Penultimate approximations
Léo Belzile
2025-09-30
Source:vignettes/03-penultimate.Rmd
03-penultimate.RmdTheory
The generalized extreme value (GEV) distribution arises as the non-degenerate limiting distribution of maxima. A key property of the generalized extreme value distribution is max-stability, meaning that the distribution of maxima of is the same up to a location-scale transform: if , then there exist location and scale constants and such that . The parameters of the new distribution are easily derived: if , then with and for , or and if .
In practice, the GEV is fitted to data that are partitioned into blocks of sizes , assumed eequal for simplicity, so that . The quality of the generalized extreme value approximation increases with the block size . For fixed block sizes, the estimated shape parameter generally differs from its asymptotic counterpart and this discrepancy usually introduces bias if one extrapolates far beyond the range of the observed data.
Let denote a thrice-differentiable distribution function with endpoint and density and define . The existence of the limit is necessary and sufficient for convergence to an extreme value distribution ,
Smith (1987) shows that, for any , there exists such that For each , setting and yields for , depending on the support of . The ultimate approximation replaces by , whereas Smith (1987) suggests instead suggests taking , which is closer to than is .
The maximum likelihood estimate of the shape should change as the threshold or the block size increases. Consider for simplicity yearly maxima arising from blocking observations per year. We are interested in the distribution of the maximum of years and thus the target has roughly shape , but our estimates will instead give approximately ; an extrapolation error arises from this mismatch between the shape values, which would be constant if the observations were truly max-stable. The curvature of determines how stable the estimates of are when the extrapolation window increases.
We illustrate the previous discussion by looking at block maximum from a log-normal distribution.
library(mev)
set.seed(123)
x <- seq(1, 30, length = 200)
fitted <- t(
replicate(
n = 200,
fit.gev(
xdat = apply(
X = matrix(rlnorm(30 * 100),
ncol = 30),
MARGIN = 1,
FUN = max),
method = "BFGS")$est))
penult.bm.lnorm <-
mev::smith.penult(model = "bm",
m = (m <- 30),
family = "lnorm")
par(mfrow = c(1, 2), mar = c(5, 5, 1, 1))
hist(
fitted[, 3],
probability = TRUE,
breaks = 20,
xlab = "estimated shape",
main = ""
)
segments(
y0 = -0.5,
y1 = 0,
x0 = penult.bm.lnorm$shape,
col = "red",
lwd = 2
)
segments(
y0 = -0.5,
y1 = 0,
x0 = 0,
col = "black",
lwd = 2
)
p30 <- penult.bm.lnorm
x = seq(0, 100, length = 400)
N <- 1000
N30 = N / 30
plot(
x,
N * exp((N - 1) * plnorm(x, log.p = TRUE)) *
dlnorm(x),
type = "l",
bty = "l",
ylim = c(0, 0.1),
xlab = "x",
ylab = "density"
)
# Get parameters of maximum of N GEV
maxstabp <- function(loc, scale, shape, N) {
if (!isTRUE(all.equal(shape, 0, check.attributes = FALSE))) {
mut <- loc - scale * (1 - N ^ shape) / shape
sigmat = scale * N ^ shape
return(c(
loc = mut,
scale = sigmat,
shape = shape
))
} else{
mut <- loc + scale * log(N)
return(c(
loc = mut,
scale = scale,
shape = shape
))
}
}
p30e <-
maxstabp(
loc = p30$loc,
scale = p30$scale,
shape = p30$shape,
N = N30
)
lines(
x,
evd::dgev(
x,
loc = p30e['loc'],
scale = p30e['scale'],
shape = p30e['shape']
),
col = "red",
lwd = 2,
lty = 2
)
p30l <-
maxstabp(
loc = p30$loc,
scale = p30$scale,
shape = 0,
N = N30
)
lines(
x,
evd::dgev(
x,
loc = p30e['loc'],
scale = p30l['scale'],
shape = 0
),
col = 1,
lty = 3,
lwd = 1
)
legend(
x = "topright",
legend = c("exact", "ultimate", "penultimate"),
col = c(1, 1, 2),
lwd = c(2, 2, 1),
bty = "n",
lty = c(1, 3, 2)
)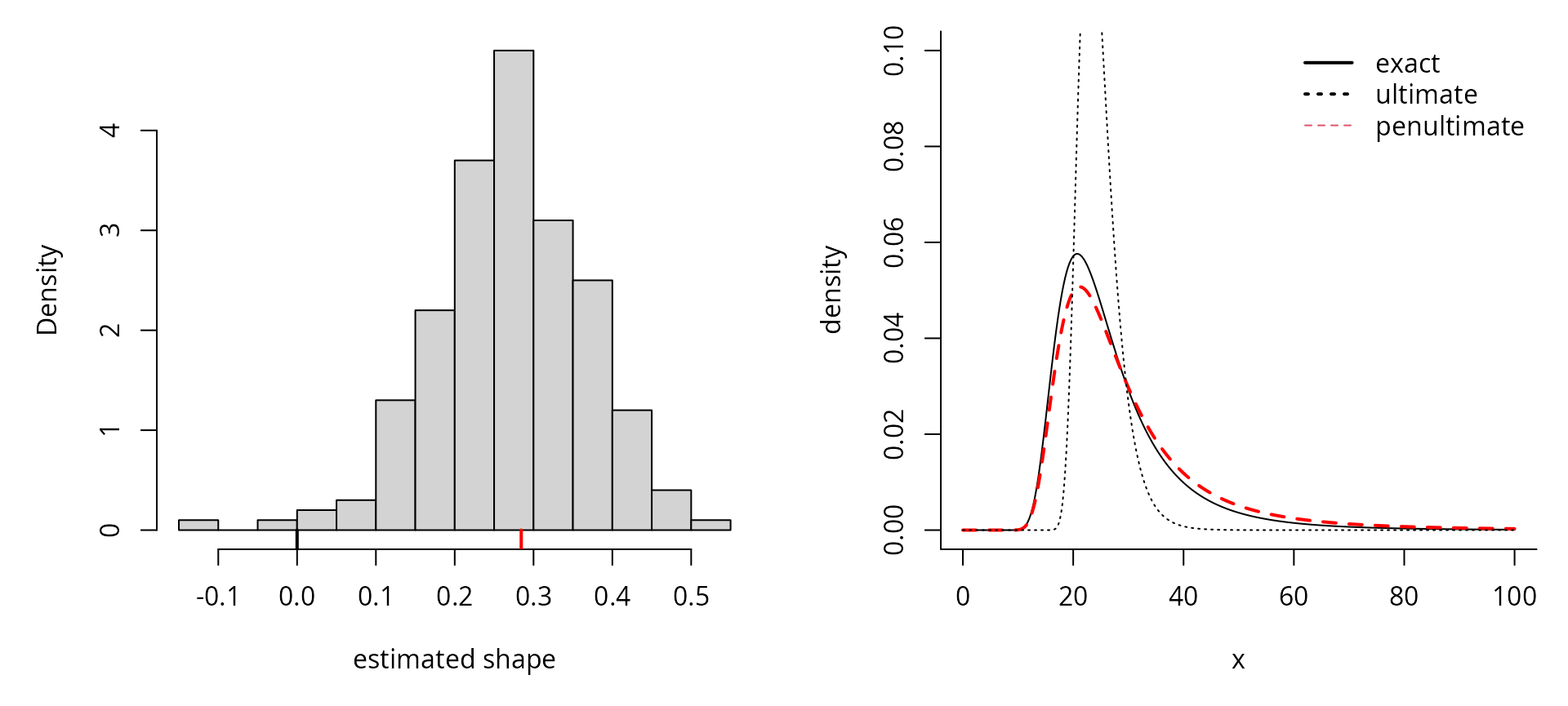
The left panel illustrates how maximum likelihood estimates of the parameters for repeated samples from a log-normal distribution are closer to the penultimate approximation than to the limiting tail index . Using max-stability, we could get an estimate of the distribution of the maximum of observations. In this case, the penultimate shape for is approximately , compared to , which is far from the limiting value . The extrapolated density estimate is based on , the generalized extreme value density associated to the distribution function of the penultimate approximation , with . The penultimate approximation is more accurate than the ultimate approximation , which is too short tailed.
The function smith.penult computes the penultimate
approximation for parameter models in R for the
distribution assuming a model family with arguments
dfamily, qfamily and pfamily
exist. It returns the penultimate parameters for a given block size or
quantile in case of threshold models. These functions are particularly
useful for simulation studies in which one wants to obtain an
approximation for
for large
,
to get an approximation to the asymptotic distribution of a test
statistic for finite
;
the
penultimate approximation is more numerically stable for certain models
and its moments and cumulants are easily derived.
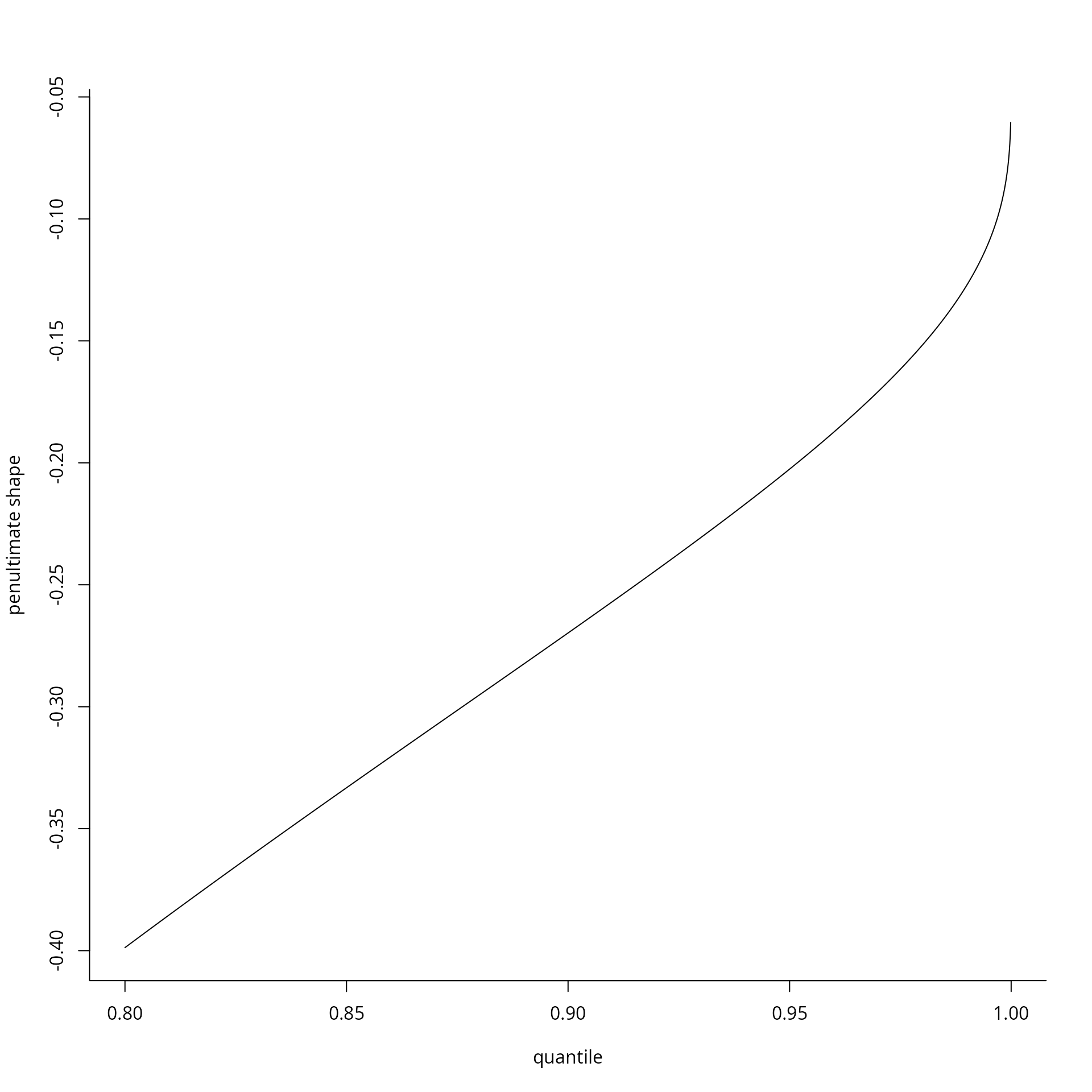
The following plot illustrates the penultimate shape parameter for the normal distribution based on threshold exceedances. In finite samples, the upper tail is bounded, but the quality of the approximation by the Gumbel distribution increases as , albeit very slowly.
u <- seq(0.8, 0.9999, by = 0.0001)
penult <- smith.penult(family = "norm",
method = "pot",
u = qnorm(u))
plot(
u,
penult$shape,
bty = "l",
type = 'l',
xlab = 'quantile',
ylab = 'penultimate shape'
)
While the above discussion has been restricted to block maxima and the generalized extreme value distribution, similar results exists for peaks over threshold using a generalized Pareto distribution. For threshold exceedances, we start with the reciprocal hazard in place of . The normalizing constants are and the penultimate shape parameter for the generalized Pareto distribution is .
We can relate threshold exceedances to the distribution of maxima as follows: suppose a generalized Pareto distribution is fitted to threshold exceedances above a threshold , with parameters , where denotes the unknown proportion of points above the threshold . If there are observations per year on average, then the -year return level is . We take as the approximation to the -year maxima distribution, conditional on exceeding .
Exercice
- Sample observations from the standard Gaussian distribution for and replications.
- Fit a generalized extreme value distribution to block maxima of size
.
Obtain an estimate of the distribution of
observations from a standard Gaussian using max-stability (the functions
fit.gevandgev.mlecan be useful). - Plot the density of the resulting approximations and compare them to the density of the true distribution .
- Superpose the density of the penultimate approximation for
obtained using the Smith penultimate approximation
(
smith.penult).