8 Données manquantes
Il arrive fréquemment d’avoir des valeurs manquantes dans notre échantillon. Ces valeurs peuvent être manquantes pour diverses raisons. Si on prélève nous-mêmes nos données, un répondant peut refuser de répondre à certaines questions. Si on acquiert nos données d’une source externe, les valeurs de certaines variables peuvent être manquantes directement dans le fichier obtenu. Si on ne prend pas en compte le méchanisme générant les valeurs manquantes, ces dernières peuvent également biaiser nos analyses. Le but de ce chapitre est de faire un bref survol de ce sujet.
8.1 Principes de base
Soit \(X\) une variable pour laquelle des données sont manquantes. Voici la définition de trois processus de génération de données manquantes.
- Les données manquantes de \(X\) sont dites manquantes de façon complètement aléatoire (MCAR, de l’anglais missing completely at random) si la probabilité que la valeur de \(X\) soit manquante ne dépend ni de la valeur de \(X\) (qui n’est pas observée), ni des valeurs des autres variables.
Le fait qu’une variable est manquante peut être relié au fait qu’une autre soit manquante. Des gens peuvent refuser systématiquement de répondre à deux questions dans un sondage. Dans ce cas, si la probabilité qu’une personne ne réponde pas ne dépend pas des valeurs de ces variables (et de toutes les autres), nous sommes encore dans le cas MCAR. Si par contre, la probabilité que les gens ne répondent pas à une question sur leur revenu augmente avec la valeur de ce revenu, alors nous ne sommes plus dans le cas MCAR.
Le cas MCAR peut se présenter par exemple si des questionnaires, ou des pages ont été égarés ou détruits par inadvertance (effacées du disque rigide, etc.) Si les questionnaires manquants constituent un sous-ensemble choisi au hasard de tous les questionnaires, alors le processus est MCAR. L’hypothèse que les données manquantes sont complètement aléatoires est en général considérée comme trop restrictive.
- Les données manquantes de \(X\) sont dites données manquantes de façon aléatoire (MAR, de l’anglais missing at random) si la probabilité que la valeur de \(X\) soit manquante ne dépend pas de la valeur de \(X\) (qui n’est pas observée) une fois qu’on a contrôlé pour les autres variables.
Il est possible par exemple que les femmes refusent plus souvent que les hommes de répondre à une question, par exemple de donner leur âge (et donc, le processus n’est pas MCAR). Si pour les femmes et les hommes, la probabilité que \(X\) est manquante ne dépend pas de la valeur de \(X\), alors le processus est MAR. Les probabilités d’avoir une valeur manquante sont différentes pour les hommes et les femmes mais cette probabilité ne dépend pas de la valeur de \(X\) elle-même. L’hypothèse MAR est donc plus faible que l’hypothèse MCAR.
- Les données manquantes de \(X\) sont dites manquantes de façon non-aléatoire (MNAR, de l’anglais missing not at random) si la probabilité que la valeur de \(X\) soit manquante dépend de la valeur de \(X\) elle-même.
Par exemple, les gens qui ont un revenu élevé pourraient avoir plus de réticences à répondre à une question sur leur revenu. Un autre exemple est si une personne transgenre ne répond pas à la question genre (si on offre seulement deux choix, homme/femme) et aucune autre question ne se rattache au genre ou à l’identité sexuelle. La méthode de traitement que nous allons voir dans ce chapitre, l’imputation multiple, est très générale et est valide dans le cas MAR (et donc aussi dans le cas MCAR). Le cas MNAR est beaucoup plus difficile à traiter et ne sera pas considéré ici.
Il n’est pas possible de tester l’hypothèse que le données sont manquantes de façon aléatoire ou complètement aléatoire; ce postulat doit donc être déterminé à partir du contexte et des variables auxiliaires disponibles.
8.2 Méthodes d’imputation
Il est important de noter que, dans bien des cas, les données manquantes ont une valeur logique: un client qui n’a pas de carte de crédit a un solde de 0! Tous ces cas devraient être traités en amon, d’où l’importance des validations d’usage et du nettoyage préliminaire de la base de données.
8.2.1 Cas complets
La première idée naïve pour une analyse est de retirer les observations avec données manquantes pour conserver les cas complets (listwise deletion, ou complete case analysis).
Cette méthode consiste à garder seulement les observations qui n’ont aucune valeur manquante pour les variables utilisées dans l’analyse demandée. Dès qu’une variable est manquante, on enlève le sujet au complet. C’est la méthode utilisée par défaut dans la plupart des logiciels, dont R.
- Si le processus est MCAR, cette méthode est valide car l’échantillon utilisé est vraiment un sous-échantillon aléatoire de l’échantillon original. Par contre, ce n’est pas nécessairement la meilleure solution car on perd de la précision en utilisant moins d’observations.
- Si le processus est seulement MAR ou MNAR, cette méthode produit généralement des estimations biaisées des paramètres.
En général, l’approche des cas complet est la première étape d’une analyse afin d’obtenir des estimés initiaux que nous corrigerons pas d’autre méthode. Elle n’est vraiment utile que si la proportion d’observations manquantes est très faible et le processus est MCAR. Évidemment, la présence de valeurs manquantes mène à une diminution de la précision des estimateurs (caractérisée par une augmentation des erreurs-types) et à une plus faible puissance pour les tests d’hypothèse et donc ignorer l’information partielle (si seulement certaines valeurs des variables explicatives sont manquantes) est sous-optimal.
8.2.2 Imputation simple
L’imputation consiste à remplacer les valeurs manquantes pour boucher le trous. Pour paraphraser Dempster et Rubin (1983),
Le concept d’imputation est à la fois séduisant et dangereux.
Avec l’imputation simple, on remplace les valeurs manquantes par des ersatz raisonnables. Par exemple, on peut remplacer les valeurs manquantes d’une variable par la moyenne de cette variable dans notre échantillon. On peut aussi ajuster un modèle de régression avec cette variable comme variable dépendante et d’autres variables explicatives comme variables indépendantes et utiliser les valeurs prédites comme remplacement. Une fois que les valeurs manquantes ont été remplacées, on fait l’analyse avec toutes les observations.
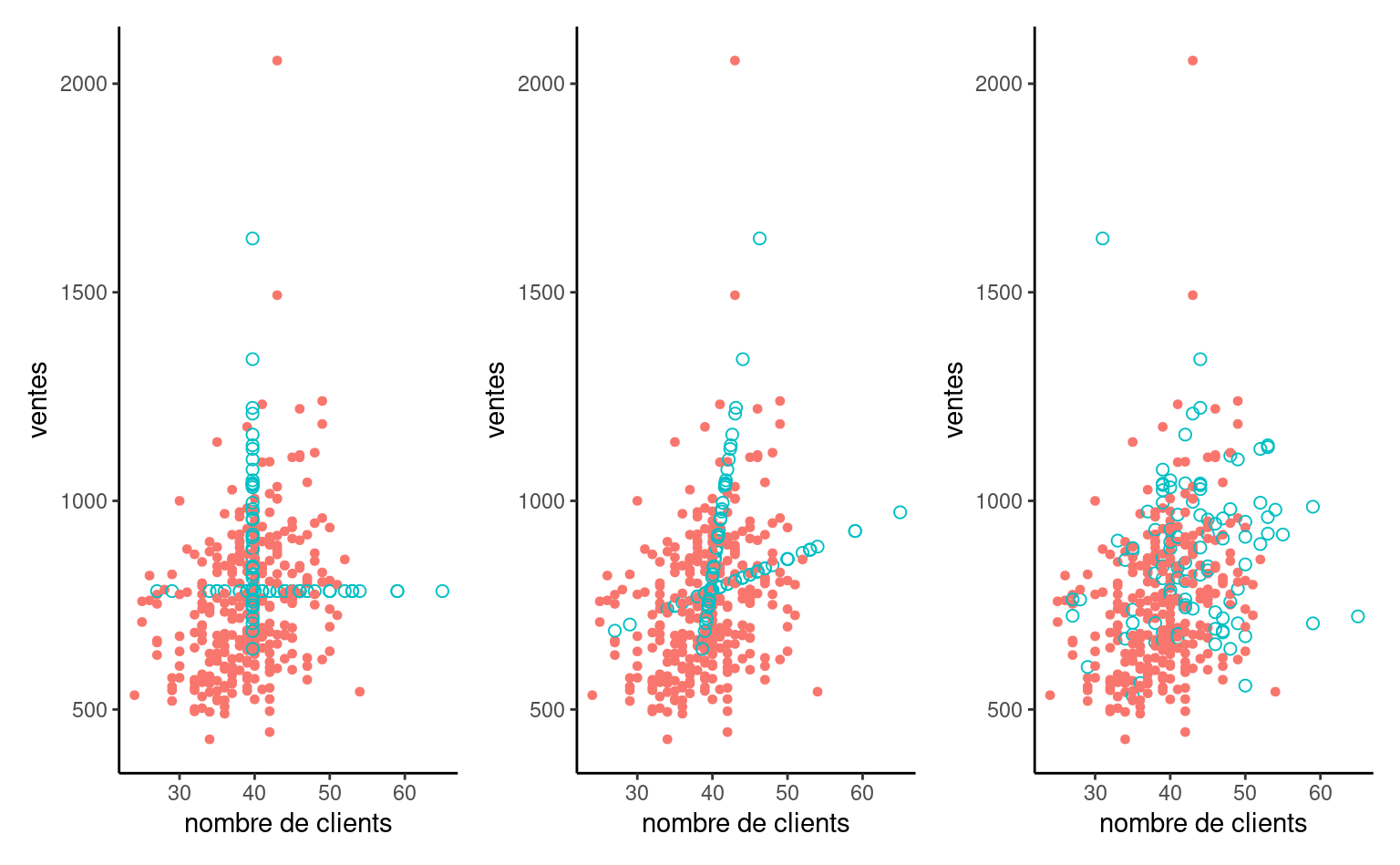
L’imputation par le mode ou la moyenne n’est pas recommandée parce qu’elle dilue la corrélation entre les variables explicatives et elle réduit la variabilité. Les modèles de régression mènent également à une-sous estimation de l’incertitude en raison cette fois-ci de l’augmentation de la corrélation, ce qui augmente mécaniquement la significativité des tests, contrairement à l’imputation aléatoire (droite). Le Figure 8.1 montre clairement cet état de fait.
En quoi constitue l’imputation aléatoire recommandée ci-dessus? Considérons le cas d’une régression logistique pour une variable explicative binaire. Plutôt que d’assigner à la classe la plus probable, une prédiction aléatoire simule une variable 0/1 avec probabilité \((1-\widehat{p}_i, \widehat{p}_i)\). Pour un modèle de régression linéaire par moindres carrés ordinaires avec vecteur ligne de prédicteurs \(\mathbf{x}_i\) et matrice de modèle \(\mathbf{X}\), la prédiction sera tirée de la loi prédictive normale1.
Il existe d’autres façons d’imputer les valeurs manquantes mais le problème de toutes ces approches est que l’on ne tient pas compte du fait que des valeurs ont été remplacées et on fait comme si c’était de vraies observations. Cela va en général sous-évaluer la variabilité dans les données. Par conséquent, les écarts-type des paramètres estimés seront en général sous-estimés et l’inférence (tests et intervalles de confiance) ne sera pas valide. Cette approche n’est donc pas recommandée.
Une manière de tenter de reproduire correctement la variabilité dans les données consiste à ajouter un terme aléatoire dans l’imputation. C’est ce que fait la méthode suivante, qui possédera l’avantage de corriger automatiquement les écarts-type des paramètres estimés.
8.2.3 Imputation multiple
Cette méthode peut être appliquée dans à peu près n’importe quelle situation et permet d’ajuster les écarts-type des paramètres estimés. Elle peut être appliquée lorsque le processus est MAR (et donc aussi MCAR).
L’idée consiste à procéder à une imputation aléatoire, selon une certaine technique, pour obtenir un échantillon complet et à ajuster le modèle d’intérêt avec cet échantillon. On répète ce processus plusieurs fois et on combine les résultats obtenus.
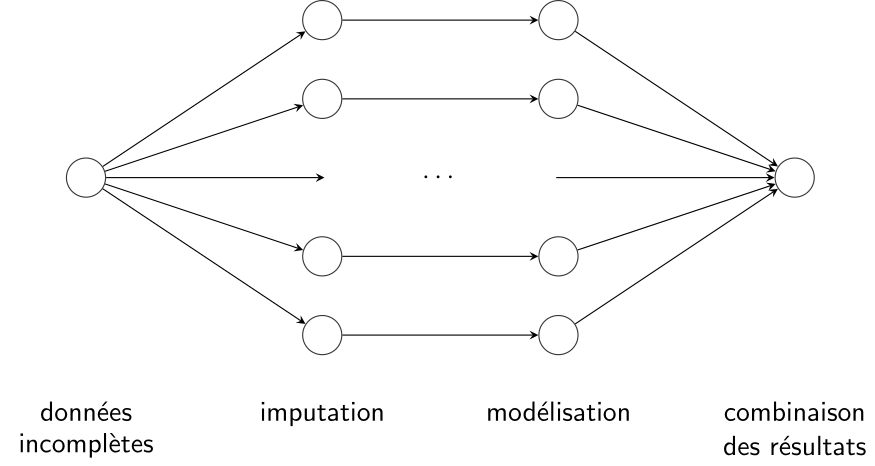
L’estimation finale des paramètres du modèle est alors simplement la moyenne des estimations pour les différentes répétitions et on peut également obtenir une estimation des écarts-type des paramètres qui tient compte du processus d’imputation.
Plus précisément, supposons qu’on s’intéresse à un seul paramètre \(\theta\) dans un modèle donné. Ce modèle pourrait être un modèle de régression linéaire, de régression logistique, etc. Le paramètre \(\theta\) serait alors un des \(\boldsymbol{\beta}\) du modèle.
Supposons qu’on procède à \(K\) imputations, c’est-à-dire, qu’on construit \(K\) ensemble de données complets à partir de l’ensemble de données initial contenant des valeurs manquantes. On estime alors les paramètres du modèle séparément pour chacun des ensembles de données imputés. Soit \(\widehat{\theta}_k\), l’estimé du paramètre \(\theta\) pour l’échantillon \(k \in \{1, \ldots, K\}\) et \(\widehat{\sigma}_k^2=\mathsf{Va}(\widehat{\theta}_k)\) l’estimé de la variance de \(\widehat{\theta}_k\) produite par le modèle estimé.
L’estimation finale de \(\theta\), dénotée \(\widehat{\theta}\), est obtenue tout simplement en faisant la moyenne des estimations de tous les modèles, c’est-à-dire, \[\begin{align*} \widehat{\theta} = \frac{\widehat{\theta}_1 + \cdots + \widehat{\theta}_K}{K}. \end{align*}\] Une estimation ajustée de la variance de \(\widehat{\theta}\) est \[\begin{align*} \mathsf{Va}(\hat{\theta}) &= W+ \frac{K+1}{K}B, \\ W &= \frac{1}{K} \sum_{k=1}^K \widehat{\sigma}^2_k = \frac{\widehat{\sigma}_1^2 + \cdots + \widehat{\sigma}_K^2}{K},\\ B &= \frac{1}{K-1} \sum_{k=1}^K (\widehat{\theta}_k - \widehat{\theta})^2. \end{align*}\] Ainsi, le terme \(W\) est la moyenne des variances et \(B\) est la variance entre les imputations. Le terme \((1+1/K)B\) est celui qui vient corriger le fait qu’on travaille avec des données imputées et non pas des vraies données en augmentant la variance estimée du paramètre.
C’est ici qu’on voit l’intérêt à procéder à de l’imputation multiple. Si on procédait à une seule imputation (même en ajoutant une part d’aléatoire pour essayer de reproduire la variabilité des données), on ne serait pas en mesure d’estimer la variance inter-groupe de l’estimateur. Notez que la formule présentée n’est valide que pour le cas unidimensionnel; l’estimation de la variance dans le cas multidimensionnel est différente (Little and Rubin 2019).
Il faut également ajuster les formules pour le calcul des intervalles de confiance, valeurs-\(p\) et degrés de liberté. Le logiciel s’en chargera pour nous.
La méthode d’imputation multiple possède l’avantage d’être applicable avec n’importe quel modèle sous-jacent. Une fois qu’on a des échantillons complets (imputés), on ajuste le modèle comme d’habitude. Mais une observation imputée ne remplacera jamais une vraie observation. Il faut donc faire tout ce qu’on peut pour limiter le plus possible les données manquantes.
Il faut utiliser son jugement. Par exemple, si la proportion d’observations perdues est petite (moins de 5%), ça ne vaut peut-être pas la peine de prendre des mesures particulières et on peut faire une analyse avec les données complètes seulement. S’il y a un doute, on peut faire une analyse avec les données complètes seulement et une autre avec imputations multiples afin de valider la première.
Si, à l’inverse, une variable secondaire cause à elle seule une grande proportion de valeurs manquantes, on peut alors considérer l’éliminer afin de récupérer des observations. Par exemple, si vous avez une proportion de 30% de valeurs manquantes en utilisant toutes vos variables et que cette proportion baisse à 3% lorsque vous éliminez quelques variables peu importantes pour votre étude (ou qui peuvent être remplacées par d’autres jouant à peu près le même rôle qui elles sont disponibles), alors vous pourriez considérer la possibilité de les éliminer. Il est donc nécessaire d’examiner la configuration des valeurs manquantes avant de faire quoi que ce soit.
Pour l’imputation, nous utiliserons l’algorithme d’imputation multiple par équations chaînées (MICE).
Avec \(p\) variables \(X_1, \ldots, X_p\), spécifier un ensemble de modèles conditionnels pour chaque variable \(X_j\) en fonction de toutes les autres variables, \(\boldsymbol{X}_{-j}\) et les valeurs observées pour cette variable, \(X_{j, \text{obs}}\).
L’idée est de remplir aléatoire tous les trous et ensuite d’utiliser des modèles d’imputation aléatoire pour chaque variable à tour de rôle. Après plusieurs cycles où chacune des variables explicatives (au plus le nombre de colonnes \(p\)) est imputée, l’impact de l’initialisation devrait être faible. On retourne alors une copie de la base de données.
- Initialisation: remplir les trous avec des données au hasard parmi \(X_{j, \text{obs}}\) pour \(X_{j, \text{man}}\)
- À l’itération \(t\), pour chaque variable \(j=1, \ldots, p\), à tour de rôle:
- tirage aléatoire des paramètres \(\phi_j^{(t)}\) du modèle pour \(X_{j,\text{man}}\) conditionnel à \(\boldsymbol{X}_{-j}^{(t-1)}\) et \(X_{j, \text{obs}}\)
- échantillonnage de nouvelles observations \(X^{(t)}_{j,\text{man}}\) du modèle avec paramètres \(\phi_j^{(t)}\) conditionnel à \(\boldsymbol{X}_{-j}^{(t-1)}\) et \(X_{j, \text{obs}}\)
- Répéter le cycle
8.3 Example d’application de l’imputation
On examine l’exemple de recommandations de l’association professionnelle des vachers de la section Section 4.2.3.
Le but est d’examiner les effets des variables \(X_1\) à \(X_6\) sur les intentions d’achat; la base de données manquantes contient les observations. Il s’agit des mêmes données que celles du fichier logit1 mais avec des valeurs manquantes.
| \(X_1\) | \(X_2\) | \(X_3\) | \(X_4\) | \(X_5\) | \(X_6\) | \(y\) |
|---|---|---|---|---|---|---|
| 1 | 4 | 0 | 1 | 35 | 2 | 0 |
| . | 1 | 0 | . | 33 | 3 | 0 |
| 2 | 3 | 1 | . | 46 | 3 | 0 |
| 5 | 2 | 1 | . | 32 | 1 | 1 |
| 3 | 2 | 1 | . | 38 | 3 | 1 |
| . | 4 | 0 | 0 | 36 | 3 | 0 |
| . | 3 | 0 | . | 35 | 3 | 0 |
| . | 5 | 1 | 0 | 26 | 2 | 0 |
| . | 3 | 1 | 1 | 39 | 2 | 1 |
| 5 | 2 | 1 | . | 38 | 3 | 0 |
Les points (.) indiquent des valeurs manquantes. Le premier sujet n’a pas de valeur manquante. Le deuxième a une valeur manquante pour \(X_1\) (emploi) et \(X_4\) (éducation), etc.
Une première façon de voir combien il y a de valeurs manquantes consiste à faire sortir les statistiques descriptives avec summary. Ainsi, il y 192 valeurs manquantes pour \(X_1\), 48 pour \(X_2\) et 184 pour \(X_4\). Les autres variables n’ont pas de valeurs manquantes, incluant la variable dépendante \(Y\). La procédure unidimensionnelle nous permet seulement de voir combien il y a de valeurs manquantes variable par variable.
| \(X_1\) | \(X_2\) | \(X_3\) | \(X_4\) | \(X_5\) | \(X_6\) | \(y\) | |
|---|---|---|---|---|---|---|---|
| nombre | 192 | 49 | 0 | 184 | 0 | 0 | 0 |
| pourcentage | 0.384 | 0.098 | 0 | 0.368 | 0 | 0 | 0 |
data(manquantes, package = 'hecmulti')
summary(manquantes)
# Pourcentage de valeurs manquantes
apply(manquantes, 2, function(x){mean(is.na(x))})
# Voir les configurations de valeurs manquantes
md.pattern(manquantes)Nous utiliserons le paquet R mice pour faire l’imputation.
- Procéder à plusieurs imputations aléatoires pour obtenir un échantillon complet (
mice) - Ajuster le modèle d’intérêt avec chaque échantillon (
with). 3. Combiner les résultats obtenus (pooletsummary)
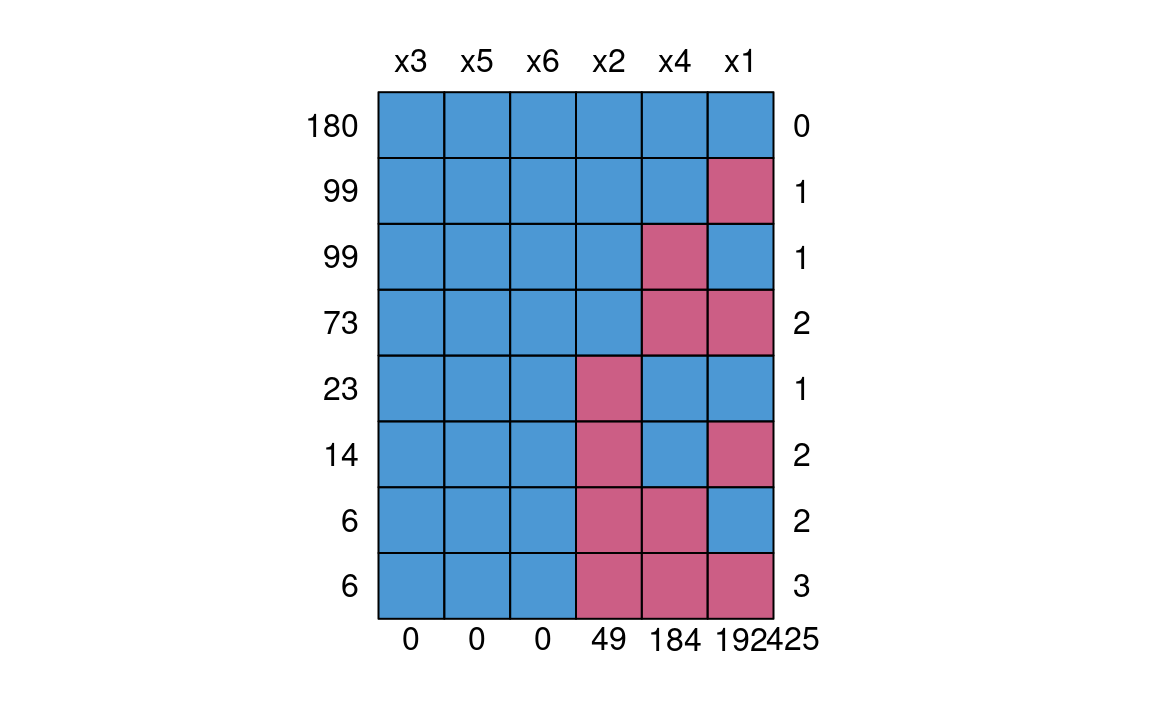
manquantes.
La Figure 8.2 donne une indication sur les différentes combinaisons de données complètes (cases bleues) et les observations manquantes (cases roses) avec leur fréquence. Les variables sont indiquées au dessus, le nombre total de valeurs manquantes par variable en dessous, le nombre d’observations pour chaque configuration de valeurs manquantes à gauche à gauche et le nombre de variables avec des valeurs manquantes par configuration à droite. Ainsi, il y a 180 sujets (36% de l’échantillon) avec aucune observation manquante. Il y en a 99 avec seulement \(X_4\) manquante et ainsi de suite. On voit donc, par exemple, que pour 14 sujets, à la fois \(X_1\) et \(X_2\) sont manquantes.
La recommandation d’usage est d’imputer au moins le pourcentage de cas incomplet, ici 64% donc 64 imputations. Si la procédure est trop coûteuse en calcul, on peut diminuer le nombre d’imputations, mais il faut au minimum 10 réplications pour avoir une bonne idée de la variabilité.
On peut comparer l’inférence avec toutes les variables explicatives pour les données sans valeurs manquantes (\(n=500\) observations), avec les cas complets uniquement (\(n=180\) observations). Le Tableau 8.3 présente les estimations des paramètres du modèle de régression logistique s’il n’y avait pas eu de valeurs manquantes, avec les cas complets et les résultats de l’imputation multiple.
Si on ajuste un modèle à une base de données qui contient des valeurs manquantes, le comportement par défaut est de retirer les observations qui ont au moins une valeur manquante pour une des variables nécessaires à l’analyse (voir la sortie de glm(y ~ ., data = manquantes)). Il ne serait pas raisonnable de faire l’analyse avec seulement 180 observations et de laisser tomber les 320 autres. De plus, comme nous l’avons vu plus haut, ce n’est pas valide à moins que le processus ne soit MCAR. La partie du milieu du Tableau 8.3 présente les estimations obtenues. Plusieurs variables significatives à niveau \(\alpha=0.05\) ne le sont plus (puisqu’il y a moins d’information quand on réduit le nombre d’observations). Il y a même pire: non seulement la variable \(\mathsf{I}(X_2=1)\) est passée de significative à non significative, mais en plus l’estimé de son paramètre a changé de signe.
Nous allons donc faire l’analyse avec l’imputation multiple, en prenant la méthode d’imputation par défaut
library(mice)
# Imputation multiple avec équations enchaînées
# Intensif en calcul, réduire `m` si nécessaire
impdata <- mice(data = manquantes,
m = 50,
seed = 2021,
method = "pmm",
printFlag = FALSE)
# Chaque copie est disponible (1, ..., 50)
complete(impdata, action = 1)
# ajuste les modèles avec les données imputées
adj_im <- with(data = impdata,
expr = glm(y ~ x1 + x2 + x3 + x4 + x5 + x6,
family = binomial(link = 'logit')))
# combinaison des résultats
fit <- pool(adj_im)
summary(fit)La procédure mice du paquet éponyme crée les copies complètes du jeu de données. On peut ensuite appliquer une procédure quelconque et combiner les estimations avec pool.
| $\widehat{\boldsymbol{\beta}}$ | $\mathrm{se}(\widehat{\boldsymbol{\beta}})$ | valeur-$p$ | $\widehat{\boldsymbol{\beta}}$ | $\mathrm{se}(\widehat{\boldsymbol{\beta}})$ | valeur-$p$ | $\widehat{\boldsymbol{\beta}}$ | $\mathrm{se}(\widehat{\boldsymbol{\beta}})$ | valeur-$p$ | |
|---|---|---|---|---|---|---|---|---|---|
| cste | -6.89 | 1.02 | 0.00 | -5.25 | 1.70 | 0.00 | -6.57 | 1.04 | 0.00 |
| $x_1=1$ | 0.36 | 0.48 | 0.46 | -0.09 | 0.85 | 0.92 | 0.55 | 0.54 | 0.31 |
| $x_1=2$ | -0.47 | 0.37 | 0.21 | -0.57 | 0.66 | 0.39 | -0.13 | 0.45 | 0.78 |
| $x_1=3$ | -0.31 | 0.35 | 0.37 | -0.47 | 0.66 | 0.47 | 0.07 | 0.44 | 0.87 |
| $x_1=4$ | -0.32 | 0.40 | 0.43 | -0.93 | 0.74 | 0.21 | -0.04 | 0.48 | 0.93 |
| $x_2=1$ | 1.33 | 0.60 | 0.03 | -0.74 | 1.14 | 0.52 | 1.10 | 0.65 | 0.09 |
| $x_2=2$ | 1.15 | 0.50 | 0.02 | 0.46 | 0.91 | 0.61 | 1.03 | 0.55 | 0.06 |
| $x_2=3$ | 0.77 | 0.48 | 0.11 | -0.41 | 0.89 | 0.64 | 0.52 | 0.52 | 0.31 |
| $x_2=4$ | -1.11 | 0.54 | 0.04 | -2.74 | 1.02 | 0.01 | -1.04 | 0.57 | 0.07 |
| $x_3$ | 1.35 | 0.26 | 0.00 | 0.80 | 0.44 | 0.07 | 1.19 | 0.27 | 0.00 |
| $x_4$ | 1.83 | 0.30 | 0.00 | 2.25 | 0.58 | 0.00 | 1.52 | 0.37 | 0.00 |
| $x_5$ | 0.11 | 0.02 | 0.00 | 0.11 | 0.03 | 0.00 | 0.10 | 0.02 | 0.00 |
| $x_6=1$ | 2.41 | 0.38 | 0.00 | 2.23 | 0.66 | 0.00 | 2.26 | 0.38 | 0.00 |
| $x_6=2$ | 1.04 | 0.25 | 0.00 | 0.83 | 0.44 | 0.06 | 1.00 | 0.25 | 0.00 |
On peut remarquer que la précision est systématiquement meilleure avec l’imputation multiple; les erreurs-type pour l’imputation multiple sont plus petits que celle du modèle qui retire les données incomplètes.
On voit que la variable \(X_3\) (sexe) est significative avec l’imputation multiple. Son paramètre estimé est 1.19, comparativement à 1.349 s’il n’y avait pas eu de valeurs manquantes. La précision dans l’estimation avec l’imputation multiple est seulement un peu moins bonne (erreur-type de 0.27) que celle s’il n’y avait pas eu de manquantes (erreur type de 0.26). Le paramètre de \(\mathsf{I}(X_6=2)\) redevient aussi significatif, alors qu’il ne l’était plus si on retirait les manquantes. Il est peu probable que les données soit \(\mathsf{MCAR}\) et donc les résultats de l’analyse des cas complets seraient biaisés.
En résumé
- Les données manquantes réduisent la quantité d’information disponible et augmentent l’incertitude.
- On ne peut pas les ignorer (étude des cas complets) sans biaiser les interprétations et réduire la quantité d’information disponible.
- Pour bien capturer l’incertitude et ne pas modifier les relations entre variables, il faut utiliser une méthode d’imputation aléatoire.
- Avec l’algorithme MICE, on utilise un modèle conditionnel pour chaque variable à tour de rôle.
- L’imputation multiple est préférée à l’imputation simple car elle permet d’estimer l’incertitude sous-jacente en raison des données manquantes.
- Il faut un traitement spécial pour les erreurs-type, degrés de liberté, valeurs-\(p\) et intervalles de confiance.
Spécifiquement, une loi normale avec moyenne \(\widehat{y}_i=\mathbf{x}_i\widehat{\boldsymbol{\beta}}\) et variance \(\widehat{\sigma}^2\{\mathbf{x}_i\mathbf{X}^\top\mathbf{X})^{-1}\mathbf{x}_i^\top + 1\}\)↩︎