data(GK14_S3, package = "hecedsm")
model <- aov(persp ~ condition, data = GK14_S3,
subset = (age == "young")) # select specific subsetProblem set 3
Submission information: please submit on ZoneCours
- a PDF report
- your code
following the naming convention PS3-studentid.extension where studentid is replaced with your student ID and extension is the file extension (e.g., .pdf, .R, .Rmd, .sps)
Instructions: We consider data collected for Study 3 of Grossmann & Kross (2014) (click the links to download the paper and the Supplementary material). You can access these data directly from R from the hecedsm package or download the SPSS data.
If you work with R, check out this helper code
Have a quick look at the paper and fit the one way analysis of variance model for the consideration of other’s perspective (persp) scores as a function of experimental condition, restricting attention to the subsample consisting of young adults (20 to 40 years) (age == "young").
- Report the \(F\)-test statistic, the null distribution and the \(p\)-value.
- Provide a conclusion in the context of the study.
- There are missing values (see code output below). One thing to check normally is whether the lack of response is due to the treatment (for example, tasks that are more difficult or longer lead to higher dropout rate). Using the code provided below, inspect the pattern. Do you think there is a cause for concern in the present context?
We next look at model assumptions
- Is the independence assumption plausible in the context?
- How many observations are there in each group (excluding missing values)? Is the number sufficient to reliably estimate the sample mean of each experimental condition and forego normality checks?
- Produce a normal quantile-quantile plot and comment on the distribution of the residuals (check out this response on CrossValidated first).
- Check the equality of variance assumption using a suitable test statistic and report the results.
- Use Welch’s one-way analysis of variance model (
oneway.test()in R) and compare the output and the conclusion with that of the usual \(F\)-test.
Hints and R snippets
To subset the data in a model, you can use the following commands:
The following code filters out missing values for persp for young adults and shows the counts for each condition:
GK14_S3 |>
dplyr::filter(age == "young") |> # select only young adults (20-40 years old)
dplyr::group_by(condition) |>
dplyr::summarize(count = sum(!is.na(persp)), # count of non-missing observations
nmiss = sum(is.na(persp))) # count of missing values# A tibble: 4 × 3
condition count nmiss
<fct> <int> <int>
1 self immersed 69 3
2 self distanced 62 3
3 other immersed 63 3
4 other distanced 62 2and finally the following code chunk creates box and whiskers plots and overlays the (jittered) data.
library(ggplot2) # grammar of graphics
ggplot(data = GK14_S3 |> dplyr::filter(age == "young"),
mapping = aes(x = condition,
y = persp,
color = condition)) +
geom_boxplot() +
geom_jitter()Warning: Removed 11 rows containing non-finite outside the scale range
(`stat_boxplot()`).Warning: Removed 11 rows containing missing values or values outside the scale range
(`geom_point()`).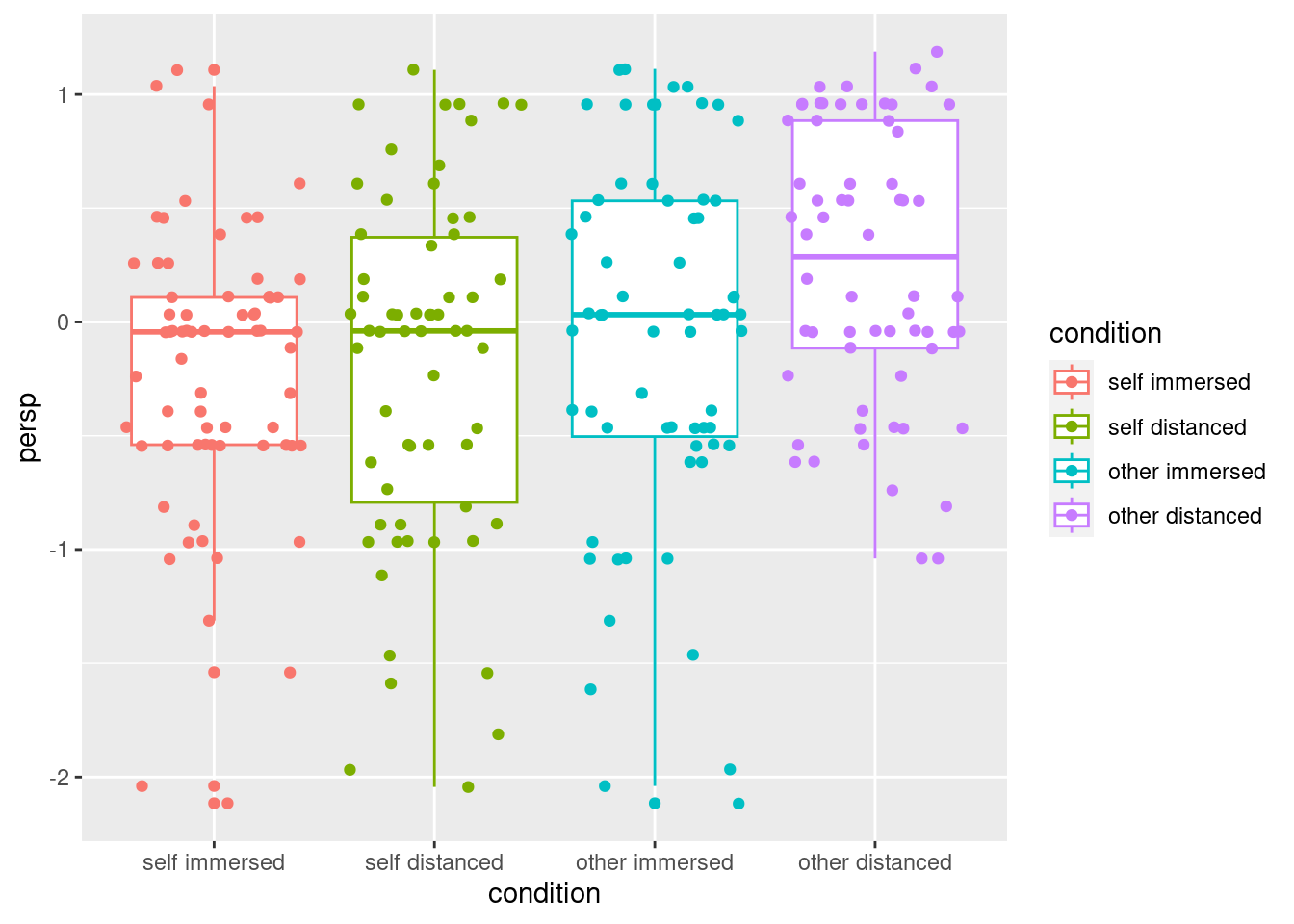
References
Grossmann, I., & Kross, E. (2014). Exploring Solomon’s paradox: Self-distancing eliminates the self-other asymmetry in wise reasoning about close relationships in younger and older adults. Psychological Science, 25(8), 1571–1580. https://doi.org/10.1177/0956797614535400