Chapitre 2 Analyse factorielle exploratoire
2.1 Introduction
On dispose de \(p\) variables \(X_1, \ldots, X_p\).
- Y a-t-il des groupements de variables?
- Est-ce que les variables faisant partie d’un groupement semblent mesurer certains aspects d’un facteur commun (non observé)?
Un tel groupement peut être détecté si plusieurs variables sont très corrélées entre elles. Est-ce que la structure de corrélation entre les \(p\) variables peut être expliquée à l’aide d’un nombre restreint de facteurs?
Exemple de facteurs: Habileté quantitative, habileté sociale, importance accordée à la qualité du service, importance accordée à la loyauté, habileté de leader, etc
L’analyse factorielle est aussi une méthode de réduction du nombre de variables. En effet, une fois qu’on a identifié les facteurs, on peut remplacer les variables individuelles par un résumé pour chaque facteur (qui est souvent la moyenne des variables qui font partie du facteur).
Pour faire une analyse factorielle, la taille d’échantillon devrait être conséquente: le nombre d’entrées dans la base de données est \(np\), et le nombre de paramètres de la matrice de covariance à estimer est \(\mathrm{O}(p^2)\). Plusieurs références, essentiellement arbitraires, suggèrent d’avoir une taille d’échantillon entre cinq et 20 fois le fois le nombre de variables, ou bien un nombre minimal de 100 à 1000 observations. Des études de simulations suggèrent que la taille critique dépend des paramètres, communalités, distribution des données, etc.
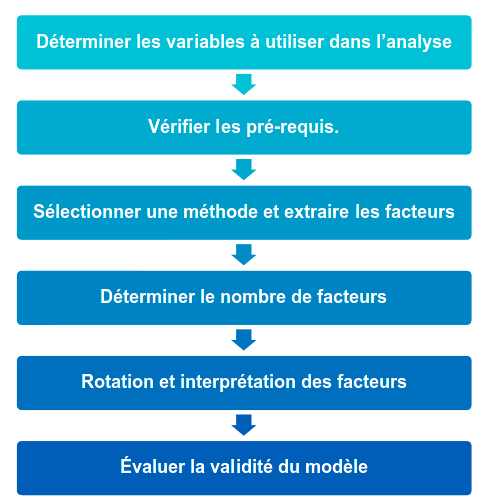
Figure 2.1: Schéma des différents étapes de l’analyse factorielle exploratoire.
2.2 Rappels sur le coefficient de corrélation linéaire
On veut examiner la relation entre deux variables \(X_j\) et \(X_k\) et on dispose de \(n\) couples d’observations, où \(x_{i, j}\) (respectivement \(x_{i, k}\)) est la valeur de la variable \(X_j\) (\(X_k\)) pour le \(i\)e individu.
Le coefficient de corrélation linéaire entre \(X_j\) et \(X_k\), que l’on note \(r_{j, k}\), cherche à mesurer la force de la relation linéaire entre deux variables, c’est-à-dire à quantifier à quel point les observations sont alignées autour d’une droite. Le coefficient de corrélation est \[\begin{align*} r_{j, k} = \frac{\sum_{i=1}^n (x_{i, j}-\overline{x}_j)(x_{i, k} -\overline{x}_{k})}{\left\{\sum_{i=1}^n (x_{i, j}-\overline{x}_j)^2 \sum_{i=1}^n(x_{i, k} -\overline{x}_{k})^2\right\}^{1/2}} \end{align*}\]
Les propriétés les plus importantes du coefficient de corrélation linéaire \(r\) sont les suivantes:
- \(-1 \leq r \leq 1\);
- \(r=1\) (respectivement \(r=-1\)) si et seulement si les \(n\) observations sont exactement alignées sur une droite de pente positive (négative). C’est-à-dire, s’il existe deux constantes \(a\) et \(b>0\) (\(b<0\)) telles que \(y_i=a+b x_i\) pour tout \(i=1, \ldots, n\).
Règle générale,
- Plus la corrélation est près de 1, plus les points auront tendance à être alignés autour d’une droite de pente positive. Par conséquent, plus la valeur de \(X\) augmente, plus celle de \(Y\) aura tendance à augmenter et vice-versa.
- Plus la corrélation est près de \(-1\), plus les points auront tendance à être alignés autour d’une droite de pente négative. Par conséquent, plus la valeur de \(X\) augmente, plus celle de \(Y\) aura tendance à diminuer et vice-versa.
- Lorsque la corrélation est presque nulle, les points n’auront pas tendance à être alignés autour d’une droite. Il est très important de noter que cela n’implique pas qu’il n’y a pas de relation entre les deux variables. Cela implique seulement qu’il n’y a pas de relation linéaire entre les deux variables.
2.3 Exemple de questionnaire
Le questionnaire suivant porte sur une étude dans un magasin. Pour les besoins d’une enquête, on a demandé à 200 consommateurs adultes de répondre aux questions suivantes par rapport à un certain type de magasin sur une échelle de 1 à 5, où
- pas important
- peu important
- moyennement important
- assez important
- très important
Pour vous, à quel point est-ce important
- que le magasin offre de bons prix tous les jours?
- que le magasin accepte les cartes de crédit majeures (Visa, Mastercard)?
- que le magasin offre des produits de qualité?
- que les vendeurs connaissent bien les produits?
- qu’il y ait des ventes spéciales régulièrement?
- que les marques connues soient disponibles?
- que le magasin ait sa propre carte de crédit?
- que le service soit rapide?
- qu’il y ait une vaste sélection de produits?
- que le magasin accepte le paiement par carte de débit?
- que le personnel soit courtois?
- que le magasin ait en stock les produits annoncés?
Une analyse factorielle cherchera à identifier automatiquement des groupes de variables qui sont fortement corrélées entre elles.
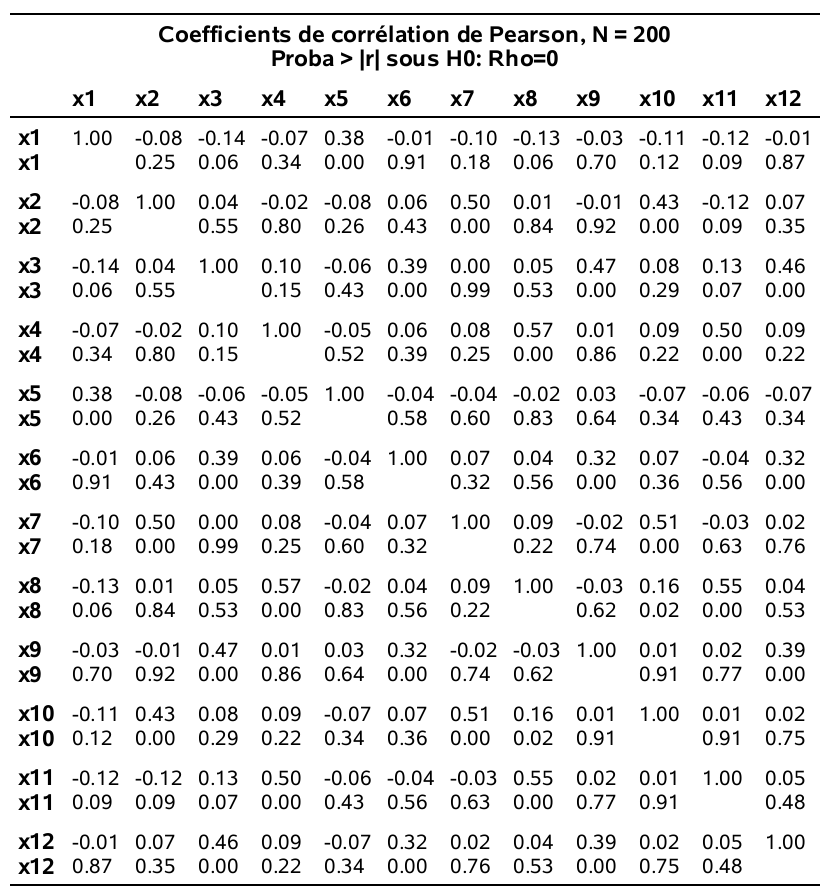
Les statistiques descriptives ainsi que la matrice des corrélations sont obtenues en exécutant les lignes suivantes:
proc corr data=multi.factor;
var x1-x12;
run;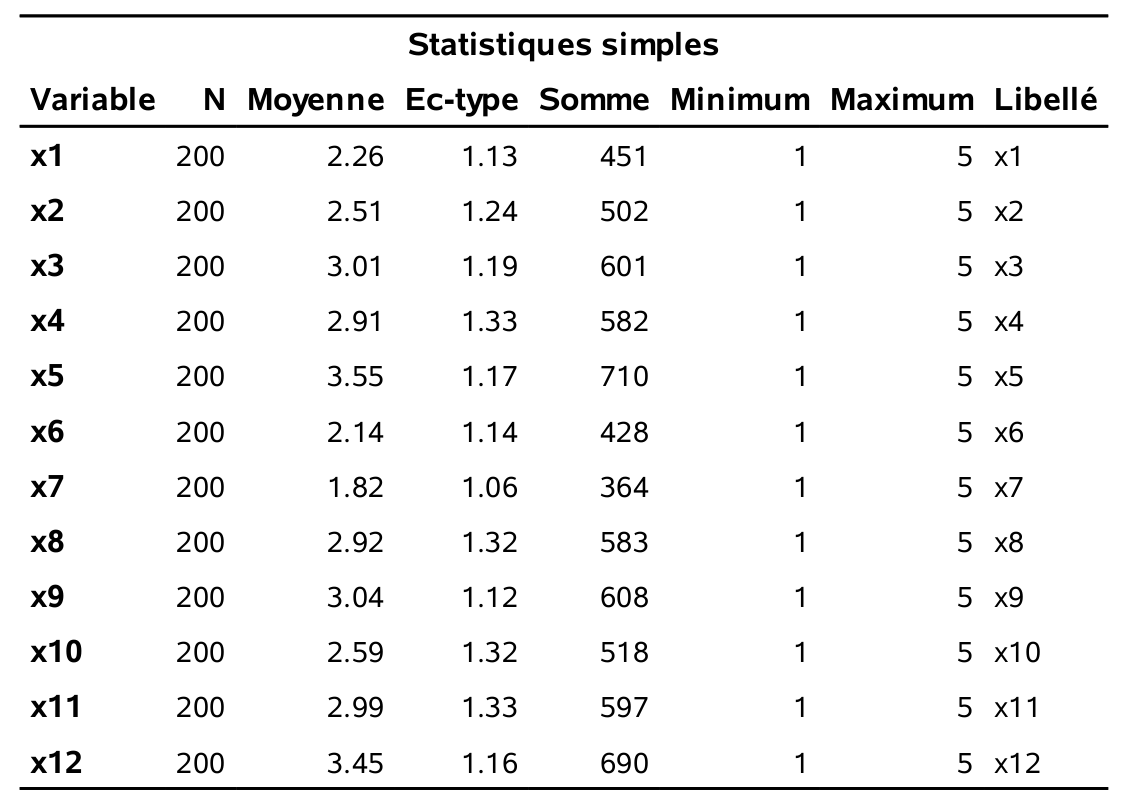
2.4 Description du modèle d’analyse factorielle
On dispose d’observations sur \(p\) variables \(X_1, \ldots, X_p\). Le modèle d’analyse factorielle fait l’hypothèse que ces variables dépendent linéairement d’un plus petit nombre \(m\) de variables aléatoires, \(F_1, \ldots, F_m\), appelées facteurs communs et de \(p\) termes d’erreurs (ou facteurs spécifiques) \(\varepsilon_1, \ldots, \varepsilon_p\), de moyenne \({\mathsf E}\left(\varepsilon_i\right)=0\) et de variance \({\mathsf{Var}}\left(\varepsilon_i\right)=\psi_i\) pour \(i=1, \ldots, p\). Les facteurs \(F_1, \ldots, F_m\) ont une moyenne nulle \({\mathsf E}\left(F_i\right)=0\), et une variance unitaire, \({\mathsf{Var}}\left(F_i\right)=1\) (\(i=1, \ldots, p\)) .
Spécifiquement, le modèle est \[\begin{align*} X_1 &= \mu_1 + \gamma_{11}F_1 + \gamma_{12} F_2 + \cdots + \gamma_{1m}F_m + \varepsilon_1\\ X_2 &= \mu_2 + \gamma_{21}F_1 + \gamma_{22} F_2 + \cdots + \gamma_{2m}F_m + \varepsilon_2\\ &\vdots \\ X_p &= \mu_p + \gamma_{p1}F_1 + \gamma_{p2} F_2 + \cdots + \gamma_{pm}F_m + \varepsilon_p, \end{align*}\] où \(\mu_i\) est l’espérance de la variable aléatoire \(X_i\) (\(i=1, \ldots, p\)) et où \(\gamma_{ij}\) est le chargement de la variable \(X_i\) sur le facteur \(F_j\) (\(i=1, \ldots, p\); \(j=1, \ldots, m\)).
Les espérances (\(\mu_i\)), les chargements (\(\gamma_{ij}\)) et les variances (\(\psi_i\)) sont des quantités fixes, mais inconnues, tandis que les facteurs communs (\(F_i\)) et les aléas (\(\varepsilon_i\)) sont des variables aléatoires non observables; on suppose que les aléas ne sont pas corrélées aux facteurs \(F\) et entre elles.
Le modèle d’analyse factorielle est un modèle pour la matrice de covariance/corrélation des variables explicatives \(X_1, \ldots, X_p\), avec \(\mathsf{Va}(X_j) = \sum_{l=1}^k \gamma_{jl}^2 + \psi_j\). On appelle communalité le terme \(h_j = \sum_{l=1}^k \gamma_{jl}^2\), qui représente la proportion de variance totale de \(X_j\) due à la corrélation entre les facteurs. Le terme \(\psi_j\) est connu sous le vocable unicité.
De plus, si les variables ont été préalablement standardisées de telle sorte que \({\mathsf E}\left(X_i\right)=0\) et \({\mathsf{Var}}\left(X_i\right)=1\) (note: ceci revient à utiliser la matrice de corrélation des observations dans l’analyse ce qui est fait par défaut dans SAS), alors \({\mathsf{Cor}}\left(X_i, F_j\right)=\gamma_{ij}\), c’est-à-dire, le chargement de la variable \(X_i\) sur le chargement \(F_j\) est le coefficient de corrélation entre cette variable et ce facteur.
Sans aucune contrainte sur le modèle, la matrice de covariance de \(X_1, \ldots, X_p\) possède \(p(p+1)/2\) paramètres, soit \(p\) variances et \(p(p-1)/2\) termes de corrélation. Avec le modèle d’analyse factorielle, on suppose que l’on peut décrire cette structure en utilisant seulement \(p(m+1) - m(m-1)/2\) paramètres (\(p\) variances spécifiques et \(pm\) chargements, moins les contraintes de diagonalisation). Par exemple, avec \(p=50\) variables et \(m=6\) facteurs, on essaie de décrire la structure de covariance à l’aide de 350 paramètres au lieu de 1275.
Il existe plusieurs méthodes pour extraire les facteurs, c’est-à-dire pour estimer les paramètres du modèle (les \(\psi_i\) et les \(\gamma_{ij}\)). Nous allons discuter de deux d’entre elles: la méthode du maximum de vraisemblance et la méthode des composantes principales. L’avantage de l’estimation par maximum de vraisemblance est qu’elle permet l’utilisation de critères d’information et de statistiques de tests pour guider le choix du nombre de facteurs, en supposant toutefois la normalité des facteurs et des aléas. L’estimation des paramètres requiert une optimisation numérique qui peut être délicate selon les cas de figure et qui mène parfois à des solutions paradoxales: un cas dit de quasi-Heywood survient quand \(h_j=1\) pour une variable \(j\), (on parle de cas de Heywood si \(h_j > 1\)). Si on modélise des variables explicatives centrées réduites, \(\mathsf{Va}(X_j)=1\), d’où un problème d’interprétation car le terme \(\psi_j\) serait nul (cas de quasi-Heywood) ou négatif (cas de Heywood) alors même que ce terme représente la variance du \(j\)e aléa. Les cas de quasi-Heywood ont plusieurs causes, lesquelles sont listées dans la documentation SAS. Souvent, c’est dû à l’utilisation d’un trop petit ou trop grand nombre de facteurs ou une taille d’échantillon trop petite, etc. Cela complique l’interprétation et nous amène à questionner la validité du modèle d’analyse factorielle comme simplification de la structure de covariance.
2.4.1 Rotation des facteurs
Dans le modèle d’analyse factorielle, on peut montrer que, lorsqu’il y a deux facteurs ou plus, il existe plusieurs configurations de facteurs qui donnent la même structure de covariance. En fait, les chargements peuvent seulement être déterminés à une transformation orthogonale près (note: une transformation orthogonale est une transformation qui préserve le produit scalaire; elle préserve ainsi toutes les distances et les angles entre deux vecteurs). Si les chargements provenant d’une méthode d’extraction des facteurs ne sont pas uniques, la matrice de corrélation estimée par le modèle est par contre unique.
Il existe plusieurs techniques de rotation de facteurs. Le but de ces techniques est d’essayer de trouver une solution qui fera en sorte que les facteurs seront facilement interprétables. La méthode la plus utilisée est la méthode varimax: elle produit une configuration de chargement en maximisant la variance de la somme des carrés des chargements pour les \(m\) facteurs. La méthode varimax tend à produire une configuration de facteurs tel que les chargements de chaque variable sont dispersés (des chargements élevés positifs ou négatifs et d’autres presque nuls).
Je vous suggère de toujours tenter d’interpréter la solution avec une rotation varimax. Si ce n’est pas suffisamment clair, il existe d’autres méthodes de rotation dont certaines (les rotations de type oblique) permettent la présence de corrélation entre les facteurs.
2.5 Estimation des facteurs
Les chargements estimés pour la solution à quatre facteurs, suite à la rotation varimax, sont obtenus avec le code SAS suivant:
proc factor data=multi.factor
method=ml rotate=varimax nfact=4
maxiter=500 flag=.3 hey;
var x1-x12;
run;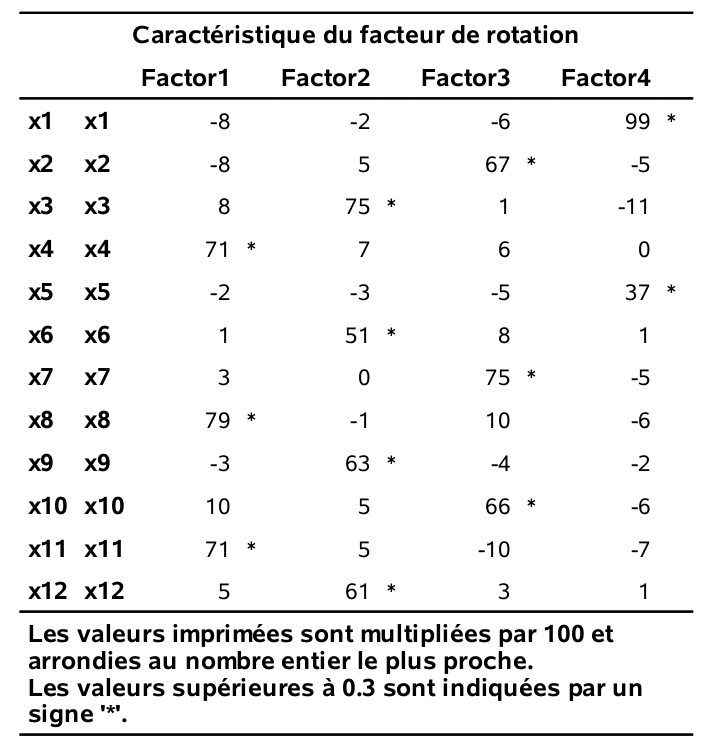
En général, on associe une variable à un groupe (facteur) si son chargement est supérieur à 0, 3 (en valeur absolue), ce qui donne
- Facteur 1: \(X_4\), \(X_8\) et \(X_{11}\)
- Facteur 2: \(X_3\), \(X_6\), \(X_9\) et \(X_{12}\)
- Facteur 3: \(X_2\), \(X_7\) et \(X_{10}\)
- Facteur 4: \(X_1\) et \(X_5\).
Ces facteurs sont interprétables:
- Le facteur 1 représente l’importance accordée au service.
- Le facteur 2 représente l’importance accordée aux produits.
- Le facteur 3 représente l’importance accordée à la facilité de paiement.
- Le facteur 4 représente l’importance accordée aux prix.
Dans cet exemple, les choses se sont bien passées et le nombre de facteurs que nous avons spécifié (4) semble être adéquat, mais ce n’est pas toujours aussi évident. Il est utile d’avoir des outils pour guider le choix du nombre de facteurs.
2.6 Choix du nombre de facteurs
Il existe différentes méthodes pour se guider dans le nombre de facteurs, \(m\), à utiliser. Cependant, le point important à retenir est que, peu importe le nombre choisi, il faut que les facteurs soient interprétables. Par conséquent, les méthodes qui suivent ne devraient servir que de guide et non pas être suivies aveuglément. La méthode du maximum de vraisemblance que nous avons utilisée dans l’exemple possède l’avantage de fournir trois critères pour choisir le nombre de facteurs appropriés. Ces critères sont:
- AIC (critère d’information d’Akaike)
- BIC (critère d’information bayésien de Schwarz)
- Le test du rapport de vraisemblance pour l’hypothèse nulle que le modèle de corrélation décrit le modèle factoriel avec \(m\) facteurs est adéquat, contre l’alternative qu’il n’est pas adéquat.
Les critères d’information servent à la sélection de modèles; ils seront traités plus en détail dans les chapitres qui suivent. Pour l’instant, il est suffisant de savoir que le modèle avec la valeur du critère AIC (ou BIC) la plus petite est considéré le « meilleur » (selon ce critère).
Les sorties suivantes proviennent du même programme SAS et correspondent au modèle factoriel avec quatre facteurs estimé par maximum de vraisemblance.
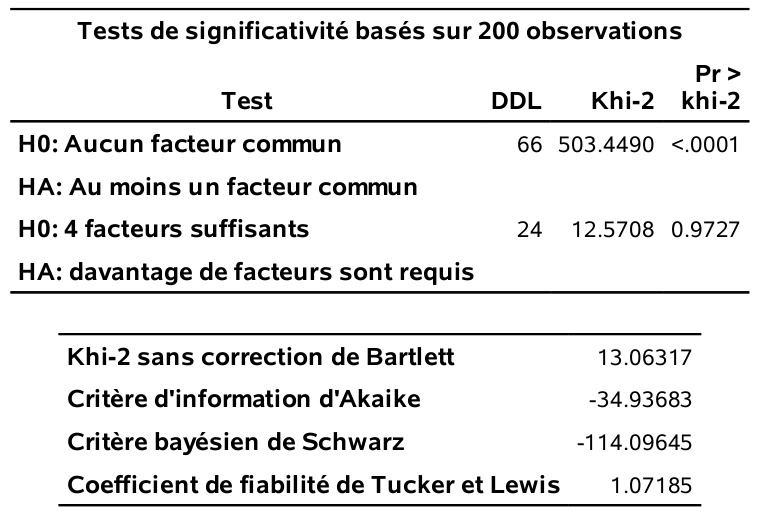
Pour choisir le nombre de facteurs avec les critères d’information, il faut ajuster le modèle en faisant varier le nombre de facteurs (option nfact) et extraire la valeur numérique correspondante. Si nfact dépasse le nombre de valeurs propres estimées supérieures à \(1\) (critère mineigen), la spécification nfact sera ignorée à moins que vous ne spécifiez un autre critère, par exemple priors=one. Cette option revient à démarrer l’algorithme d’optimisation avec la contrainte \(\sum_{l=1}^k \gamma_{jl}^2=1, \psi_j=0\). En revanche, méfiez-vous: cela mène à des maximums locaux, n’employez l’option que si nécessaire.
Il faut garder en tête que l’estimation par maximum de vraisemblance du modèle d’analyse factorielle est très sensible à l’initialisation: on peut aussi parfois obtenir des valeurs différentes selon les logiciels. Cette fragilité, couplée à la haute fréquence de cas de Heywood (la solution numérique donne des communalités qui excèdent un, or ces dernières représentent le carré d’un coefficient de corrélation linéaire, ce qui rend l’interprétation du modèle caduque), fait en sorte que je préfère utiliser la méthode des composantes principales pour l’estimation.
Le tableau 2.1 présente les valeurs estimées des critères d’information et des valeurs-\(p\) pour le test du rapport de vraisemblance pour cinq modèles. Le critère AIC suggère quatre facteurs, tandis que les deux autres critères, BIC et test du rapport de vraisemblance, suggèrent plutôt trois facteurs.
| m | AIC | BIC | valeur-p |
|---|---|---|---|
| 1 | 228.0 | 49.9 | <0.001 |
| 2 | 99.5 | -42.3 | <0.001 |
| 3 | -20.5 | -129.3 | 0.096 |
| 4 | -34.9 | -114.1 | 0.973 |
| 5 | -24.8 | -77.6 | 0.975 |
On peut considérer le modèle avec trois facteurs: les chargements (après rotation varimax) sont données dans la figure 2.2.
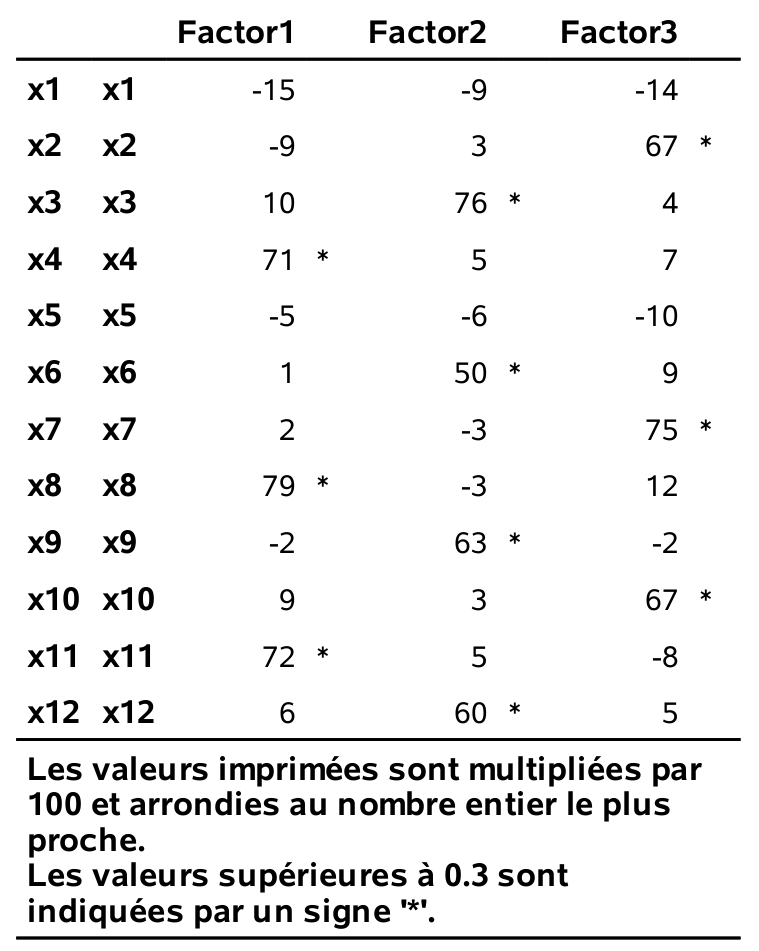
Figure 2.2: Estimés des chargements pour trois facteurs avec rotation varimax
Cette solution récupère les trois facteurs service, produits et paiement de la solution précédente à quatre facteurs. Le facteur prix (qui était formé de \(X_1\) et \(X_5\)) n’est plus présent: que faire avec ce dernier? Cela dépend du but de l’analyse et nous y reviendrons plus tard.
Pour terminer cette section, voici la description de deux autres critères classiques pour choisir le nombre de facteurs si l’on ajuste le modèle avec la méthodes des composantes principales (plutôt qu’avec le maximum de vraisemblance). Ces deux critères sont:
- Critère de Kaiser, un critère basé sur les valeurs propres. Avec une analyse en composantes principales basée sur la matrice des corrélations, la valeur propre associée à un facteur représente la partie de la variance totale qui est expliquée par ce facteur. Chaque variable compte pour un dans la variance totale. Le nombre de facteurs choisis est le nombre de valeurs propres supérieures à 1. L’idée est de garder seulement les facteurs qui expliquent plus de variance qu’une variable individuelle.
- le diagramme d’éboulis: un graphique des valeurs propres ordonnées de la plus grande à la plus petite en fonction de \(1, \ldots, p\). Habituellement, ce graphe prendra la forme d’une chute assez importante suivie d’une stabilisation des valeurs propres. Avec ce critère, le nombre de facteurs est déterminé par le nombre de valeurs propres avant le début du coude où il a stabilisation apparente. L’idée est de choisir l’endroit où l’ajout d’un facteur supplémentaire n’apporte qu’un gain marginal faible. Ce critère est par contre subjectif et dépend de l’analyste. En ajoutant
screecomme option àproc factor, on obtient le diagramme d’éboulis mais il est facile de le créer manuellement et le résultat est esthétiquement plus réussi.
Les sorties qui suivent proviennent du programme:
proc factor data=multi.factor method=principal
scree rotate=varimax flag=.3;
ods output Eigenvalues=eigen;
var x1-x12;
run;
proc sgplot data=eigen;
scatter x=number y=eigenvalue;
yaxis label="valeurs propres";
xaxis label='nombre';
run;Cette fois-ci, c’est la méthode des composantes principales qui est utilisée; cette dernière consiste à estimer les chargements en utilisant les \(m\) premières valeurs propres et vecteurs propres de la matrice de corrélation. En ne spécifiant pas l’option nfact, SAS choisit le nombre de facteurs en utilisant par défaut le critère de Kaiser (valeurs propres supérieures à 1). Quatre facteurs sont retenus, tel qu’indiqué par la sortie au bas du tableau 2.3. Pour le diagramme d’éboulis de la figure 2.4, le choix est assez subjectif: il semble raisonnable de choisir trois ou quatre facteurs.
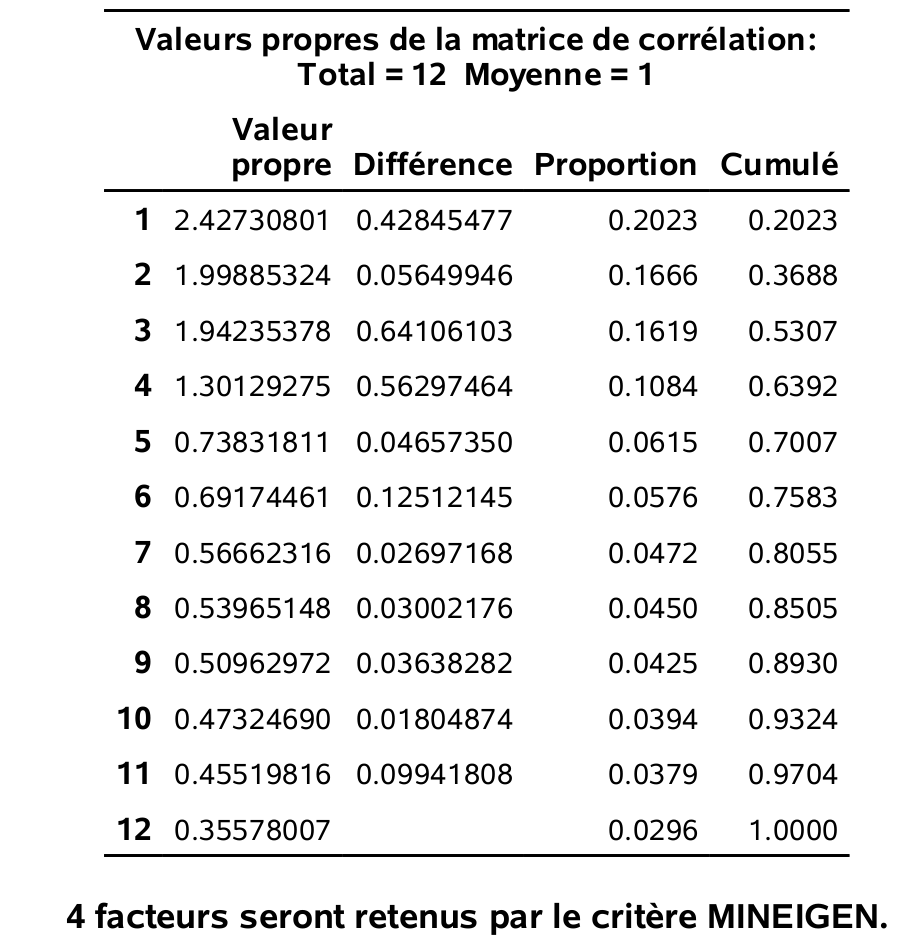
Figure 2.3: Valeurs propres et proportion de variance
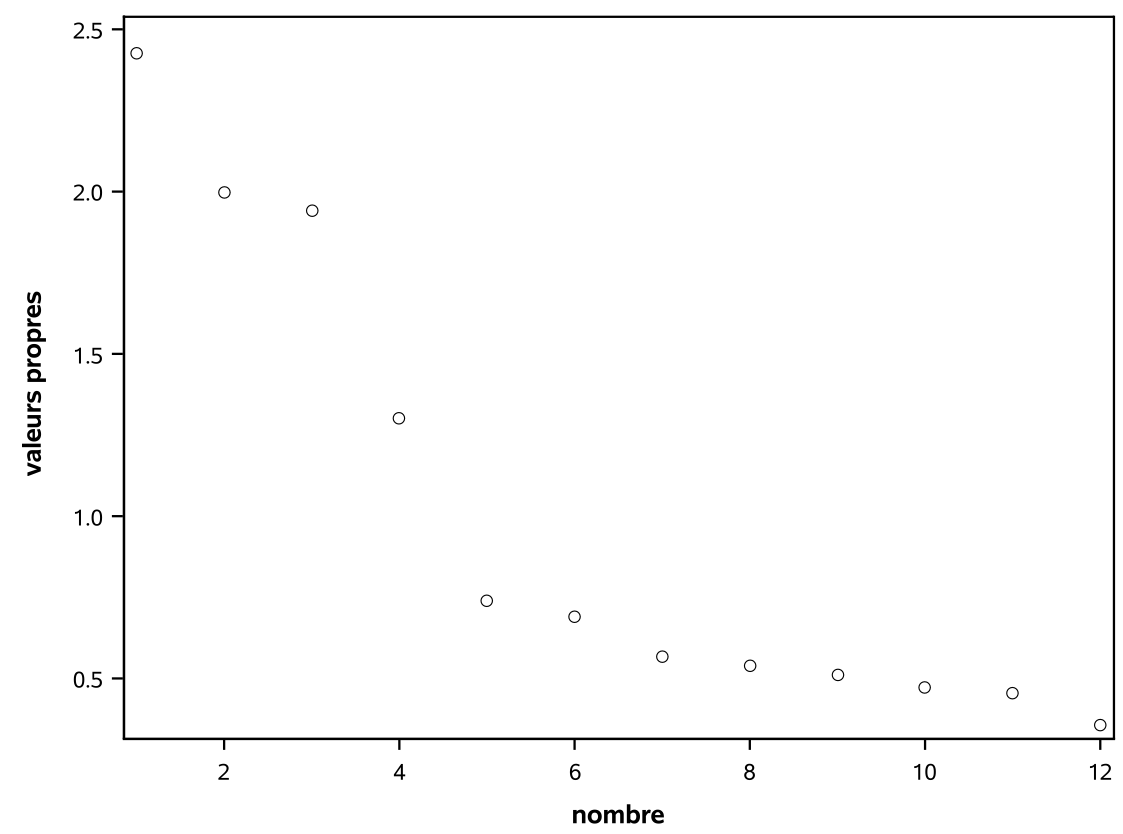
Figure 2.4: Diagramme d’éboulis
On suggère d’utiliser de facto les trois critères découlant de l’utilisation de la vraisemblance et de déterminer le nombre de facteurs à extraire selon différents critères avant d’examiner les modèles avec ce nombre de facteurs et ceux avec un facteur de moins ou de plus. Au final, le plus important est de pouvoir interpréter raisonnablement les facteurs et donc le modèle retenu est souvent choisi selon le critère Wow!. On veut dire par là que la configuration de facteurs choisie est compréhensible.
2.7 Construction d’échelles à partir des facteurs
Si le seul but de l’analyse factorielle est de comprendre la structure de corrélation entre les variables, alors se limiter à l’interprétation des facteurs est suffisant.
Si par contre, le but est de réduire le nombre de variables pour pouvoir par la suite procéder à d’autres analyses statistiques, l’analyse factorielle peut alors servir de guide pour construire de nouvelles variables (échelles). En supposant que l’analyse factorielle a produit des facteurs qui sont interprétables et satisfaisants, la méthode de construction d’échelles la plus couramment utilisée consiste à construire \(m\) nouvelles variables, une par facteur. Pour un facteur donné, la nouvelle variable est simplement la moyenne des variables ayant des chargements élevés sur ce facteur (positifs ou négatifs, mais de même signe). Une autre méthode, les scores factoriels, sera présentée plus loin.
Lorsqu’on construit une échelle, il est important d’examiner sa cohérence interne. Ceci peut être fait à l’aide du coefficient alpha de Cronbach. Ce coefficient mesure à quel point chaque variable faisant partie d’une échelle est corrélée avec le total de toutes les variables pour cette échelle. Plus le coefficient est élevé, plus les variables ont tendance à être corrélées entre elles. L’alpha de Cronbach est \[\begin{align*} \alpha=\frac{k}{k-1} \frac{S^2-\sum_{i=1}^k S_i^2}{S^2}, \end{align*}\] où \(k\) est le nombre de variables dans l’échelle, \(S^2\) est la variance empirique de la somme des variables et \(S_i^2\) est la variance empirique de la \(i\)e variable. En pratique, on voudra que ce coefficient soit au moins égal à 0, 6 pour être satisfait de la cohérence interne de l’échelle.
Avec SAS, la procédure corr permet de calculer \(\alpha\).
/* pour le facteur service */
proc corr data=multi.factor alpha;
var x4 x8 x11;
run;
/* pour le facteur produits */
proc corr data=multi.factor alpha;
var x3 x6 x9 x12;
run;
/* pour le facteur paiement */
proc corr data=multi.factor alpha;
var x2 x7 x10;
run;
/* pour le facteur prix */
proc corr data=multi.factor alpha;
var x1 x5;
run;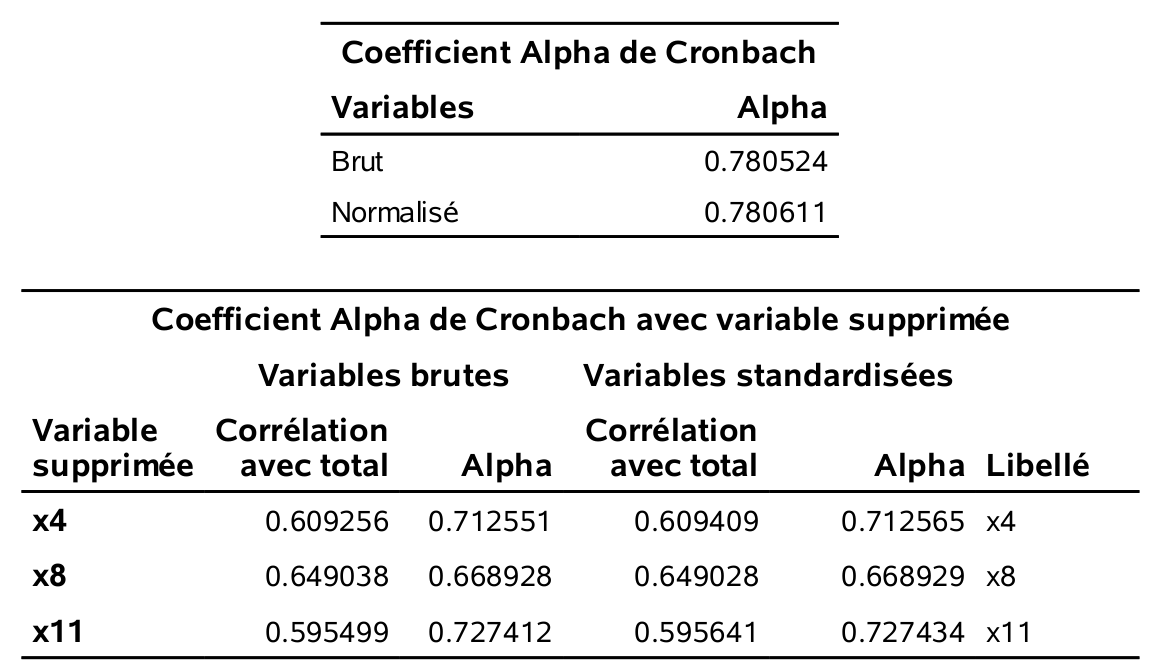
Figure 2.5: Alpha de Cronbach pour le facteur service.
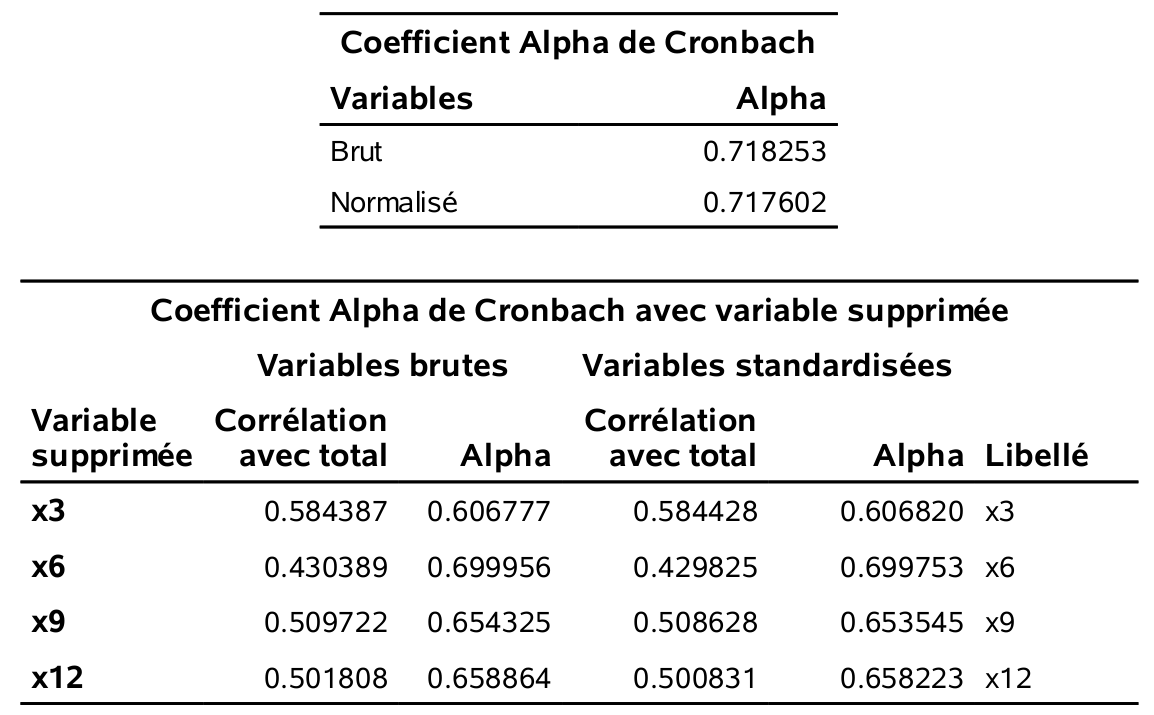
Figure 2.6: Alpha de Cronbach pour le facteur produits.
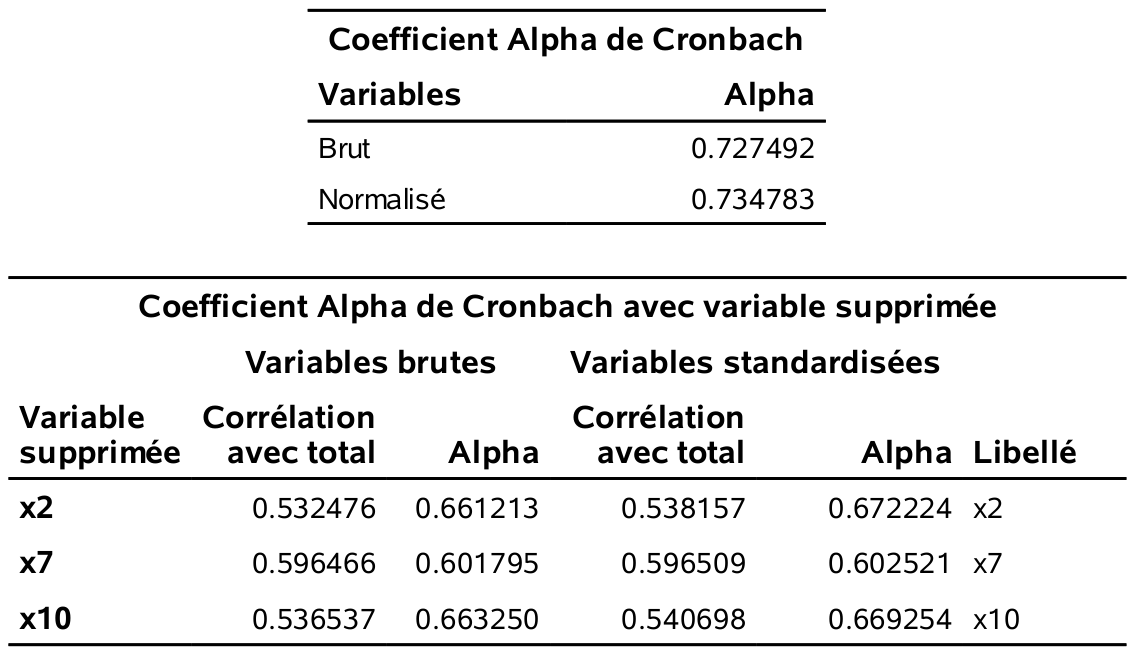
Figure 2.7: Alpha de Cronbach pour le facteur paiement.

Figure 2.8: Alpha de Cronbach pour le facteur prix.
Il faut utiliser le alpha brut. Ainsi, les alphas de Cronbach sont tous satisfaisants (plus grand que 0, 6) sauf pour le facteur prix (\(\alpha=0, 546\)). SAS fournit également la matrice des corrélations des variables de l’échelle ainsi que la valeur du alpha de Cronbach si on retirait une variable à la fois de l’échelle. Tout est donc cohérent. Les échelles provenant des facteurs service, produits et paiement, sont satisfaisantes. Ces facteurs sont identifiés à la fois dans la solution à quatre, mais aussi dans la solution à troisfacteurs. Le facteur prix est celui qui apparaît en plus dans la solution à quatre facteurs. Il a une interprétation claire, mais son faible alpha ferait en sorte qu’il serait discutable de travailler avec l’échelle prix dans d’autres analyses (du moins avec selon l’usage habituel du alpha).
2.8 Compléments d’information
2.8.1 Variables ordinales
Théoriquement, une analyse factorielle ne devrait être faite qu’avec des variables continues. Par contre, en pratique, on l’utilise souvent aussi avec des variables ordinales (comme pour l’exemple portant sur le questionnaire) et même avec des variables binaires (0-1).
Dans ce genre de situation, on peut aussi utiliser d’autres mesures d’associations au lieu du coefficient de corrélation linéaire. Par exemple, on peut utiliser la corrélation polychorique, qui est une mesure de corrélation entre deux variables ordinales. La corrélation tétrachorique correspond au cas spécial de deux variables binaires.
Ma suggestion est d’utiliser la corrélation linéaire ordinaire avec des variables ordinales (même binaires). Si les résultats ne sont pas satisfaisants, on peut alors essayer avec d’autres mesures d’associations.
On peut refaire l’analyse des données portant sur le magasin dans SAS en utilisant la corrélation polychorique calculées par la procédure corr et en passant la sortie à la procédure factor.
proc corr data=multi.factor polychoric out=poly_corr;
var x1-x12;
run;
proc factor data=poly_corr
method=ml rotate=varimax nfact=4
maxiter=500 flag=.3 hey;
var x1-x12;
run;Les chargements sont donnés dans la figure 2.9. Les facteurs obtenus sont les mêmes qu’en utilisant les corrélations linéaires.
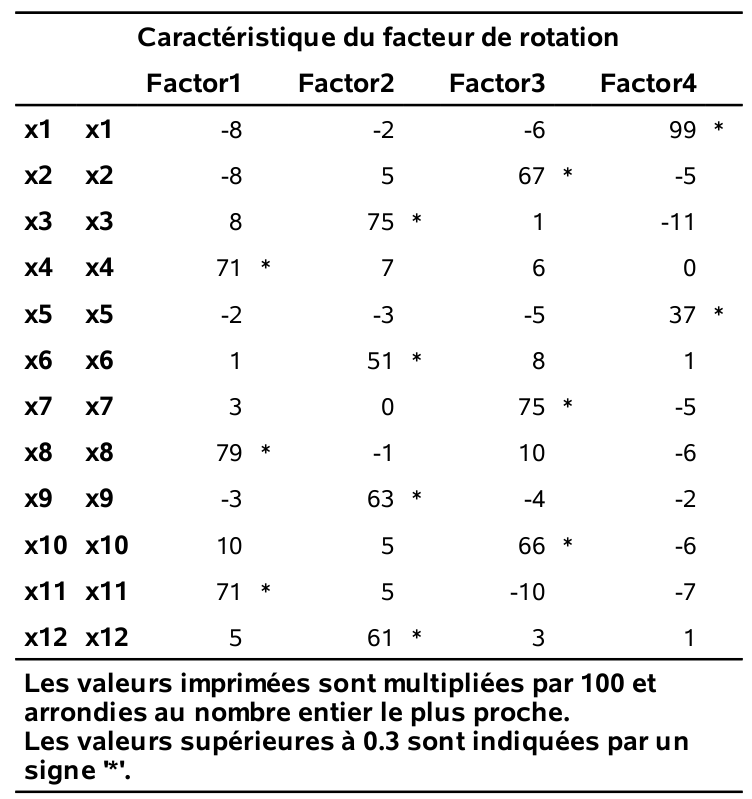
Figure 2.9: Chargements estimés pour la corrélation polychorique
2.8.2 Autres méthodes d’extractions de facteurs
Il n’y a pas de formule explicites pour l’estimation des paramètres avec la méthode du maximum de vraisemblance et un algorithme d’optimisation est nécessaire pour l’option des paramètres. Dans certains cas, l’algorithme peut terminer sans solution ou retourner un cas limite (où la variance est négative ou nulle). C’est le cas dans notre exemple avec quatre facteurs (solution de Heywood), bien que ce ne soit pas indiqué. La sortie SAS contient des informations sur la convergence de l’estimé: idéalement, on obtient la mention Critère de convergence respecté; autrement, essayez de varier le nombre. Un autre signe que l’algorithme n’a pas convergé est la présence de degrés de libertés négatifs pour le test du rapport de vraisemblance.
La méthode par les composantes principales (mentionnée lors de la présentation des valeurs propres et du diagramme d’éboulis a une solution explicite et peut donc dépanner si on n’arrive pas à obtenir le maximum de vraisemblance.
D’autres méthodes sont aussi disponibles dans SAS (voir la rubrique d’aide du logiciel) mais les deux méthodes mentionnées devraient être suffisantes pour la grande majorité des applications.
2.8.3 Autres méthodes de rotation des facteurs
Jusqu’à présent, nous avons utilisé la méthode de rotation orthogonale varimax. Il existe de nombreuses autres méthodes de rotations orthogonales telles, orthomax, quartimax, parsimax et equimax (voir la rubrique d’aide de SAS). Rappelez-vous que le modèle d’analyse factorielle de base suppose que les facteurs sont non corrélés. Les rotations de type obliques quant à elles permettent d’introduire de la corrélation entre les facteurs. Quelquefois, une telle rotation facilitera davantage l’interprétation des facteurs qu’une rotation orthogonale. SAS permet l’utilisation de plusieurs méthodes de rotation obliques qui sont documentées dans la rubrique d’aide. Notez qu’il faut être prudent lorsqu’on utilise une méthode de rotation oblique car il y aura trois matrices de chargements après rotation (coefficients de régression normalisés, corrélations semi-partielles ou corrélations). On suggère l’utilisation de la première, soit la représentation avec coefficients de régression normalisés. Il s’agit des coefficients de régression si on voulait prédire les variables à l’aide des facteurs. Ils indiquent donc à quel point chaque facteur est associé à chaque variable. Dans le cas d’une rotation orthogonale, ces trois matrices sont les mêmes et il s’agit de trois interprétations valides des chargements.
Le programme suivant fait une analyse factorielle avec quatre facteurs, mais en utilisant une rotation varimax oblique (option rotate=obvarimax).
proc factor data=multi.factor
maxiter=500 flag=.3 hey;
var x1-x12;
run;La matrice des corrélations entres facteurs est donnée dans la figure 2.10 et les chargements sont présentés dans la figure 2.11. On voit ici qu’on obtient les mêmes quatre facteurs qu’avec une rotation varimax orthogonale.

Figure 2.10: Corrélation interfacteurs pour rotation varimax oblique
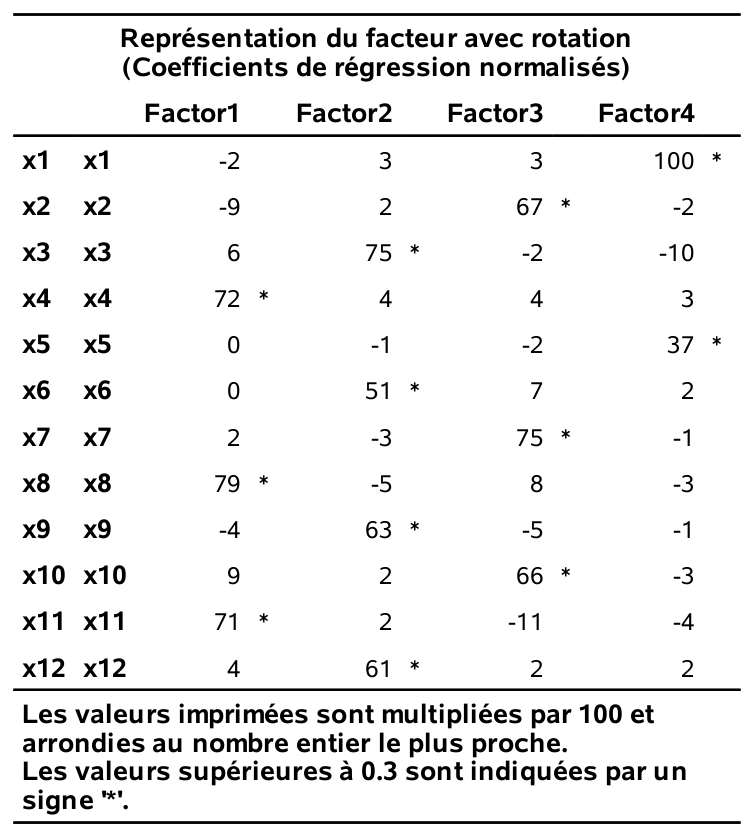
Figure 2.11: Chargements avec rotation oblique varimax
2.8.4 Scores factoriels
Avec les données de l’exemple, en nous basant sur les résultats de l’analyse factorielle, nous avons créé quatre nouvelles échelles (une par facteur) que l’on peut calculer pour chaque individu:
- service = \((X_4+X_8+X_{11})/3\),
- produit = \((X_3+X_6+X_9+X_{12})/4\),
- paiement = \((X_2+X_7+X_{10})/3\),
- prix = \((X_1+X_5)/2\).
Par exemple, la variable prix peut donc être vu comme une combinaison linéaire des 12 variables où seulement \(X_1\) et \(X_5\) reçoivent un poids (égal) différent de zéro. Une autre façon de créer de nouvelles variables consiste à calculer des scores factoriels (un pour chaque facteur) pour chaque individu. Par exemple, pour un individu \(i\) donné, le score factoriel pour le facteur \(k\) peut être prédit à l’aide de la formule \[\begin{align*} \hat{F}_{ik} &= \widehat{\boldsymbol{\Gamma}}^{\top}\mathbf{R}^{-1}\boldsymbol{z}\\&= \widehat{\beta}_{1, k} z_{i, 1} + \cdots + \widehat{\beta}_{12, k}z_{i, 12}, \end{align*}\] où \(z_{i, 1}, \ldots, z_{i, 12}\) sont les valeurs centrées et réduites des observations correspondant à l’individu et où \(\widehat{\beta}_{1, k}, \ldots, \widehat{\beta}_{12, k}\) sont des coefficients estimés à partir des chargements \(\gamma_{ij}\) (après rotation) et de la matrice de corrélation des variables \(\mathbf{R}\), avec \(\widehat{\beta}_{i, k}=\sum_{j=1}^p \widehat{\gamma}_{kj}r_{jk}\).
Ainsi, chacune des 12 variables originales contribue au calcul du score factoriel. Les variables ayant des chargements plus élevés sur ce facteur auront tendance à avoir des poids (\(\widehat{\gamma}\)) plus élevés. Par contre, les scores factoriels ne sont pas uniques car ils dépendent des chargements utilisés (et donc à la fois de la méthode d’estimation et de la méthode de rotation). On peut également utiliser les scores factoriels au lieu des 12 variables originales dans des analyses subséquentes. Il est suggéré d’utiliser les nouvelles variables (échelles) obtenues en faisant les moyennes des variables identifiées comme faisant partie de chaque facteur pour les raisons suivantes:
- l’interprétation des scores factoriels est moins claire (chaque facteur dépend de toutes les variables)
- les scores factoriels ne sont pas uniques (ils dépendent de la méthode d’estimation et de rotation).
- les coefficients servant au calcul seront différents d’une étude à l’autre.
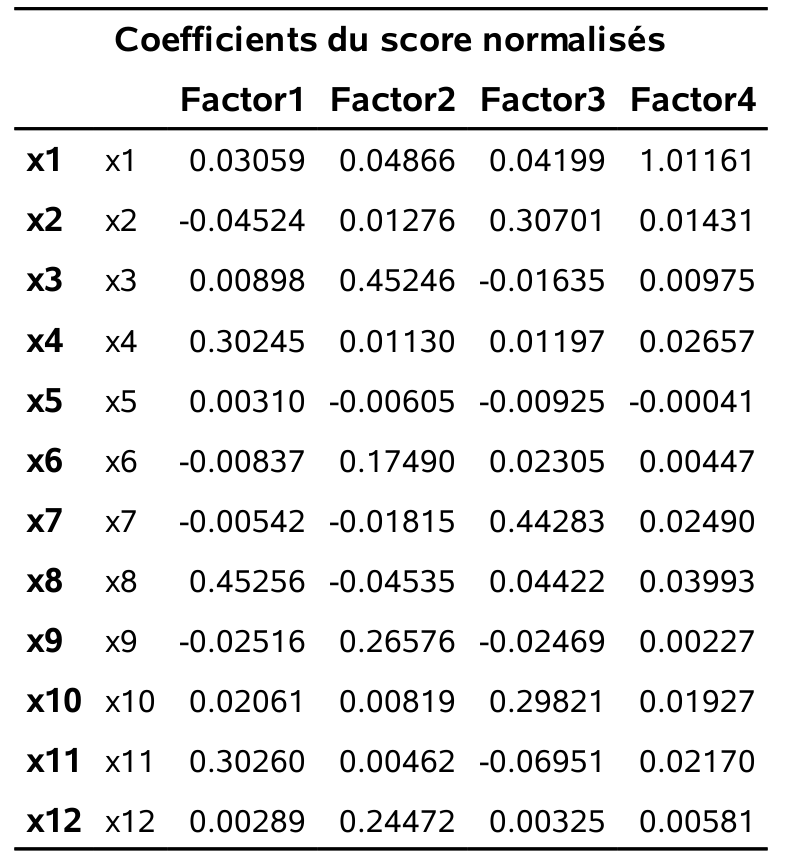
Figure 2.12: Coefficients du score normalisés
Pour obtenir les scores avec SAS, il suffit d’insérer l’option score à la procédure factor. L’option out=... permet de créer un fichier de données SAS qui contient la valeur des \(m\) scores pour chaque individu. Les scores factoriels pour l’exemples sont rapportés dans la figure 2.12. On remarque que:
- pour le premier facteur, trois variables ont des poids importants (\(X_4\), \(X_8\) et \(X_{11}\)). Il s’agit donc d’un facteur très proche du facteur service.
- pour le deuxième facteur, les variables \(X_3\), \(X_6\), \(X_9\) et \(X_{12}\) ont des poids importants. Il s’agit donc d’un facteur très proche du facteur produits.
- pour le troisième facteur, les variables \(X_2\), \(X_7\), \(X_{10}\) ont des poids importants. Il s’agit donc d’un facteur très proche du facteur paiement.
- pour le quatrième facteur, seule la variable \(X_1\) a un poids important. On aurait pu s’attendre à ce que ce soit également le cas pour \(X_5\), en lien avec le facteur prix — ce facteur était moins clair selon le alpha de Cronbach.
Les corrélations entre les échelles (construites avec les moyennes) et les scores factoriels sont données dans la figure 2.13. On remarque la forte corrélation entre le score factoriel et les échelles construites avec les moyennes pour les facteurs service, produits et paiement. Cela veut dire qu’utiliser les échelles ou les scores factoriels ne devrait pas faire de différence dans des analyses subséquentes. Par contre, cette corrélation est plus faible (0.82) pour le facteur prix.
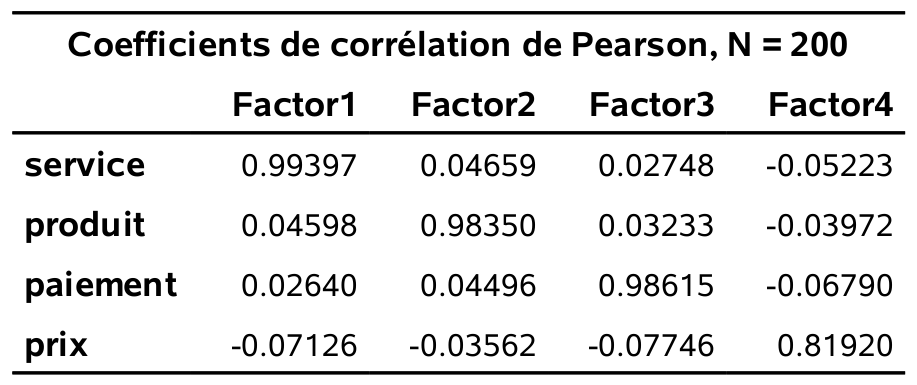
Figure 2.13: Corrélation entre scores et échelles