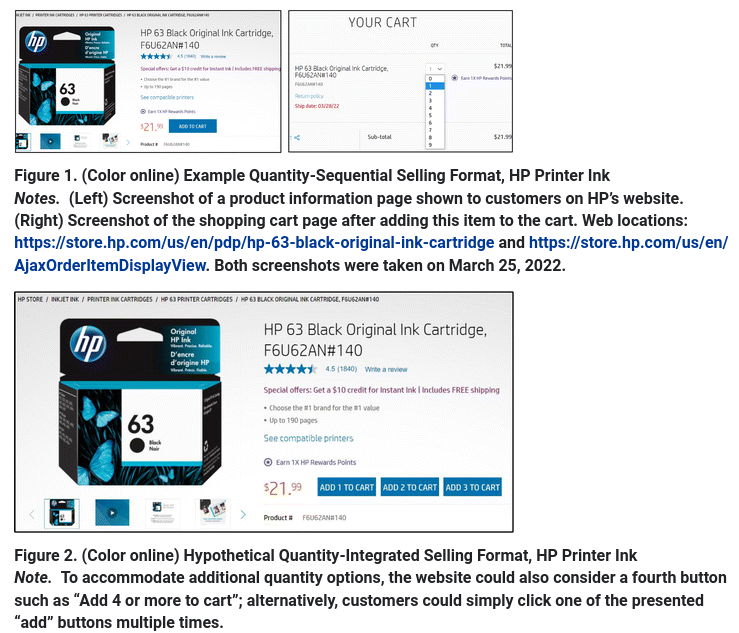
Model: logistic regression, dataset DA23_E1.
8. Price of oil in the Gaspe Peninsula
Mayors requested an inquiry by the Régie de l’énergie, a regulating agency in charge of energy prices. The report found that prices were indeed more expensive, but pointed out that there were more retailers per capita, and lower volume so their margins were higher.
Model: Linear regression with autoregressive errors, pairwise comparisons. Dataset renergy, package hecstatmod.

Sampling variability
We cannot compare summaries without accounting for their uncertainty inherent to our estimation which is due to random sample.
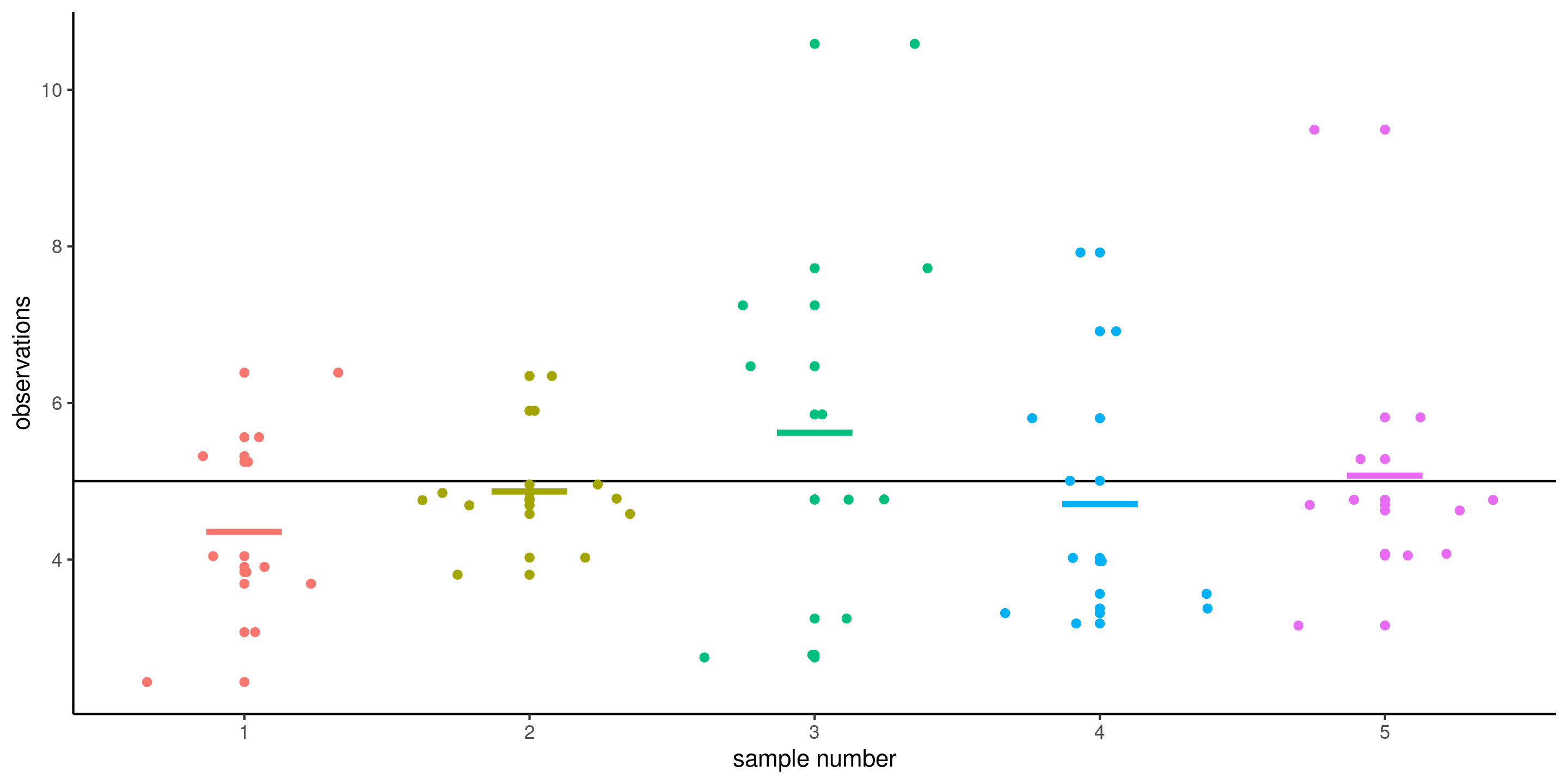
Figure 1: Five samples of size \(n=10\) drawn from a common population with mean \(\mu\) (horizontal line). The colored segments show the sample means of each sample.
The signal and the noise
The stronger the signal-to-noise ratio, the larger our ability to detect differences when they truly exist.
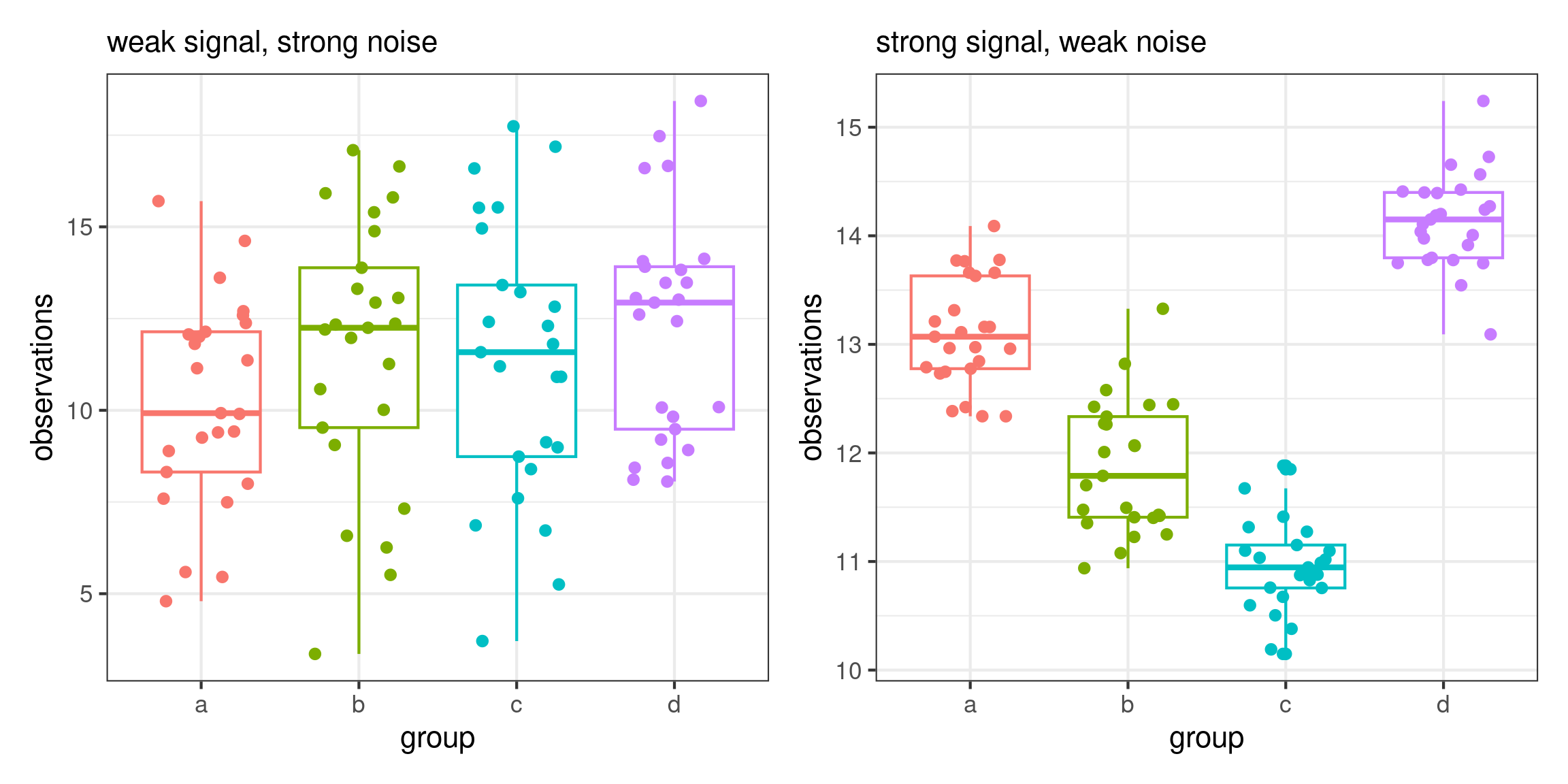
Accumulation of information
As we gather more observations (sample size increases), we can better discriminate between scenarios.
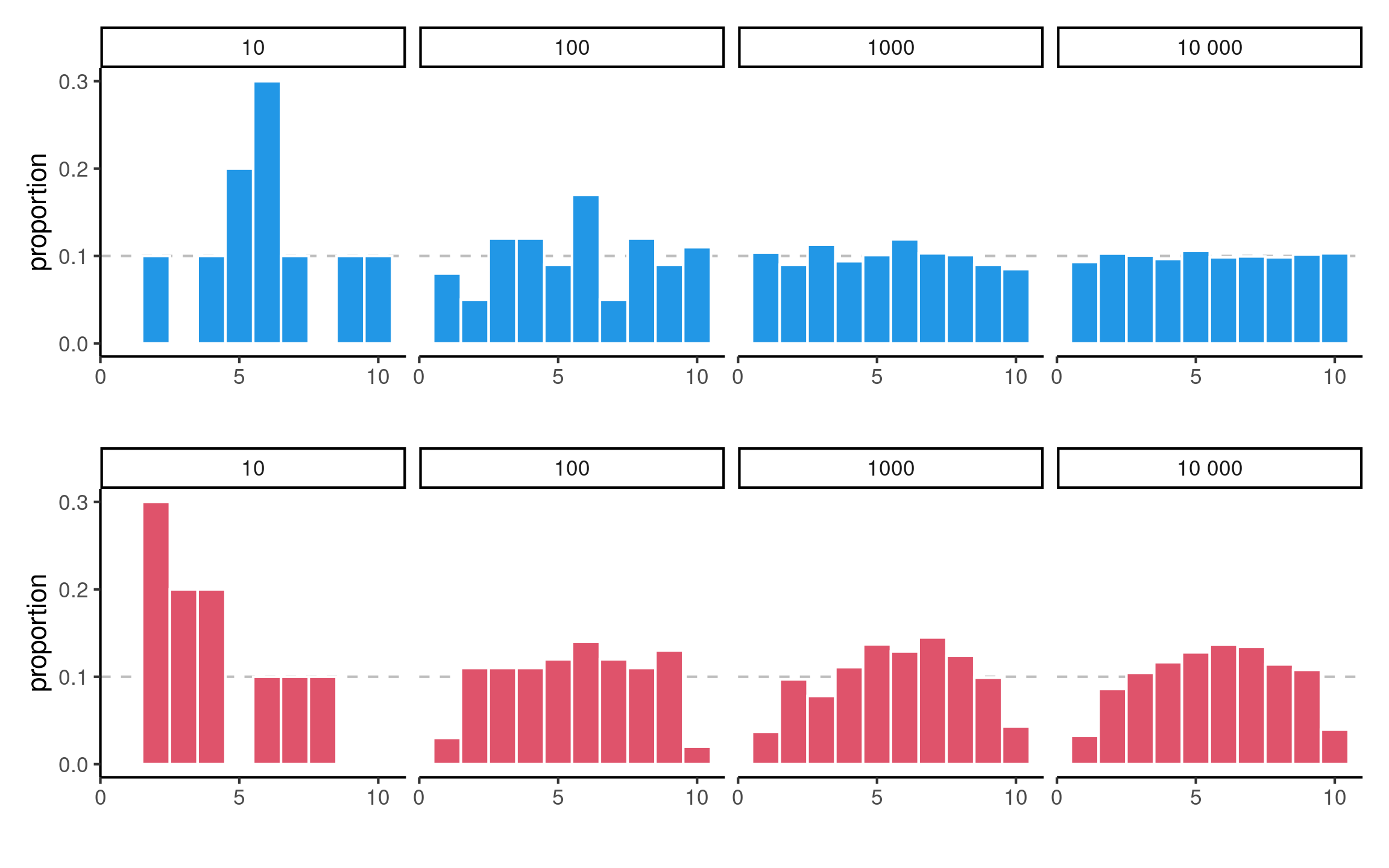
Histograms of data from uniform (top) and non-uniform (bottom) distributions with increasing sample sizes.
Running example: texting while walking
Tech3Lab, HEC Montreal’s User Experience (UX) lab, studied the impact of texting on distraction.

Hypothesis testing as a trial analogy

Figure 2: Screenshot of the courtoom drama Twelve Angry Men (1957)
Null distributions
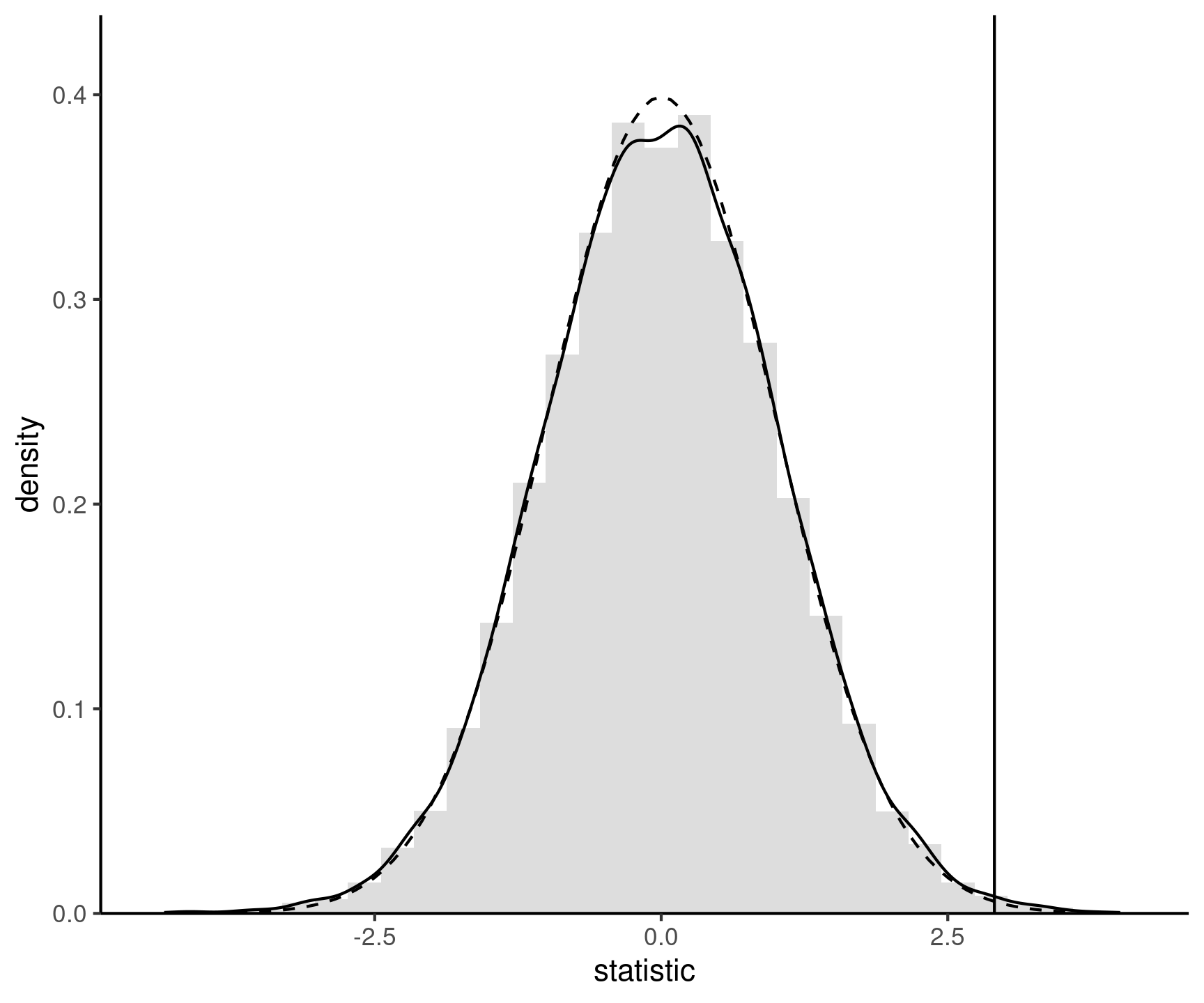
Figure 3: Sign permutation-based approximation to the null distribution (full) and standard normal approximation (dashed curve). The value of the test statistic calculated using the original sample is represented by a vertical line.
What can we expect of \(p\)-values?
If we repeat the experiment with random samples, we expect \(p\)-values to be uniform if \(\mathscr{H}_0\) is true and the null hypothesis benchmark is properly calibrated.
Under the alternative, smaller \(p\)-values occur more often than \(\alpha\).
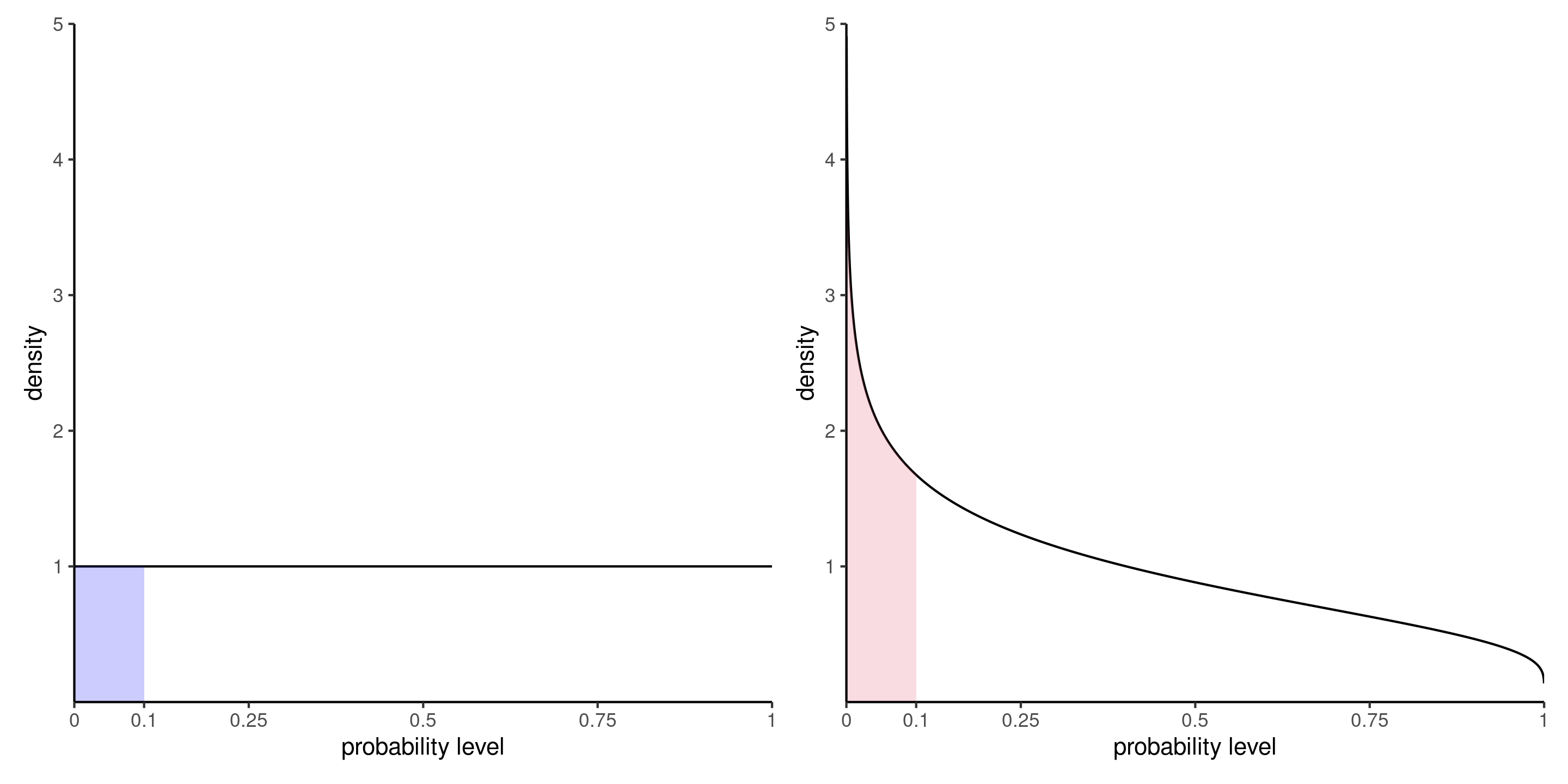
Figure 4: Density of p-values under the null hypothesis (left) and under an alternative with a signal-to-noise ratio of 0.5 (right).
Illustration of power
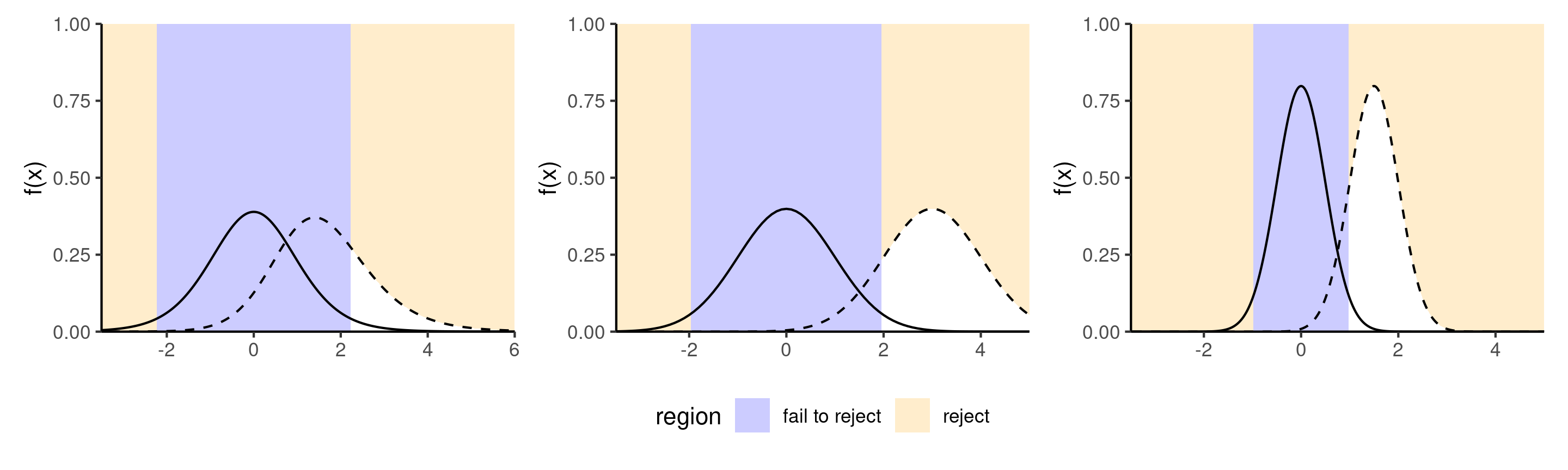
Figure 5: Comparison between null distribution (full curve) and a specific alternative for a t-test (dashed line). The power corresponds to the area under the curve of the density of the alternative distribution which is in the rejection area (in white). The middle panel shows an increase in power due to an increase in the mean difference, whereas the right panel shows the change due to a decrease in variability of increase in the sample size.
Estimation: a piece of cake
We distinguish between our target (estimand, e.g., population mean), the recipe or formula (estimator) and the output (estimate).



Frequentist properties of confidence intervals
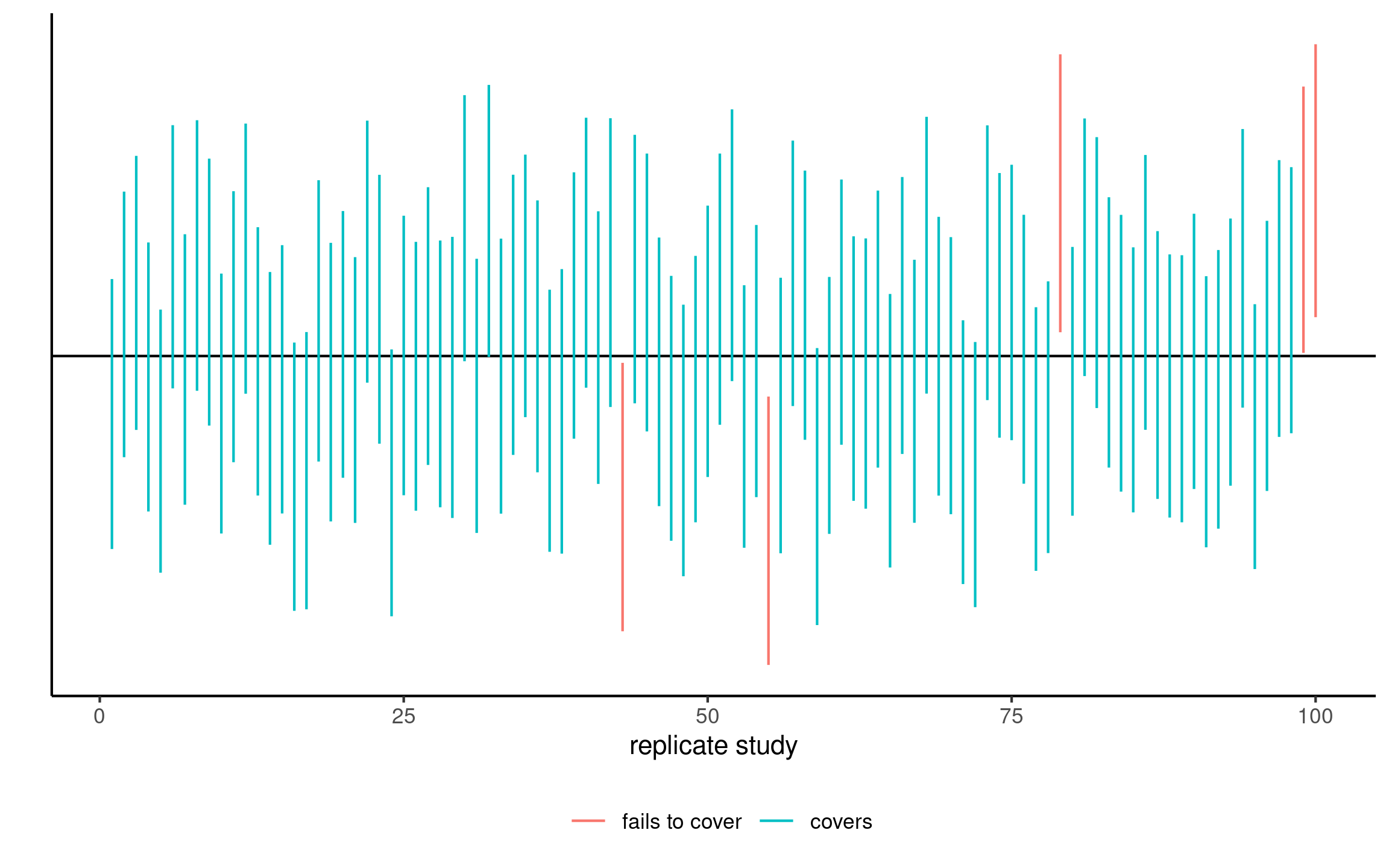
95% confidence intervals for the mean of a standard normal population for 100 random samples. On average, 5% of these intervals fail to include the true mean value of zero (in red).
References
![]()
Brodeur, Mathieu, Perrine Ruer, Pierre-Majorique Léger, and Sylvain Sénécal. 2021. “Smartwatches Are More Distracting Than Mobile Phones While Driving: Results from an Experimental Study.” Accident Analysis & Prevention 149: 105846. https://doi.org/10.1016/j.aap.2020.105846.
Brucks, Melanie S., and Jonathan Levav. 2022. “Virtual Communication Curbs Creative Idea Generation.” Nature 605 (7908): 108–12. https://doi.org/10.1038/s41586-022-04643-y.
Duke, Kristen E., and On Amir. 2023. “The Importance of Selling Formats: When Integrating Purchase and Quantity Decisions Increases Sales.” Marketing Science 42 (1): 87–109. https://doi.org/10.1287/mksc.2022.1364.
Matias, J. Nathan, Kevin Munger, Marianne Aubin Le Quere, and Charles Ebersole. 2021. “The Upworthy Research Archive, a Time Series of 32,487 Experiments in U.S. Media.” Scientific Data 8 (195). https://doi.org/10.1038/s41597-021-00934-7.
Moon, Alice, and Eric M VanEpps. 2023. “Giving Suggestions: Using Quantity Requests to Increase Donations.” Journal of Consumer Research 50 (1): 190–210. https://doi.org/10.1093/jcr/ucac047.
Sokolova, Tatiana, Aradhna Krishna, and Tim Döring. 2023. “Paper Meets Plastic: The Perceived Environmental Friendliness of Product Packaging.” Journal of Consumer Research 50 (3): 468–91. https://doi.org/10.1093/jcr/ucad008.