Submission information: please submit on ZoneCours
a PDF report
your code
Task 1
We consider data from Experiment 2 of Jordan et al. (2022), who measured the confidence of participants on their ability to land successfully a plane if the pilot was incapacitated, after they were exposed to a trivially uninformative 3 minute video of a pilot landing a plane, but filmed in such a way that it was utterly useless. The authors pre-registered a comparison between experimental conditions video vs no video, and found that people watching the video answered higher for the question “How confident are you that you would be able to land the plane without dying”, but there was no discernible effect for “How confident are you that you would be able to successfully land the plane as well as a pilot could”, contrary to expectations. They found that the order in which the questions were asked (order, either pilot first, or dying first) changed the response.
The database in package hecedsm in R is labelled JZBJG22_E2. You can also download the SPSS database via this link.
A dataset is said to be balanced if there are the same number of people in each experimental condition. Are the data balanced over condition and order? Justify your answer.
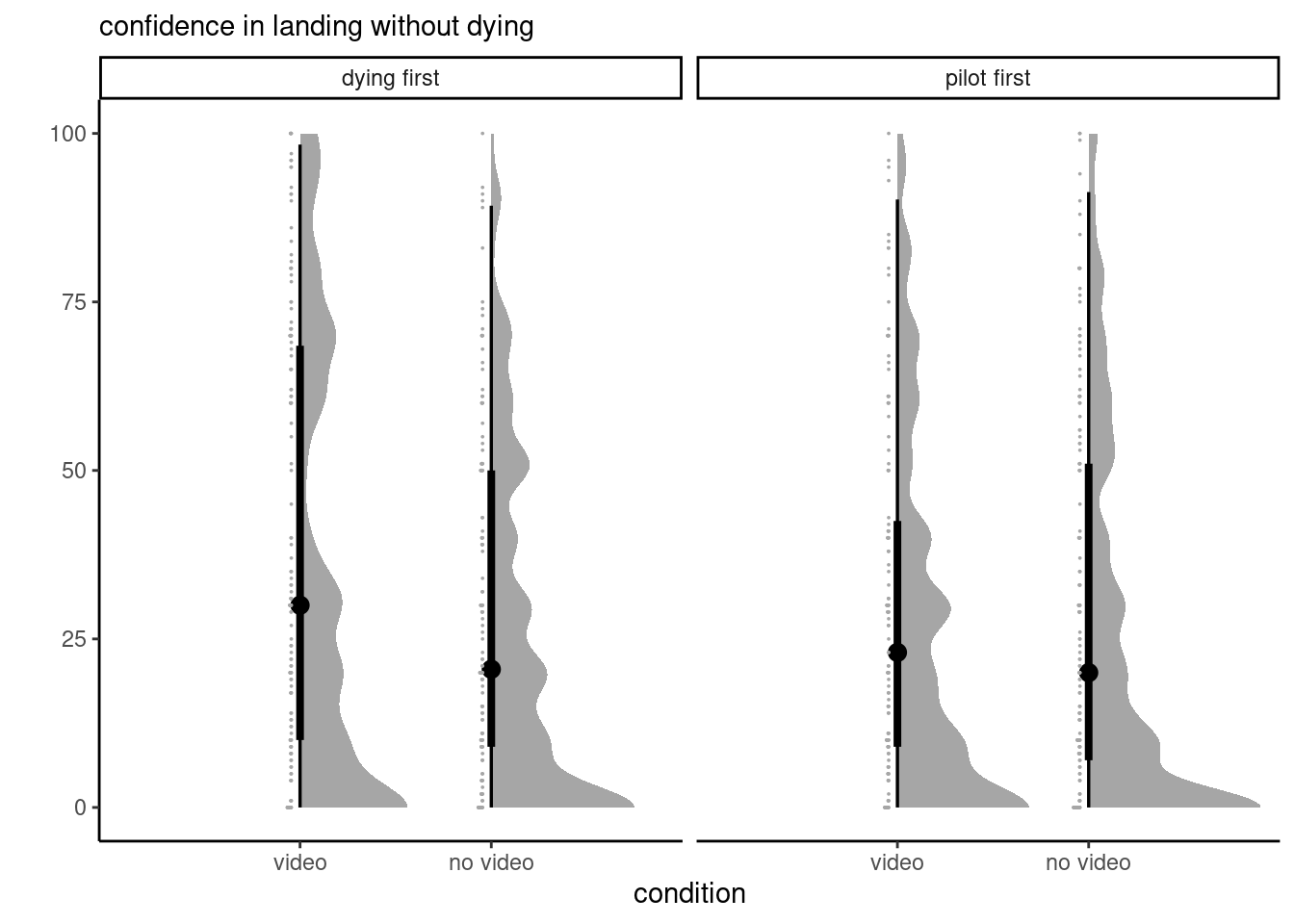
Look at Figure Figure 1 and comment on the distribution of the scores along the scale.
Perform the two-way analysis of variance for both conf_dying and conf_pilot and report the null and alternative hypotheses, the test statistic, the \(P\)-value and the conclusion of the test.
For each response variable conf_dying and conf_pilot, perform follow-up tests. Compute simple or main effects (depending on whether the interaction is significant or not), along with 95% confidence intervals for the difference in score for video conditions.
Indications and helper code
There is no R script this week, but below are some instructions for fitting the different models.
Figure 1: Half-violin (density) plots, with box plots and 95% intervals, and jittered scatterplot for confidence in landing without dying, as a function of order and condition.
You must repeat this for the other response variable.
In SPSS, you need to specify manually with GGRAPH the format. This post shows an example of such plots.
Welch ANOVA
Using Levene’s test, we can check whether the variance in each subgroup is the same. In this example, we find that there are significant differences in variance per subgroup, but the effect on \(p\)-values is negligeable, so we can safely ignore it here.
If the variance are unequal, we want to fit a model to observations in subgroup \((a_j, b_k)\) for \(j=1, \ldots, n_a\) and \(k=1, \ldots, n_b\), specifying that in the subgroup the average is \(\mu_{jk}\) and the variance \(\sigma^2_{jk}\). The resulting \(F\) test from comparing overall means is typically named Welch after Welch (1947).
In R, the Welch ANOVA can be obtained via oneway.test, but there is no possibility of follow-up for marginal means and contrasts. Rather, use the function gls in package nlme as follows.
model <- nlme::gls(model = conf_dying ~ condition*order,data = JZBJG22_E2,weights = nlme::varIdent(form =~1| condition*order))# Use condition*order to get a different variance for each subgroup# ANOVA table for testing the interaction - use type 2car::Anova(model, type =2)
To obtain the analysis of variance table in R to an object model representing an ANOVA with unbalanced data, use the car::Anova function. Use type=2 as argument (the default). You can pass model to emmeans as before to compute main/simple effects.
In SPSS, you must first transform the \(2 \times 2\) into a one-way ANOVA with a categorical variable having \(4\) levels. Then, use oneway and code directly the contrasts for the interaction, and either the simple effects of condition for each level of order, and the main effect of condition, depending on which is most suitable.
References
Jordan, K., Zajac, R., Bernstein, D., Joshi, C., & Garry, M. (2022). Trivially informative semantic context inflates people’s confidence they can perform a highly complex skill. Royal Society Open Science, 9(3), 211977. https://doi.org/10.1098/rsos.211977
Welch, B. L. (1947). The generalization of “Student’s” problem when several population variances are involved. Biometrika, 34(1–2), 28–35. https://doi.org/10.1093/biomet/34.1-2.28