3 Likelihood-based inference
This chapter is dedicated to the basics of statistical modelling using likelihood-based inference, arguably the most popular estimation paradigm in statistics.
Important
Learning objectives:
- Learn the terminology associated with likelihood-based inference
- Derive closed-form expressions for the maximum likelihood estimator in simple models
- Using numerical optimization, obtain parameter estimates and their standards errors using maximum likelihood
- Use large-sample properties of the likelihood to derive confidence intervals and tests
- Use information criteria for model selection
A statistical model starts with the specification of a data generating mechanism. We postulate that the data has been generated from a probability distribution with \(p\)-dimensional parameter vector \(\boldsymbol{\theta}.\) The sample space is the set in which the \(n\) vector observations lie, while the parameter space \(\boldsymbol{\Theta} \subseteq \mathbb{R}^p\) is the set in which the parameter takes values.
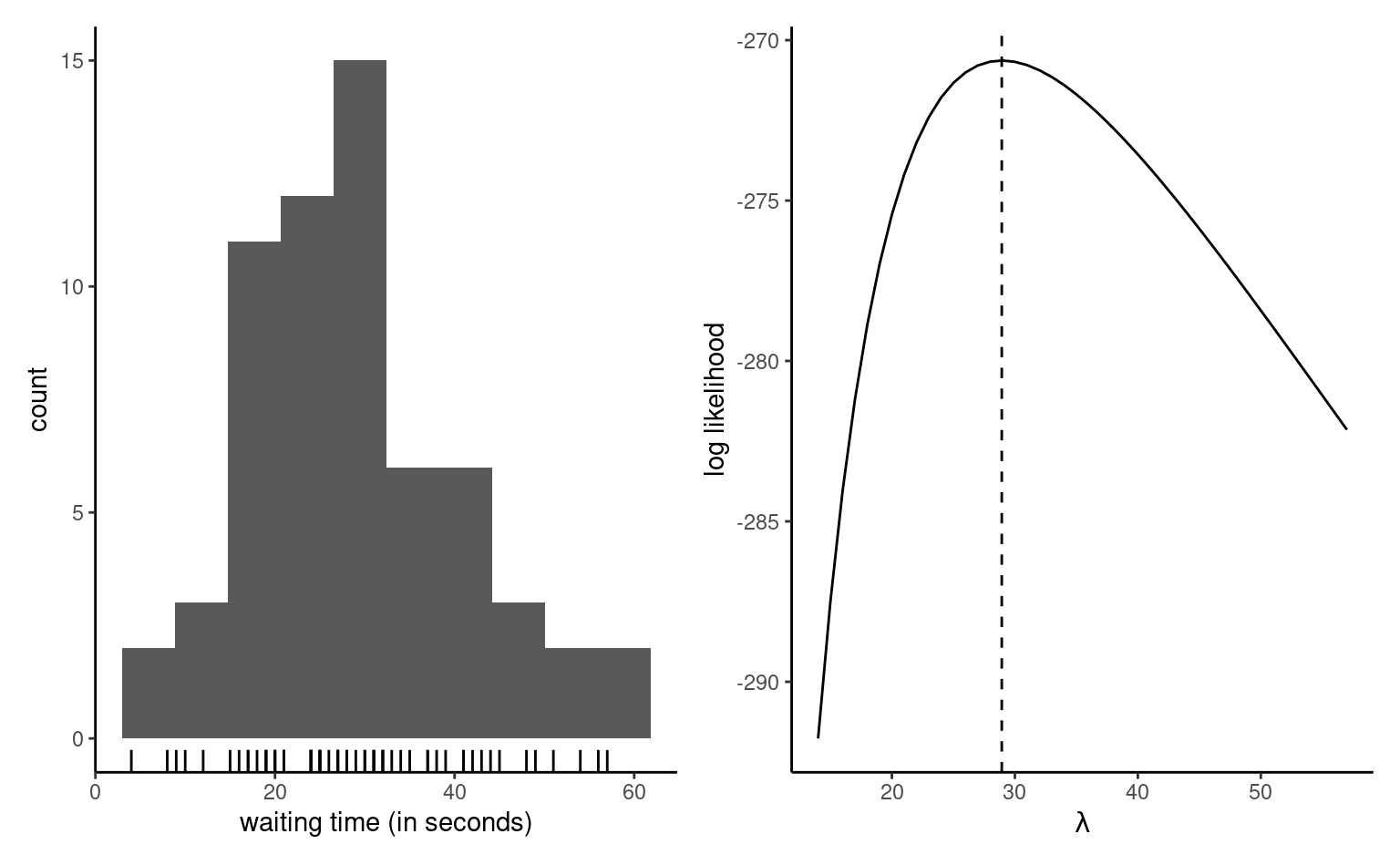
As motivating example, consider the time a passenger must wait at the Université de Montréal station if that person arrives at 17:59 sharp every weekday, just in time for the metro train. The measurements in waiting represent the time in seconds before the next train leaves the station. The data were collected over three months and can be treated as an independent sample. The left panel of Figure 3.1 shows an histogram of the \(n=62\) observations, which range from \(4\) to \(57\) seconds. The data are positive, so our model must account for this feature.
Example 3.1 (Exponential model for waiting times) To model the waiting time, we may consider for example an exponential distribution with scale \(\lambda\) (Definition 1.11), which represents the theoretical mean. Under independence1, the joint density for the observations \(y_1, \ldots, y_n\) is \[\begin{align*} f(\boldsymbol{y}) = \prod_{i=1}^n f(y_i) =\prod_{i=1}^n \lambda^{-1} \exp(- y_i/\lambda) = \lambda^{-n} \exp\left(- \sum_{i=1}^n y_i/\lambda\right) \end{align*}\] The sample space is \(\mathbb{R}_{+}^n = [0, \infty)^n,\) while the parameter space is \((0, \infty).\)
To estimate the scale parameter \(\lambda\) and obtain suitable uncertainty measures, we need a modelling framework. We turn to likelihood-based inference.
3.1 Maximum likelihood estimation
For any given value of \(\boldsymbol{\theta},\) we can obtain the probability mass or density of the sample observations, and we use this to derive an objective function for the estimation.
Definition 3.1 (Likelihood) The likelihood \(L(\boldsymbol{\theta})\) is a function of the parameter vector \(\boldsymbol{\theta}\) that gives the probability (or density) of observing a sample under a postulated distribution, treating the observations as fixed, \[\begin{align*} L(\boldsymbol{\theta}; \boldsymbol{y}) = f(\boldsymbol{y}; \boldsymbol{\theta}), \end{align*}\] where \(f(\boldsymbol{y}; \boldsymbol{\theta})\) denotes the joint density or mass function of the \(n\)-vector containing the observations.
If the latter are independent, the joint density factorizes as the product of the density of individual observations, and the likelihood becomes \[\begin{align*} L(\boldsymbol{\theta}; \boldsymbol{y})=\prod_{i=1}^n f_i(y_i; \boldsymbol{\theta}) = f_1(y_1; \boldsymbol{\theta}) \times \cdots \times f_n(y_n; \boldsymbol{\theta}). \end{align*}\] The corresponding log likelihood function for independent and identically distributions observations is \[\begin{align*} \ell(\boldsymbol{\theta}; \boldsymbol{y}) = \sum_{i=1}^n \ln f(y_i; \boldsymbol{\theta}) \end{align*}\]
Example 3.2 (Dependent data) The joint density function only factorizes for independent data, but an alternative sequential decomposition can be helpful. For example, we can write the joint density \(f(y_1, \ldots, y_n)\) using the factorization \[\begin{align*} f(\boldsymbol{y}) = f(y_1) \times f(y_2 \mid y_1) \times \ldots f(y_n \mid y_1, \ldots, y_n) \end{align*}\] in terms of conditional. Such a decomposition is particularly useful in the context of time series, where data are ordered from time \(1\) until time \(n\) and models typically relate observation \(y_n\) to it’s past. For example, the \(\mathsf{AR}(1)\) process, states that \(Y_t \mid Y_{t-1}=y_{t-1} \sim \mathsf{normal}(\alpha + \beta y_{t-1}, \sigma^2)\) and we can simplify the log likelihood using the Markov property, which states that the current realization depends on the past, \(Y_t \mid Y_1, \ldots, Y_{t-1},\) only through the most recent value \(Y_{t-1}.\) The log likelihood thus becomes \[\begin{align*} \ell(\boldsymbol{\theta}) = \ln f(y_1) + \sum_{i=2}^n f(y_i \mid y_{i-1}). \end{align*}\]
Definition 3.2 (Maximum likelihood estimator) The maximum likelihood estimator \(\widehat{\boldsymbol{\theta}}\) is the vector value that maximizes the likelihood, \[\begin{align*} \widehat{\boldsymbol{\theta}} = \mathrm{arg max}_{\boldsymbol{\theta} \in \boldsymbol{\Theta}} L(\boldsymbol{\theta}; \boldsymbol{y}). \end{align*}\]
The natural logarithm \(\ln\) is a monotonic transformation, so the maximum likelihood estimator \(\boldsymbol{\theta}\) for likelihood \(L(\boldsymbol{\theta}; \boldsymbol{y})\) is the same as that of the log likelihood \(\ell(\boldsymbol{\theta}; \boldsymbol{y}) = \ln L(\boldsymbol{\theta}; \boldsymbol{y}).\)2
If our model is correct, we expect to observe whatever was realized. In that sense, it makes sense to find the parameter vector that makes the sample the most likely to have been generated by our model. Several properties of maximum likelihood estimator makes it appealing for inference. The maximum likelihood estimator is efficient, meaning it has the smallest asymptotic mean squared error. The maximum likelihood estimator is also consistent, i.e., it converges to the correct value as the sample size increase (asymptotically unbiased).
We can resort to numerical optimization routines to find the value of the maximum likelihood estimate, or sometimes derive closed-form expressions for the estimator, starting from the log likelihood. The right panel of Figure 3.1 shows the exponential log likelihood, which attains a maximum at \(\widehat{\lambda}=28.935\) second, the sample mean of the observations. The function decreases to either side of these values as the data become less compatible with the model. Given the values achieved here with a small sample, it is easy to see that direct optimization of the likelihood function (rather than it’s natural logarithm) could lead to numerical underflow, since already \(\exp(-270) \approx 5.5 \times 10^{-118},\) and log values smaller than \(-746\) would be rounded to zero.
Example 3.3 (Calculation of the maximum likelihood of an exponential distribution) As Figure 3.1 reveals that the exponential log likelihood function is unimodal and thus achieves a single maximum, we can use calculus to derive an explicit expression for \(\widehat{\lambda}\) based on the log likelihood \[\begin{align*} \ell(\lambda) = -n \ln\lambda -\frac{1}{\lambda} \sum_{i=1}^n y_i. \end{align*}\] Taking first derivative and setting the result to zero, we find \[\begin{align*} \frac{\mathrm{d} \ell(\lambda)}{\mathrm{d} \lambda} = -\frac{n}{\lambda} + \frac{1}{\lambda^2} \sum_{i=1}^n y_i = 0. \end{align*}\] Rearranging this expression by taking \(-n/\lambda\) to the right hand side of the equality and multiplying both sides by \(\lambda^2>0,\) we find that \(\widehat{\lambda} = \sum_{i=1}^n y_i / n.\) The second derivative of the log likelihood is \(\mathrm{d}^2 \ell(\lambda)/\mathrm{d} \lambda^2 = n(\lambda^{-2} - 2\lambda^{-3}\overline{y}),\) and plugging \(\lambda = \overline{y}\) gives \(-n/\overline{y}^2,\) which is negative. Therefore, \(\widehat{\lambda}\) is indeed a maximizer.
Example 3.4 (Normal samples) Suppose we have an independent normal sample of size \(n\) with mean \(\mu\) and variance \(\sigma^2\), where \(Y_i \sim \mathsf{normal}(\mu, \sigma^2)\) are independent. Recall that the density of the normal distribution is \[\begin{align*} f(y; \mu, \sigma^2)=\frac{1}{(2\pi \sigma^2)^{1/2}}\exp\left\{-\frac{1}{2\sigma^2}(x-\mu)^2\right\}. \end{align*}\] For an simple random sample of size \(n\), whose realization is \(y_1, \ldots, y_n\), the likelihood is \[\begin{align*} L(\mu, \sigma^2; \boldsymbol{y})=&\prod_{i=1}^n\frac{1}{({2\pi \sigma^2})^{1/2}}\exp\left\{-\frac{1}{2\sigma^2}(y_i-\mu)^2\right\}\\ =&(2\pi \sigma^2)^{-n/2}\exp\left\{-\frac{1}{2\sigma^2}\sum_{i=1}^n(y_i-\mu)^2\right\}. \end{align*}\] and the log likelihood is \[\begin{align*} \ell(\mu, \sigma^2; \boldsymbol{y})=-\frac{n}{2}\ln(2\pi) -\frac{n}{2}\ln(\sigma^2)-\frac{1}{2\sigma^2}\sum_{i=1}^n (y_i-\mu)^2. \end{align*}\]
One can show that the maximum likelihood estimators for the two parameters are \[\begin{align*} \widehat{\mu}=\overline{Y}=\frac{1}{n} \sum_{i=1}^n Y_i, \qquad \widehat{\sigma}^2=\frac{1}{n}\sum_{i=1}^n (Y_i-\overline{Y})^2. \end{align*}\]
The fact that the estimator of the theoretical mean \(\mu\) is the sample mean is fairly intuitive and one can show the estimator is unbiased for \(\mu\). The (unbiased) sample variance estimator, \[\begin{align*} S^2=\frac{1}{n-1} \sum_{i=1}^n (Y_i-\overline{Y})^2 \end{align*}\] Since \(\widehat{\sigma}^2=(n-1)/n S^2\), it follows that the maximum likelihood estimator of \(\sigma^2\) is biased, but both estimators are consistent and will thus get arbitrarily close to the true value \(\sigma^2\) for \(n\) sufficiently large.
Proposition 3.1 (Invariance of maximum likelihood estimators) If \(g(\boldsymbol{\theta}): \mathbb{R}^p \mapsto \mathbb{R}^k\) for \(k \leq p\) is a function of the parameter vector, then \(g(\widehat{\boldsymbol{\theta}})\) is the maximum likelihood estimator of the function.
The invariance property explains the widespread use of maximum likelihood estimation. For example, having estimated the parameter \(\lambda,\) we can now use the model to derive other quantities of interest and get the “best” estimates for free. For example, we could compute the maximum likelihood estimate of the probability of waiting more than one minute, \(\Pr(T>60) = \exp(-60/\widehat{\lambda})= 0.126,\) or using R built-in distribution function pexp.
# Note: default R parametrization for the exponential is
# in terms of rate, i.e., the inverse scale parameter
pexp(q = 60, rate = 1/mean(waiting), lower.tail = FALSE)
#> [1] 0.126Another appeal of the invariance property is the possibility to compute the MLE in the most suitable parametrization, which is convenient if the support is restricted. If \(g\) is a one-to-one function of \(\boldsymbol{\theta},\) for example if \(\theta >0,\) taking \(g(\theta) = \ln \theta\) or, if \(0 \leq \theta \leq 1,\) by maximizing \(g(\theta) = \ln(\theta) - \ln(1-\theta) \in \mathbb{R}\) removes the support constraints for the numerical optimization.
Definition 3.3 (Score and information matrix) Let \(\ell(\boldsymbol{\theta}),\) \(\boldsymbol{\theta} \in \boldsymbol{\Theta} \subseteq \mathbb{R}^p,\) be the log likelihood function. The gradient of the log likelihood \(U(\boldsymbol{\theta}) = \partial \ell(\boldsymbol{\theta}) / \partial \boldsymbol{\theta}\) is termed score function.
The observed information matrix is the hessian of the negative log likelihood \[\begin{align*} j(\boldsymbol{\theta}; \boldsymbol{y})=-\frac{\partial^2 \ell(\boldsymbol{\theta}; \boldsymbol{y})}{\partial \boldsymbol{\theta} \partial \boldsymbol{\theta}^\top}, \end{align*}\] evaluated at the maximum likelihood estimate \(\widehat{\boldsymbol{\theta}},\) so \(j(\widehat{\boldsymbol{\theta}}).\) Under regularity conditions, the expected information, also called Fisher information matrix, is \[\begin{align*} i(\boldsymbol{\theta}) = \mathsf{E}\left\{U(\boldsymbol{\theta}; \boldsymbol{Y}) U(\boldsymbol{\theta}; \boldsymbol{Y})^\top\right\} = \mathsf{E}\left\{j(\boldsymbol{\theta}; \boldsymbol{Y})\right\} \end{align*}\] Both the Fisher (or expected) and the observed information matrices are symmetric and encode the curvature of the log likelihood and provide information about the variability of \(\widehat{\boldsymbol{\theta}}.\)
Example 3.5 (Information for the exponential model) The observed and expected information of the exponential model for a random sample \(Y_1, \ldots, Y_n,\) parametrized in terms of scale \(\lambda,\) are \[\begin{align*} j(\lambda; \boldsymbol{y}) &= -\frac{\partial^2 \ell(\lambda)}{\partial \lambda^2} = \frac{n}{\lambda^{2}} + \frac{2}{n\lambda^{3}}\sum_{i=1}^n y_i \\ i(\lambda) &= \frac{n}{\lambda^{2}} + \frac{2}{n\lambda^{3}}\sum_{i=1}^n \mathsf{E}(Y_i) = \frac{n}{\lambda^{2}} \end{align*}\] since \(\mathsf{E}(Y_i) = \lambda\) and expectation is a linear operator.
We find \(i(\widehat{\lambda}) = j(\widehat{\lambda}) = n/\overline{y}^2\).
The exponential model may be restrictive for our purposes, so we consider for the purpose of illustration and as a generalization a Weibull distribution.
Definition 3.4 (Weibull distribution) The distribution function of a Weibull random variable with scale \(\lambda>0\) and shape \(\alpha>0\) is \[\begin{align*} F(x; \lambda, \alpha) &= 1 - \exp\left\{-(x/\lambda)^\alpha\right\}, \qquad x \geq 0, \lambda>0, \alpha>0, \end{align*}\] while the corresponding density is \[\begin{align*} f(x; \lambda, \alpha) &= \frac{\alpha}{\lambda^\alpha} x^{\alpha-1}\exp\left\{-(x/\lambda)^\alpha\right\}, \qquad x \geq 0, \lambda>0, \alpha>0. \end{align*}\] The quantile function, the inverse of the distribution function, is \(Q(p) = \lambda\{-\ln(1-p)\}^{1/\alpha}.\) The Weibull distribution includes the exponential as special case when \(\alpha=1.\) The expected value of \(Y \sim \mathsf{Weibull}(\lambda, \alpha)\) is \(\mathsf{E}(Y) = \lambda \Gamma(1+1/\alpha).\)
Example 3.6 (Score and information of the Weibull distribution) The log likelihood for a simple random sample whose realizations are \(y_1, \ldots, y_n\) of size \(n\) from a \(\mathsf{Weibull}(\lambda, \alpha)\) model is \[\begin{align*} \ell(\lambda, \alpha) = n \ln(\alpha) - n\alpha\ln(\lambda) + (\alpha-1) \sum_{i=1}^n \ln y_i - \lambda^{-\alpha}\sum_{i=1}^n y_i^\alpha. \end{align*}\] The score, which is the gradient of the log likelihood, is easily obtained by differentiation3 \[\begin{align*} U(\lambda, \alpha) &= \begin{pmatrix}\frac{\partial \ell(\lambda, \alpha)}{\partial \lambda} \\ \frac{\partial \ell(\lambda, \alpha)}{\partial \alpha} \end{pmatrix} \\&= \begin{pmatrix} -\frac{n\alpha}{\lambda} +\alpha\lambda^{-\alpha-1}\sum_{i=1}^n y_i^\alpha \\ \frac{n}{\alpha} + \sum_{i=1}^n \ln (y_i/\lambda) - \sum_{i=1}^n \left(\frac{y_i}{\lambda}\right)^{\alpha} \times\ln\left(\frac{y_i}{\lambda}\right). \end{pmatrix} \end{align*}\] and the observed information is the \(2 \times 2\) matrix-valued function \[\begin{align*} j(\lambda, \alpha) &= - \begin{pmatrix} \frac{\partial^2 \ell(\lambda, \alpha)}{\partial \lambda^2} & \frac{\partial^2 \ell(\lambda, \alpha)}{\partial \lambda \partial \alpha} \\ \frac{\partial^2 \ell(\lambda, \alpha)}{\partial \alpha \partial \lambda} & \frac{\partial^2 \ell(\lambda, \alpha)}{\partial \alpha^2} \end{pmatrix} = \begin{pmatrix} j_{\lambda, \lambda} & j_{\lambda, \alpha} \\ j_{\lambda, \alpha} & j_{\alpha, \alpha} \end{pmatrix} \end{align*}\] whose entries are \[\begin{align*} j_{\lambda, \lambda} &= \lambda^{-2}\left\{-n\alpha + \alpha(\alpha+1)\sum_{i=1}^n (y_i/\lambda)^\alpha\right\} \\ j_{\lambda, \alpha} &= \lambda^{-1}\sum_{i=1}^n [1-(y_i/\lambda)^\alpha\{1+\alpha\ln(y_i/\lambda)\}] \\ j_{\alpha,\alpha} &= n\alpha^{-2} + \sum_{i=1}^n (y_i/\lambda)^\alpha \{\ln(y_i/\lambda)\}^2 \end{align*}\] To compute the expected information matrix, we need to compute expectation of \(\mathsf{E}\{(Y/\lambda)^\alpha\}\), \(\mathsf{E}[(Y/\lambda)^\alpha\ln\{(Y/\lambda)^\alpha\}]\) and \(\mathsf{E}[(Y/\lambda)^\alpha\ln^2\{(Y/\lambda)^\alpha\}]\). By definition, \[\begin{align*} \mathsf{E}\left\{(Y/\lambda)^\alpha\right\} & = \int_0^\infty (x/\lambda)^\alpha \frac{\alpha}{\lambda^\alpha} x^{\alpha-1}\exp\left\{-(x/\lambda)^\alpha\right\} \mathrm{d} x \\ &= \int_0^\infty s\exp(-s) \mathrm{d} s =1 \end{align*}\] making a change of variable \(S = (Y/\lambda)^\alpha\sim \mathsf{Exp}(1)\). The two other integrals are tabulated in Gradshteyn and Ryzhik (2014), and are equal to \(1-\gamma\) and \(\gamma^2-2\gamma + \pi^2/6\), respectively, where \(\gamma \approx 0.577\) is the Euler–Mascherroni constant. The expected information matrix of the Weibull distribution has entries \[\begin{align*} i_{\lambda, \lambda} & = n \lambda^{-2}\alpha\left\{ (\alpha+1)-1\right\} \\ i_{\lambda, \alpha} & = -n\lambda^{-1} (1-\gamma) \\ i_{\alpha, \alpha} & = n\alpha^{-2}(1 + \gamma^2-2\gamma+\pi^2/6) \end{align*}\] The information of an independent and identically distributed sample of size \(n\) is \(n\) times that of a single observation, so information accumulates at a linear rate.
Proposition 3.2 (Gradient-based optimization) To obtain the maximum likelihood estimator, we will typically find the value of the vector \(\boldsymbol{\theta}\) that solves the score vector, meaning \(U(\widehat{\boldsymbol{\theta}})=\boldsymbol{0}_p.\) This amounts to solving simultaneously a \(p\)-system of equations by setting the derivative with respect to each element of \(\boldsymbol{\theta}\) to zero. If \(j(\widehat{\boldsymbol{\theta}})\) is a positive definite matrix (i.e., all of it’s eigenvalues are positive), then the vector \(\widehat{\boldsymbol{\theta}}\) is the maximum likelihood estimator.
We can use a variant of Newton–Raphson algorithm if the likelihood is thrice differentiable and the maximum likelihood estimator does not lie on the boundary of the parameter space. If we consider an initial value \(\boldsymbol{\theta}^{\dagger},\) then a first order Taylor series expansion of the score likelihood in a neighborhood \(\boldsymbol{\theta}^{\dagger}\) of the MLE \(\widehat{\boldsymbol{\theta}}\) gives \[\begin{align*}
\boldsymbol{0}_p & = U(\widehat{\boldsymbol{\theta}}) \stackrel{\cdot}{\simeq} \left.
\frac{\partial \ell(\boldsymbol{\theta})}{\partial \boldsymbol{\theta}} \right|_{\boldsymbol{\theta} = \boldsymbol{\theta}^{\dagger}} + \left.
\frac{\partial^2 \ell(\boldsymbol{\theta})}{\partial \boldsymbol{\theta} \partial \boldsymbol{\theta}^\top}\right|_{\boldsymbol{\theta} = \boldsymbol{\theta}^{\dagger}}(\widehat{\boldsymbol{\theta}} - \boldsymbol{\theta}^{\dagger})\\&=U(\boldsymbol{\theta}^{\dagger}) - j(\boldsymbol{\theta}^{\dagger})(\widehat{\boldsymbol{\theta}} - \boldsymbol{\theta}^{\dagger})
\end{align*}\] and solving this for \(\widehat{\boldsymbol{\theta}}\) (provided the \(p \times p\) matrix \(j(\widehat{\boldsymbol{\theta}})\) is invertible), we get \[\begin{align*}
\widehat{\boldsymbol{\theta}} \stackrel{\cdot}{\simeq} \boldsymbol{\theta}^{\dagger} +
j^{-1}(\boldsymbol{\theta}^{\dagger})U(\boldsymbol{\theta}^{\dagger}),
\end{align*}\] which suggests an iterative procedure from a starting value \(\boldsymbol{\theta}^{\dagger}\) in the vicinity of the mode until the gradient is approximately zero. If the value is far from the mode, then the algorithm may diverge to infinity. To avoid this, we may multiply the term \(j^{-1}(\boldsymbol{\theta}^{\dagger})U(\boldsymbol{\theta}^{\dagger})\) by a damping factor \(c<1.\) A variant of the algorithm, termed Fisher scoring, uses the expected or Fisher information \(i(\boldsymbol{\theta})\) in place of the observed information, \(j(\boldsymbol{\theta}),\) for numerical stability and to avoid situations where the latter is not positive definite. This is the optimization routine used in the glm function in R.
Example 3.7 (Maximum likelihood of a Weibull sample) We turn to numerical optimization to obtain the maximum likelihood estimate of the Weibull distribution, in the absence of closed-form expression for the MLE. To this end, we create functions that encode the log likelihood, here taken as the sum of log density contributions. The function nll_weibull below takes as argument the vector of parameters, pars, and returns the negative of the log likelihood which we wish to minimize4 We also code the gradient, although we can resort to numerical differentiation at little additional costs. We then use optim, the default optimization routine in R, to minimize nll_weibull. The function returns a list containing a convergence code (0 indicating convergence), the MLE in par, the log likelihood \(\ell(\widehat{\boldsymbol{\theta}})\) and the Hessian matrix, which is the matrix of second derivatives of the negative log likelihood evaluated at \(\widehat{\boldsymbol{\theta}}.\) The log likelihood surface, for pairs of scale and shape vectors \(\boldsymbol{\theta} = (\lambda, \alpha),\) are displayed in Figure 3.3. We can see that the maximum likelihood value has converged, and check that the score satisfies \(U(\widehat{\boldsymbol{\theta}}) = 0\) at the returned optimum value.
Code
# Load data vector
data(waiting, package = "hecstatmod")
# Negative log likelihood for a Weibull sample
nll_weibull <- function(pars, y){
# Handle the case of negative parameter values
if(isTRUE(any(pars <= 0))){ # parameters must be positive
return(1e10) # large value (not infinite, to avoid warning messages)
}
- sum(dweibull(x = y, scale = pars[1], shape = pars[2], log = TRUE))
}
# Gradient of the negative Weibull log likelihood
gr_nll_weibull <- function(pars, y){
scale <- pars[1]
shape <- pars[2]
n <- length(y)
grad_ll <- c(scale = -n*shape/scale + shape*scale^(-shape-1)*sum(y^shape),
shape = n/shape - n*log(scale) + sum(log(y)) -
sum(log(y/scale)*(y/scale)^shape))
return(- grad_ll)
}
# Use exponential submodel MLE as starting parameters
start <- c(mean(waiting), 1)
# Check gradient function is correctly coded!
# Returns TRUE if numerically equal to tolerance
isTRUE(all.equal(numDeriv::grad(nll_weibull, x = start, y = waiting),
gr_nll_weibull(pars = start, y = waiting),
check.attributes = FALSE))
#> [1] TRUE
# Numerical minimization using optim
opt_weibull <- optim(
par = start, # starting values
fn = nll_weibull, # pass function, whose first argument is the parameter vector
gr = gr_nll_weibull, # optional (if missing, numerical derivative)
method = "BFGS", # gradient-based algorithm, common alternative is "Nelder"
y = waiting, # vector of observations, passed as additional argument to fn
hessian = TRUE) # return matrix of second derivatives evaluated at MLE
# Alternative using pure Newton
# nlm(f = nll_weibull, p = start, hessian = TRUE, y = waiting)
# Parameter estimates - MLE
(mle_weibull <- opt_weibull$par)
#> [1] 32.6 2.6
# Check gradient for convergence
gr_nll_weibull(mle_weibull, y = waiting)
#> scale shape
#> 0.0000142 0.0001136
# Is the Hessian of the negative positive definite (all eigenvalues are positive)
# If so, we found a maximum and the matrix is invertible
isTRUE(all(eigen(opt_weibull$hessian)$values > 0))
#> [1] TRUE3.2 Sampling distribution
The sampling distribution of an estimator \(\widehat{\boldsymbol{\theta}}\) is the probability distribution induced by the underlying data, given that the latter inputs are random.
For simplicity, suppose we have a simple random sample, so the log likelihood is a sum of \(n\) terms and information accumulates linearly with the sample size: the data carry more information about the unknown parameter vector, whose true value we denote \(\boldsymbol{\theta}_0.\) Under suitable regularity conditions, cf. Section 4.4.2 of Davison (2003), for large sample size \(n,\) we can perform a Taylor series of the score vector and apply the central limit theorem. Since \(U(\boldsymbol{\theta})\) and \(i(\boldsymbol{\theta})\) are the sum of \(n\) independent random variables, and that \(\mathsf{E}\{U(\boldsymbol{\theta})\}=\boldsymbol{0}_p,\) and \(\mathsf{Var}\{U(\boldsymbol{\theta})\}=i(\boldsymbol{\theta}),\) application of the central limit theorem yields \[\begin{align*} i(\boldsymbol{\theta}_0)^{-1/2}U(\boldsymbol{\theta}_0) \stackrel{\cdot}{\sim}\mathsf{normal}_p(\boldsymbol{0}, \mathbf{I}_p). \end{align*}\]
We can use this to obtain approximations to the sampling distribution of \(\widehat{\boldsymbol{\theta}},\) given that \[\begin{align*} \widehat{\boldsymbol{\theta}} \stackrel{\cdot}{\sim} \mathsf{normal}_p\{\boldsymbol{\theta}_0, i^{-1}(\boldsymbol{\theta})\} \end{align*}\] where the covariance matrix is the inverse of the Fisher information. In practice, since the true parameter value \(\boldsymbol{\theta}_0\) is unknown, we replace it with either \(i^{-1}(\widehat{\boldsymbol{\theta}})\) or the inverse of the observed information \(j^{-1}(\widehat{\boldsymbol{\theta}}),\) as both of these converge to the true value.
As the sample size grows, the \(\widehat{\boldsymbol{\theta}}\) becomes centered around the value \(\boldsymbol{\theta}_0\) that minimizes the discrepancy between the model and the true data generating process. In large samples, the sampling distribution of the maximum likelihood estimator is approximately quadratic.
Example 3.8 (Covariance matrix and standard errors for the Weibull distribution) We use the output of our optimization procedure to get the observed information matrix and the standard errors for the parameters of the Weibull model. The latter are simply the square root of the diagonal entries of the inverse Hessian matrix, \([\mathrm{diag}\{j^{-1}(\widehat{\boldsymbol{\theta}})\}]^{1/2}\).
# The Hessian matrix of the negative log likelihood
# evaluated at the MLE (observed information matrix)
obsinfo_weibull <- opt_weibull$hessian
vmat_weibull <- solve(obsinfo_weibull)
# Standard errors
se_weibull <- sqrt(diag(vmat_weibull))From these, one can readily Wald-based confidence intervals for parameters from \(\boldsymbol{\theta}.\)
Proposition 3.3 (Asymptotic normality and transformations) The asymptotic normality result can be used to derive standard errors for other quantities of interest. If \(\phi = g(\boldsymbol{\theta})\) is a differentiable function of \(\boldsymbol{\theta}\) whose gradient does not vanish at \(\widehat{\boldsymbol{\theta}}\) then \(\widehat{\phi} \stackrel{\cdot}{\sim}\mathsf{normal}(\phi_0, \mathrm{V}_\phi),\) with \(\mathrm{V}_\phi = \nabla \phi^\top \mathbf{V}_{\boldsymbol{\theta}} \nabla \phi,\) where \(\nabla \phi=[\partial \phi/\partial \theta_1, \ldots, \partial \phi/\partial \theta_p]^\top.\) The variance matrix and the gradient are evaluated at the maximum likelihood estimate \(\widehat{\boldsymbol{\theta}}.\) This result readily extends to vector \(\boldsymbol{\phi} \in \mathbb{R}^k\) for \(k \leq p,\) where \(\mathrm{V}_\phi\)is the Jacobian matrix of the transformation.
Example 3.9 (Probability of waiting for exponential model.) To illustrate the difference between likelihood ratio and Wald tests (and their respective confidence intervals), we consider the metro waiting time data and consider the probability of waiting more than one minute, \(\phi=g(\lambda) = \exp(-60/\lambda).\) The maximum likelihood estimate is, by invariance, \(0.126\) and the gradient of \(g\) with respect to the scale parameter is \(\nabla \phi = \partial \phi / \partial \lambda = 60\exp(-60/\lambda)/\lambda^2.\)
lambda_hat <- mean(waiting)
phi_hat <- exp(-60/lambda_hat)
dphi <- function(lambda){60*exp(-60/lambda)/(lambda^2)}
V_lambda <- lambda_hat^2/length(waiting)
V_phi <- dphi(lambda_hat)^2 * V_lambda
(se_phi <- sqrt(V_phi))
#> [1] 0.03313.3 Likelihood-based tests
We consider a null hypothesis \(\mathscr{H}_0\) that imposes restrictions on the possible values of \(\boldsymbol{\theta}\) can take, relative to an unconstrained alternative \(\mathscr{H}_1.\) We need two nested models: a full model, and a reduced model that is a subset of the full model where we impose \(q\) restrictions. For example, the exponential distribution is a special case of the Weibull one if \(\alpha=1\). The testing procedure involves fitting the two models and obtaining the maximum likelihood estimators of each of \(\mathscr{H}_1\) and \(\mathscr{H}_0,\) respectively \(\widehat{\boldsymbol{\theta}}\) and \(\widehat{\boldsymbol{\theta}}_0\) for the parameters under \(\mathscr{H}_0.\) The null hypothesis \(\mathscr{H}_0\) tested is: `the reduced model is an adequate simplification of the full model’ and the likelihood provides three main classes of statistics for testing this hypothesis: these are
- likelihood ratio tests statistics, denoted \(R,\) which measure the drop in log likelihood (vertical distance) from \(\ell(\widehat{\boldsymbol{\theta}})\) and \(\ell(\widehat{\boldsymbol{\theta}}_0).\)
- Wald tests statistics, denoted \(W,\) which consider the standardized horizontal distance between \(\widehat{\boldsymbol{\theta}}\) and \(\widehat{\boldsymbol{\theta}}_0.\)
- score tests statistics, denoted \(S,\) which looks at the scaled slope of \(\ell,\) evaluated only at \(\widehat{\boldsymbol{\theta}}_0\) (derivative of \(\ell\)).
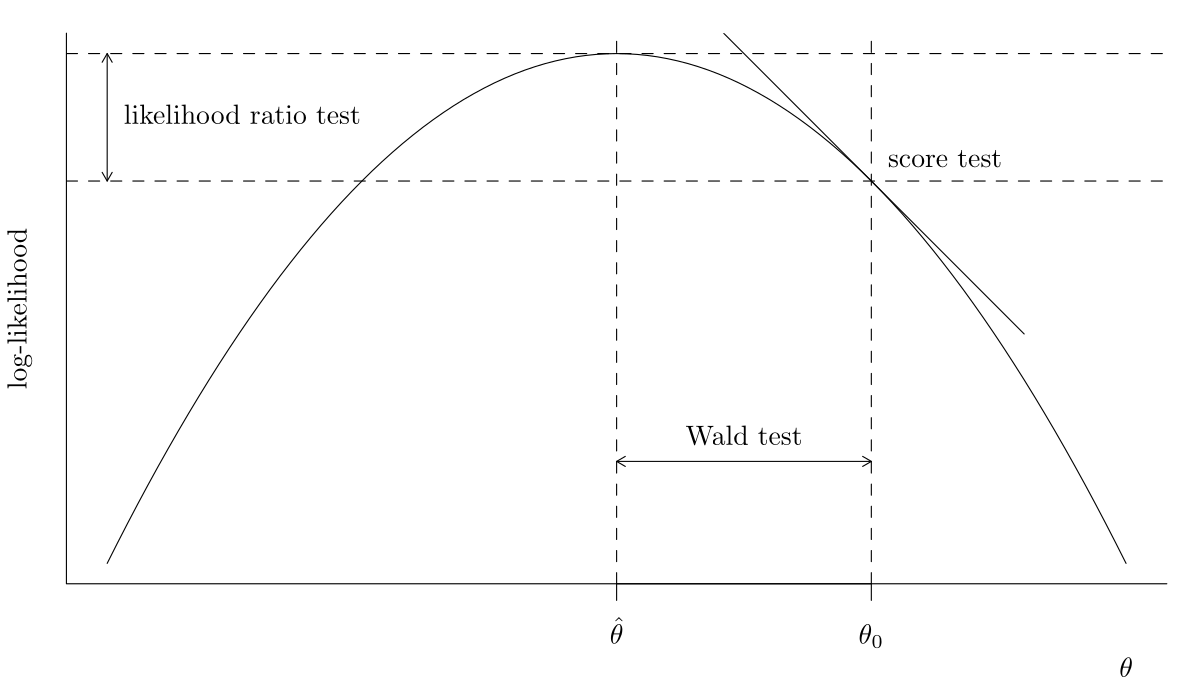
The three main classes of statistics for testing a simple null hypothesis \(\mathscr{H}_0: \boldsymbol{\theta}=\boldsymbol{\theta}_0\) against the alternative \(\mathscr{H}_a: \boldsymbol{\theta} \neq \boldsymbol{\theta}_0\) are the Wald (denoted \(W\)), likelihood ratio (\(R\)), and the score (\(S\)) test statistics, defined respectively as \[\begin{align*} W &= (\widehat{\boldsymbol{\theta}}-\boldsymbol{\theta}_0)^\top j(\widehat{\boldsymbol{\theta}})(\widehat{\boldsymbol{\theta}}-\boldsymbol{\theta}_0), \\ R &= 2 \left\{ \ell(\widehat{\boldsymbol{\theta}})-\ell(\boldsymbol{\theta}_0)\right\}, \\ S &= U^\top(\boldsymbol{\theta}_0)i^{-1}(\boldsymbol{\theta}_0)U(\boldsymbol{\theta}_0), \\ \end{align*}\] where \(\widehat{\boldsymbol{\theta}}\) is the maximum likelihood estimate under the alternative and \(\boldsymbol{\theta}_0\) is the null value of the parameter vector. Asymptotically, all the test statistics are equivalent (in the sense that they lead to the same conclusions about \(\mathscr{H}_0\)).
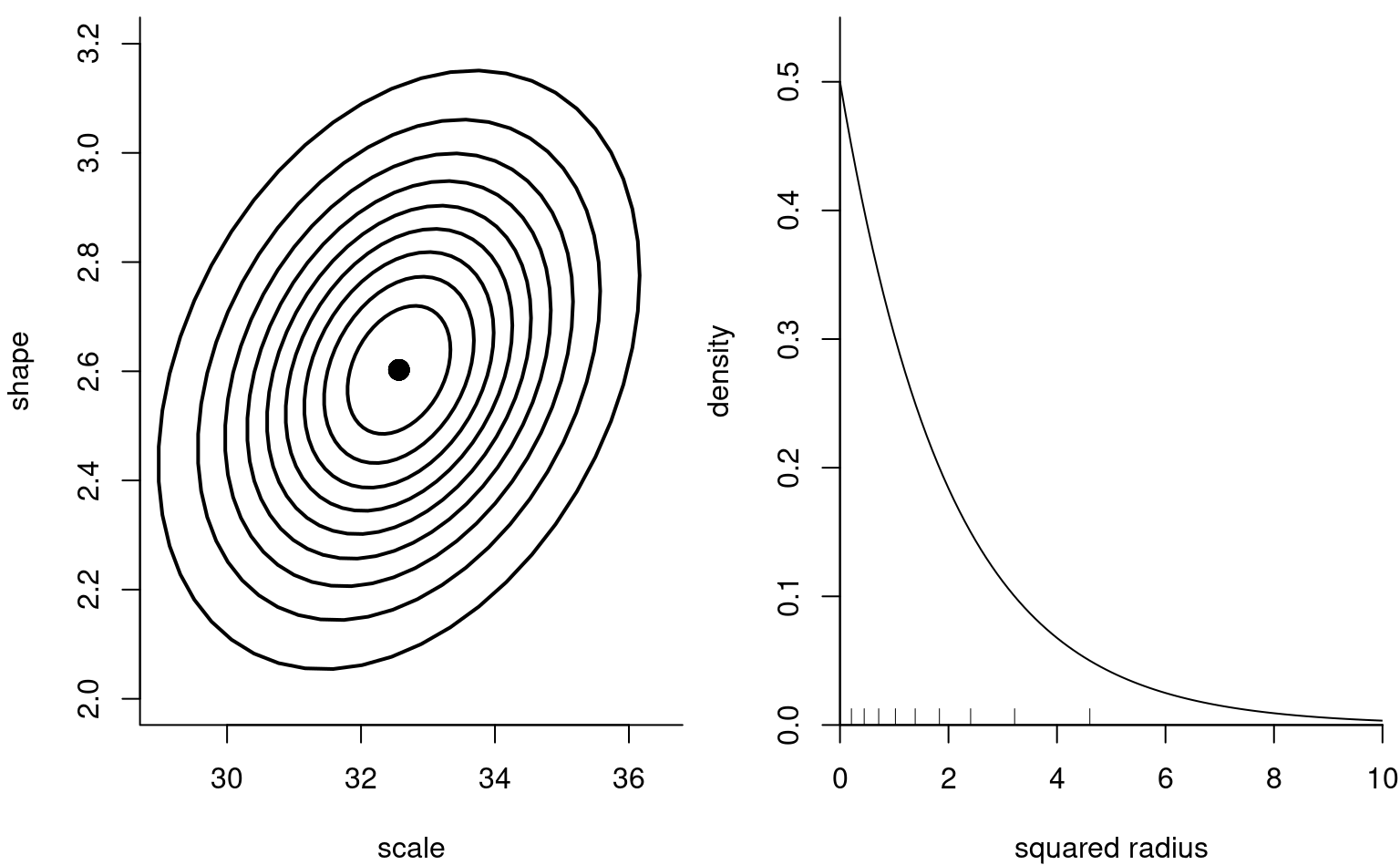
Remark 3.1 (Testing procedures and quadratic forms). The null distribution of the maximum likelihood estimator (and related quantities) is useful for testing, albeit not in this form. Consider for simplicity the case where we have \(p=2\) dimensional parameter (e.g., a Weibull distribution) and we impose \(q=2\) restrictions; we consider for simplicity a Wald-type test. The asymptotic distribution of the maximum likelihood estimator is \(\widehat{\boldsymbol{\theta}} \stackrel{\cdot}{\sim} \mathsf{normal}_p\{\boldsymbol{\theta}, i^{-1}(\boldsymbol{\theta})\}\), and we can obtain confidence ellipse for the MLE by replacing Fisher information \(i(\boldsymbol{\theta})\) by a convergent estimator \(j(\widehat{\boldsymbol{\theta}})\): we then obtain the left panel of Figure 3.2.
If we postulate \(\boldsymbol{\theta} = \boldsymbol{\theta}_0\), it suffices to consider where the pair falls on the plot and find the level of the ellipse that intersects with the point. This however is complicated: rather, we can standardize the variable to \(\boldsymbol{\vartheta} =j^{1/2}(\widehat{\boldsymbol{\theta}})(\widehat{\boldsymbol{\theta}}-\boldsymbol{\theta}_0)\), where now the contour curves are circular. To reduce the problem from a two-dimensional problem to a one-dimensional, we consider the squared radius \(W = \vartheta_1^2 + \vartheta_2^2 = (\widehat{\boldsymbol{\theta}}-\boldsymbol{\theta}_0)^\top j(\widehat{\boldsymbol{\theta}})(\widehat{\boldsymbol{\theta}}-\boldsymbol{\theta}_0)\), which is approximately \(\chi^2_2\) in large sample, as shown in the right panel of Figure 3.2. It is much easier to determine whether the value is large based on the radius.
If \(\mathscr{H}_0\) is true, the three test statistics follow asymptotically a \(\chi^2_q\) distribution under a null hypothesis \(\mathscr{H}_0,\) where the degrees of freedom \(q\) are the number of restrictions. \[\begin{align*} w(\theta_0)&=(\widehat{\theta}-\theta_0)/\mathsf{se}(\widehat{\theta}) \\ r({\theta_0}) &= \mathrm{sign}(\widehat{\theta}-\theta)\left[2 \left\{\ell(\widehat{\theta})-\ell(\theta)\right\}\right]^{1/2} \\ s(\theta_0)&=j^{-1/2}(\theta_0)U(\theta_0) \end{align*}\] We call \(r({\theta_0})\) the directed likelihood root.
The likelihood ratio test statistic is normally the most powerful of the three likelihood tests. The score statistic \(S\) only requires calculation of the score and information under \(\mathscr{H}_0\) (because by definition \(U(\widehat{\theta})=0\)), so it can be useful in problems where calculations of the maximum likelihood estimator under the alternative is costly or impossible.
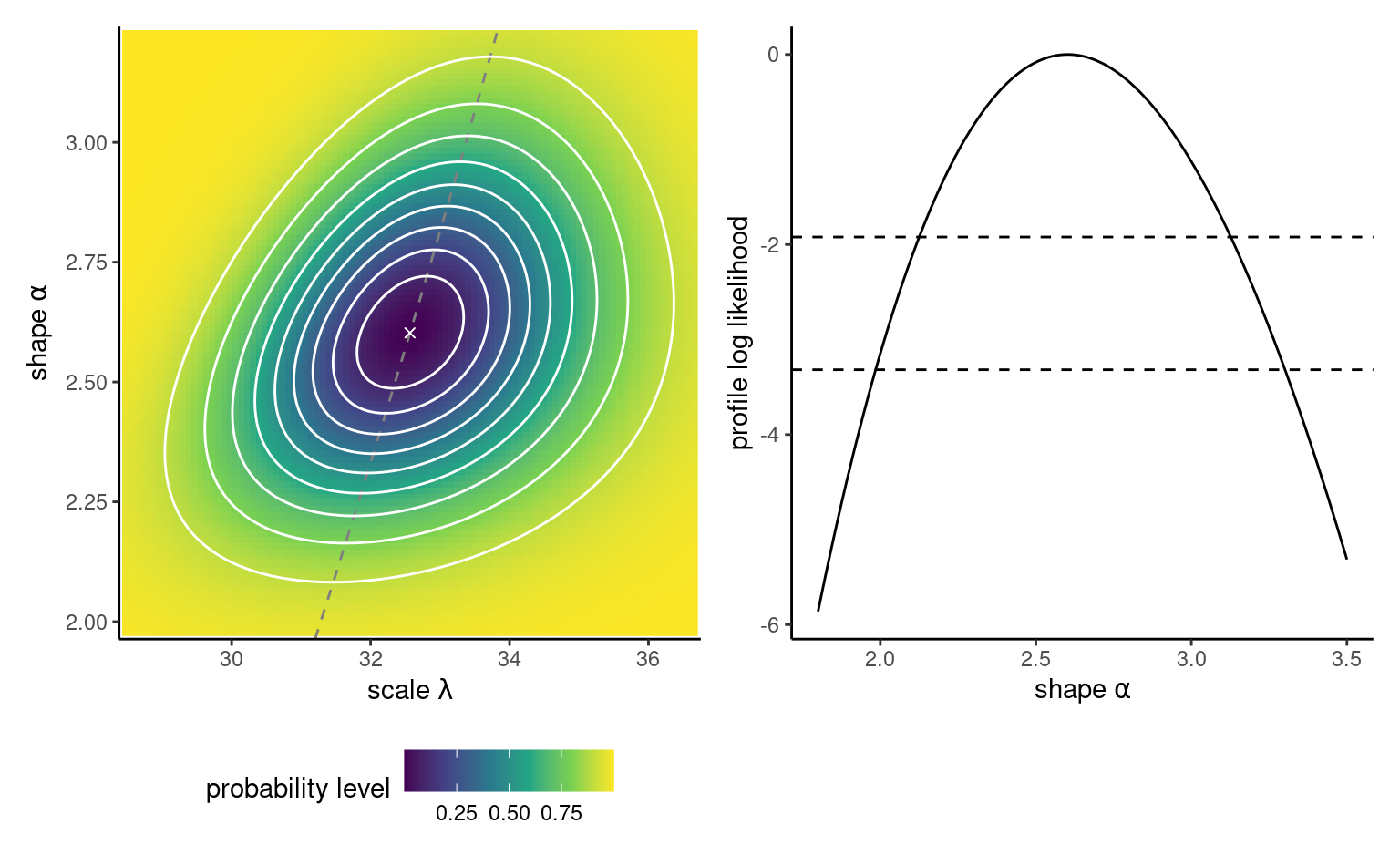
waiting data with 10%, 20%, , 90% likelihood ratio confidence regions (white contour curves). Higher log likelihood values are indicated by darker colors. The cross indicates the maximum likelihood estimate. The profile on the right hand panel has been shifted vertically to be zero at the MLE; the dashed horizontal lines denote the cutoff points for the 95% and 99% confidence intervals.
The Wald statistic \(W\) is the most widely encountered statistic and two-sided 95% confidence intervals for a single parameter \(\theta\) are of the form \[\begin{align*} \widehat{\theta} \pm \mathfrak{z}_{1-\alpha/2}\mathrm{se}(\widehat{\theta}), \end{align*}\] where \(\mathfrak{z}_{1-\alpha/2}\) is the \(1-\alpha/2\) quantile of the standard normal distribution; for a \(95\)% confidence interval, the \(0.975\) quantile of the normal distribution is \(\mathfrak{z}_{0.975}=1.96.\) The Wald-based confidence intervals are by construction symmetric: they may include implausible values (e.g., negative values for if the parameter of interest \(\theta\) is positive, such as variances).
Example 3.10 (Wald test to compare exponential and Weibull models) We can test whether the exponential model is an adequate simplification of the Weibull distribution by imposing the restriction \(\mathscr{H}_0: \alpha=1\). This imposes a single restriction to the model, so we compare the square statistic to a \(\chi^2_1\). Since \(\alpha\) is directly a parameter of the distribution, we have the standard errors for free.
# Calculate Wald statistic
wald_exp <- (mle_weibull[2] - 1)/se_weibull[2]
# Compute p-value
pchisq(wald_exp^2, df = 1, lower.tail = FALSE)
#> [1] 3.61e-10
# p-value less than 5%, reject null
# Obtain 95% confidence intervals
mle_weibull[2] + qnorm(c(0.025, 0.975))*se_weibull[2]
#> [1] 2.1 3.1
# 1 is not inside the confidence interval, reject nullWe reject the null hypothesis, meaning the exponential submodel is not an adequate simplification of the Weibull.
We can also check the goodness-of-fit of both models by drawing a quantile-quantile plot (cf. Definition 1.17). It is apparent from Figure 3.4 that the exponential model is overestimating the largest waiting times, whose dispersion in the sample is less than that implied by the model. By contrast, the near perfect straight line for the Weibull model in the right panel of Figure 3.4 suggests that the model fit is adequate.
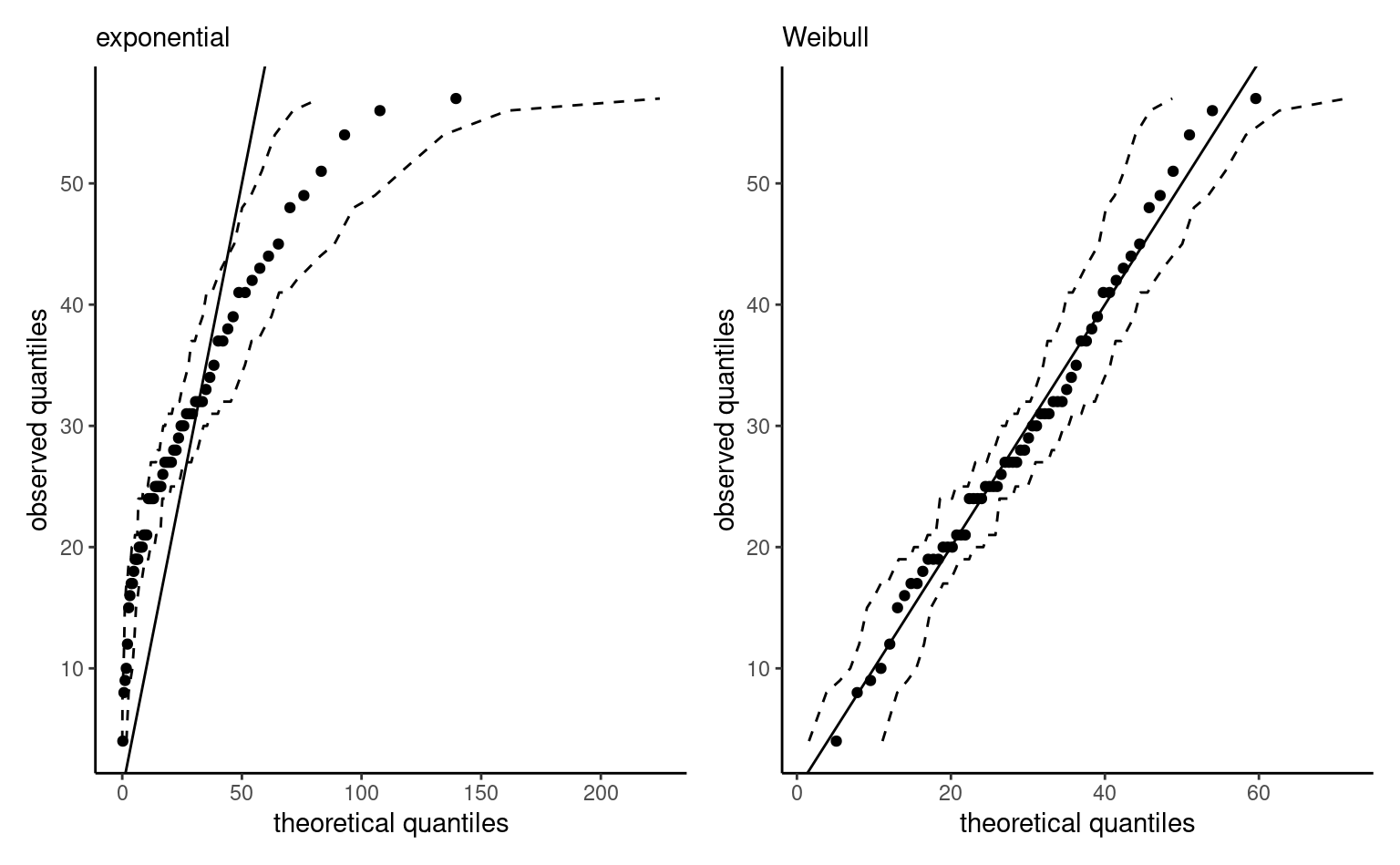
Remark 3.2 (Lack of invariance of Wald-based confidence intervals). The Wald-based confidence intervals are not parametrization invariant: if we want intervals for a nonlinear continuous function \(g(\theta),\) then in general \(\mathsf{CI}_{W}\{g(\theta)\} \neq g\{\mathsf{CI}_{W}(\theta)\}.\)
For example, consider the exponential submodel. We can invert the Wald test statistic to get a symmetric 95% confidence interval for \(\phi,\) \([0.061,\) \(0.191].\) If we were to naively transform the confidence interval for \(\lambda\) into one for \(\phi,\) we would get \([0.063,\) \(0.19],\) which highlights the invariance although the difference here is subtle. The Gaussian approximation underlying the Wald test is reliable if the sampling distribution of the likelihood is near quadratic, which happens when the likelihood function is roughly symmetric on either side of the maximum likelihood estimator.
The likelihood ratio test is invariant to interest-preserving reparametrizations, so the test statistic for \(\mathscr{H}_0: \phi=\phi_0\) and \(\mathscr{H}_0: \lambda = -60/\ln(\phi_0)\) are the same. The Wald confidence regions can be contrasted with the (better) ones derived using the likelihood ratio test: these are found through a numerical search to find the limits of \[\begin{align*} \left\{\theta: 2\{\ell(\widehat{\boldsymbol{\theta}}) - \ell(\boldsymbol{\theta})\} \leq \chi^2_p(1-\alpha)\right\}, \end{align*}\] where \(\chi^2_p(1-\alpha)\) is the \((1-\alpha)\) quantile of the \(\chi^2_p\) distribution. Such intervals, for \(\alpha = 0.1, \ldots, 0.9\), appear in Figure 3.3 as contour curves. If \(\boldsymbol{\theta}\) is multidimensional, confidence intervals for \(\theta_i\) are derived using the profile likelihood, discussed in the sequel. Likelihood ratio-based confidence intervals are parametrization invariant, so \(\mathsf{CI}_{R}\{g(\theta)\} = g\{\mathsf{CI}_{R}(\theta)\}.\) Because the likelihood is zero if a parameter value falls outside the range of possible values for the parameter, the intervals only include plausible values of \(\theta.\) In general, the intervals are asymmetric and have better coverage properties.
# Exponential log likelihood
ll_exp <- function(lambda){
sum(dexp(waiting, rate = 1/lambda, log = TRUE))
}
# MLE of the scale parameter
lambda_hat <- mean(waiting)
# Root search for the limits of the confidence interval
lrt_lb <- uniroot( # lower bound, using values below MLE
f = function(r){
2*(ll_exp(lambda_hat) - ll_exp(r)) - qchisq(0.95, 1)},
interval = c(0.5 * min(waiting), lambda_hat))$root
lrt_ub <- uniroot( # upper bound,
f = function(r){
2*(ll_exp(lambda_hat) - ll_exp(r)) - qchisq(0.95, 1)},
interval = c(lambda_hat, 2 * max(waiting)))$rootThe likelihood ratio statistic 95% confidence interval for \(\phi\) can be found by using a root finding algorithm: the 95% confidence interval for \(\lambda\) is \(\mathsf{CI}_R(\lambda)[22.784,\) \(37.515].\) By invariance, the 95% confidence interval for \(\phi\) is \(\mathsf{CI}_R(\phi) = [0.072, 0.202] = g \{\mathsf{CI}_R(\lambda)\}.\)
3.4 Profile likelihood
Sometimes, we may want to perform hypothesis test or derive confidence intervals for selected components of the model. In this case, the null hypothesis only restricts part of the space and the other parameters, termed nuisance, are left unspecified — the question then is what values to use for comparison with the full model. It turns out that the values that maximize the constrained log likelihood are what one should use for the test, and the particular function in which these nuisance parameters are integrated out is termed a profile likelihood.
Definition 3.5 (Profile log likelihood) Consider a parametric model with log likelihood function \(\ell(\boldsymbol{\theta})\) whose \(p\)-dimensional parameter vector \(\boldsymbol{\theta}=(\boldsymbol{\psi}, \boldsymbol{\varphi})\) can be decomposed into a \(q\)-dimensional parameter of interest \(\boldsymbol{\psi}\) and a \((p-q)\)-dimensional nuisance vector \(\boldsymbol{\varphi}.\)
The profile likelihood \(\ell_{\mathsf{p}},\) a function of \(\boldsymbol{\psi}\) alone, is obtained by maximizing the likelihood pointwise at each fixed value \(\boldsymbol{\psi}_0\) over the nuisance vector \(\boldsymbol{\varphi}_{\psi_0},\) \[\begin{align*} \ell_{\mathsf{p}}(\boldsymbol{\psi})=\max_{\boldsymbol{\varphi}}\ell(\boldsymbol{\psi}, \boldsymbol{\varphi})=\ell(\boldsymbol{\psi}, \widehat{\boldsymbol{\varphi}}_{\boldsymbol{\psi}}). \end{align*}\]
Example 3.11 (Profile log likelihood for the Weibull shape parameter) Consider the shape parameter \(\psi \equiv\alpha\) as parameter of interest, and the scale \(\varphi\equiv\lambda\) as nuisance parameter. Using the gradients derived in Example 3.7, we find that the value of the scale that maximizes the log likelihood for given \(\alpha\) is \[\begin{align*} \widehat{\lambda}_\alpha = \left( \frac{1}{n}\sum_{i=1}^n y_i^\alpha\right)^{1/\alpha}. \end{align*}\] and plugging in this value gives a function of \(\alpha\) alone, thereby also reducing the optimization problem for the Weibull to a line search along \(\ell_{\mathsf{p}}(\alpha)\). The left hand panel of Figure 3.3 shows the ridge along the direction of \(\alpha\) corresponding to the log likelihood surface. If one thinks of these contours lines as those of a topographic map, the profile likelihood corresponds in this case to walking along the ridge of both mountains along the \(\psi\) direction, with the right panel showing the elevation gain/loss. The corresponding elevation profile on the right of Figure 3.3 with cutoff values. We would need to obtain numerically using a root finding algorithm the limits of the confidence interval on either side of \(\widehat{\alpha}\), but it’s clear that \(\alpha=1\) is not inside the 99% interval.
lambda_alpha <- function(alpha, y = waiting){
(mean(y^alpha))^(1/alpha)
}
# Profile likelihood for alpha
prof_alpha_weibull <- function(par, y = waiting){
sapply(par, function(a){
nll_weibull(pars = c(lambda_alpha(a), a), y = y)
})
}Example 3.12 (Score and likelihood ratio tests for comparing exponential vs Weibull models) We can proceed similarly with the score test, using the expected information matrix formula derived earlier. Under the null model \(\alpha=1\) and we get that the constrained MLE for the scale is the sample mean \(\overline{y}\).
Code
## Score test
# Expected information matrix - one observation
info_weib <- function(scale, shape){
i11 <- shape*((shape + 1) - 1)/(scale^2)
i12 <- -(1+digamma(1))/scale
i22 <- (1+digamma(1)^2+2*digamma(1)+pi^2/6)/(shape^2)
matrix(c(i11, i12, i12, i22), nrow = 2, ncol = 2)
}
# Score statistic
score_stat <- function(scale, shape, xdat){
score_w <- -gr_nll_weibull(c(scale, shape), y = xdat)
finfo_w <- length(xdat)*info_weib(scale, shape)
as.numeric(t(score_w) %*% solve(finfo_w) %*% score_w)
}
S <- score_stat(scale = mean(waiting), shape = 1, xdat = waiting)
pval_score <- pchisq(S, df = 1, lower.tail = FALSE)
## Likelihood ratio test
ll_weib <- function(xdat, scale, shape){
sum(dweibull(x = xdat, scale = scale, shape = shape, log = TRUE))
}
ll1 <- ll_weib(xdat = waiting, scale = mle_weibull[1], shape = mle_weibull[2])
ll0 <- ll_weib(xdat = waiting, scale = mean(waiting), shape = 1)
lrt <- 2*(ll1-ll0)
pval_lrt <- pchisq(lrt, df = 1, lower.tail = FALSE)Both statistics show strong evidence against the null of exponentiality, even if their numerical values are very different: we get \(24.9\) for the score test and \(60.4\) for the likelihood ratio statistic.
Example 3.13 (Profile log likelihood for the Weibull mean) As an alternative, we can use numerical optimization to compute the profile for another function. Suppose we are interested in the expected waiting time, which according to the model is \(\mu = \mathsf{E}(Y) = \lambda\Gamma(1+1/\alpha)\). To this effect, we reparametrize the model in terms of \((\mu, \alpha)\), where \(\lambda=\mu/\Gamma(1+1/\alpha)\). We then make a wrapper function that optimizes the log likelihood for fixed value of \(\mu\), then returns \(\widehat{\alpha}_{\mu}\), \(\mu\) and \(\ell_{\mathrm{p}}(\mu)\).
To get the confidence intervals for a scalar parameter, there is a trick that helps with the derivation. We compute the signed likelihood root \(r(\psi) = \mathrm{sign}(\psi - \widehat{\psi})\{2\ell_{\mathrm{p}}(\widehat{\psi}) -2 \ell_{\mathrm{p}}(\psi)\}^{1/2}\) over a fine grid of \(\psi\), then fit a smoothing spline to the equation flipping the axis (thus, the model has response \(y=\psi\) and \(x=r(\psi)\)). We then predict the curve at the standard normal quantiles \(\mathfrak{z}_{\alpha/2}\) and \(\mathfrak{z}_{1-\alpha/2}\), and return these values as confidence interval. Figure 3.5 shows how these value correspond to the cutoff points on the log likelihood ratio scale, where the vertical line is given by \(-\mathfrak{c}(1-\alpha)\) for \(\mathfrak{c}\) denotes the quantile of a \(\chi^2_1\) random variable, if we consider instead \(R(\psi) = r(\psi)^2\).
Code
# Compute the MLE for the expected value via plug-in
mu_hat <- mle_weibull[1]*gamma(1+1/mle_weibull[2])
# Create a profile function
prof_weibull_mu <- function(mu){
# For given value of mu
alpha_mu <- function(mu){
# Find the profile by optimizing (line search) for fixed mu and the best alpha
opt <- optimize(f = function(alpha, mu){
# minimize the negative log likelihood
nll_weibull(c(mu/gamma(1+1/alpha), alpha), y = waiting)},
mu = mu,
interval = c(0.1,10) #search region
)
# Return the value of the negative log likelihood and alpha_mu
return(c(nll = opt$objective, alpha = opt$minimum))
}
# Create a data frame with mu and the other parameters
data.frame(mu = mu, t(sapply(mu, function(m){alpha_mu(m)})))
}
# Create a data frame with the profile
prof <- prof_weibull_mu(seq(22, 35, length.out = 101L))
# Compute signed likelihood root r
prof$r <- sign(prof$mu - mu_hat)*sqrt(2*(prof$nll - opt_weibull$value))
# Trick: fit a spline to obtain the predictions with mu as a function of r
# Then use this to predict the value at which we intersect the normal quantiles
fit.r <- stats::smooth.spline(x = cbind(prof$r, prof$mu), cv = FALSE)
pr <- predict(fit.r, qnorm(c(0.025, 0.975)))$y
# Plot the signed likelihood root - near linear indicates quadratic
g1 <- ggplot(data = prof,
mapping = aes(x = mu, y = r)) +
geom_abline(intercept = 0, slope = 1) +
geom_line() +
geom_hline(yintercept = qnorm(c(0.025, 0.975)),
linetype = "dashed") +
labs(x = expression(paste("expectation ", mu)),
y = "signed likelihood root")
# Create a plot of the profile
g2 <- ggplot(data = prof,
mapping = aes(x = mu, y = 2*(opt_weibull$value - nll))) +
geom_line() +
geom_hline(yintercept = -qchisq(c(0.95), df = 1),
linetype = "dashed") +
geom_vline(linetype = "dotted",
xintercept = pr) +
labs(x = expression(paste("expectation ", mu)),
y = "negative of likelihood ratio statistic")
g1 + g2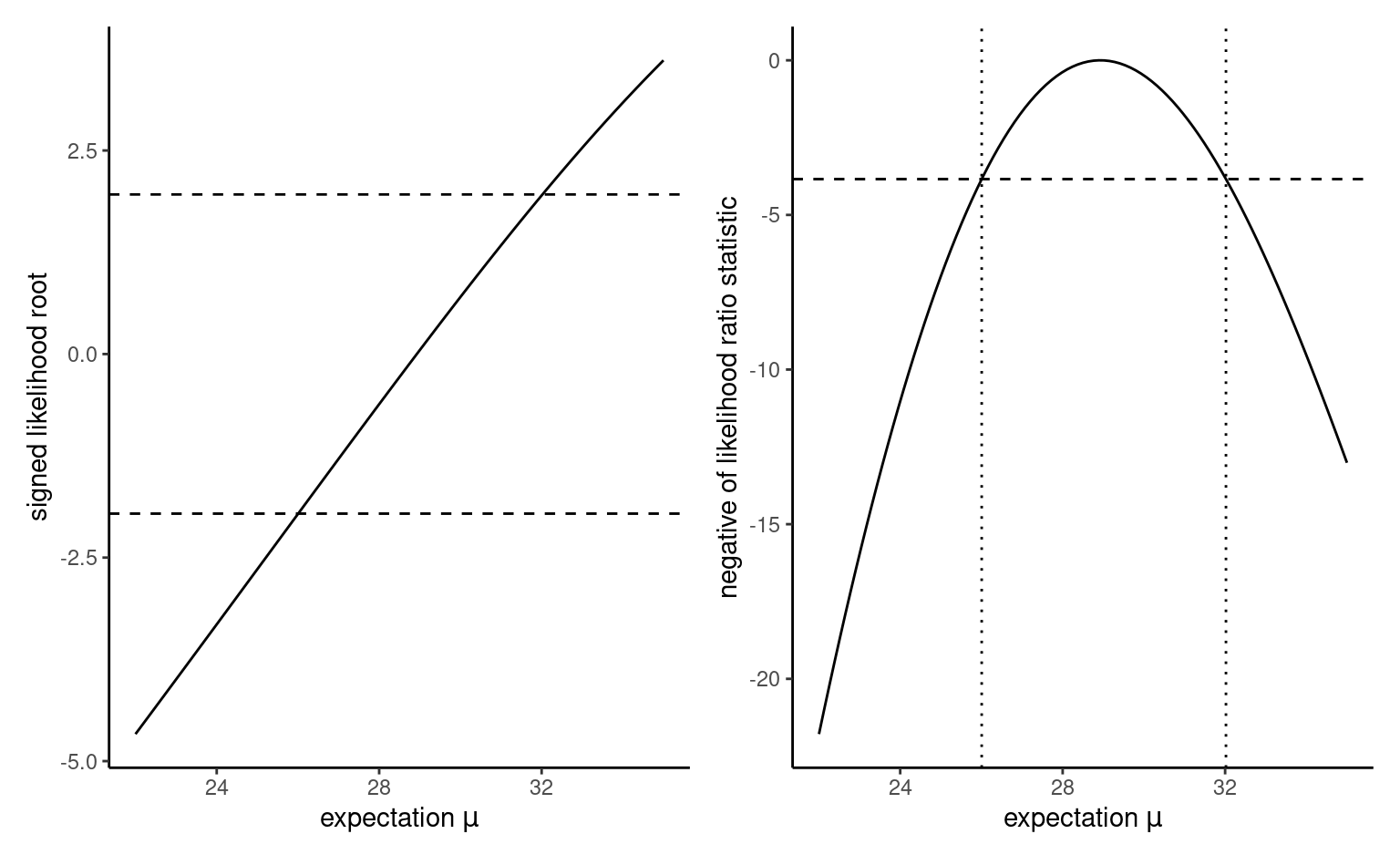
The maximum profile likelihood estimator behaves like a regular likelihood for most quantities of interest and we can derive test statistics and confidence intervals in the usual way. One famous example of profile likelihood is the Cox proportional hazard covered in Chapter 7.
3.5 Information criteria
The likelihood can also serve as building block for model comparison: the larger \(\ell(\boldsymbol{\widehat{\theta}})\), the better the fit. However, the likelihood doesn’t account for model complexity in the sense that more complex models with more parameters lead to higher likelihood. This is not a problem for comparison of nested models using the likelihood ratio test because we look only at relative improvement in fit. There is a danger of overfitting if we only consider the likelihood of a model.
\(\mathsf{AIC}\) and \(\mathsf{BIC}\) are information criteria measuring how well the model fits the data, while penalizing models with more parameters, \[\begin{align*} \mathsf{AIC}&=-2\ell(\widehat{\boldsymbol{\theta}})+2p \\ \mathsf{BIC}&=-2\ell(\widehat{\boldsymbol{\theta}})+p\ln(n), \end{align*}\] where \(p\) is the number of parameters in the model. The smaller the value of \(\mathsf{AIC}\) (or of \(\mathsf{BIC}\)), the better the model fit.
Example 3.14 (Comparing models for waiting time) We have already considered two parametric families, exponential and Weibull, for the metro waiting time. Other candidate models which are not necessarily nested include the lognormal and the gamma distributions.
We can fit these models using fitdistr routine in the MASS package. All but the exponential have two parameters, so the penalty is the same. The Weibull appears best, and while the difference with the gamma distribution isn’t overwhelmingly large, a quantile-quantile plot (not shown) reveals that our Weibull provides a much better fit to the upper tail.
mod0 <- MASS::fitdistr(x = waiting, densfun = "exponential")
mod1 <- MASS::fitdistr(x = waiting, densfun = "gamma")
mod2 <- MASS::fitdistr(x = waiting, densfun = "weibull")
mod3 <- MASS::fitdistr(x = waiting, densfun = "lognormal")
c("exp" = AIC(mod0),
"gamma" = AIC(mod1),
"weibull" = AIC(mod2),
"lognormal" = AIC(mod3))
#> exp gamma weibull lognormal
#> 543 488 485 496Note that information criteria do not constitute formal hypothesis tests on the parameters, but they can be used to compare models that are not nested. Such tools work under regularity conditions, and the estimated information criteria are quite noisy, so comparison for non-nested models are hazardous although popular among practitioners. If we want to compare likelihood from different probability models, we need to make sure they include normalizing constant. The \(\mathsf{BIC}\) is more stringent than \(\mathsf{AIC}\), as its penalty increases with the sample size, so it selects models with fewer parameters. The \(\mathsf{BIC}\) is consistent, meaning that it will pick the true correct model from an ensemble of models with probability one as \(n \to \infty\). In practice, this is of little interest if one assumes that all models are approximation of reality (it is unlikely that the true model is included in the ones we consider). \(\mathsf{AIC}\) often selects overly complicated models in large samples, whereas \(\mathsf{BIC}\) chooses models that are overly simple.
Remark 3.3 (Transformation of variables). While you can compare regression models that are not nested using information criteria, they can only be used when the response variable is the same. To see this, we fit a simple normal distribution to the log of the waiting time, which is equivalent to the lognormal model from mod3 in Example 3.14.
mod4 <- MASS::fitdistr(x = log(waiting), densfun = "normal")
# Due to the transformation, the log likelihood differ
logLik(mod3) - logLik(mod4)
#> 'log Lik.' -202 (df=2)
# The Jacobian is (d/dy log(y) = 1/y)
# hence the log likelihood is -log(y) for each obs.
sum(-log(waiting))
#> [1] -202Thus, you cannot compare a linear regression for \(Y\) to one with response \(\ln(Y)\). Comparisons for log-linear and linear models are valid only if you use the Box–Cox likelihood or include the Jacobian of the transformation.
Software often drops constant terms; this has no impact when you compare models with the same constant factors, but it matters when these differ (e.g., different linear regression models), but it matters more generally when you want to compare a Poisson regression with a linear regression.
Recall that, if \(A\) and \(B\) are independent random variables, the joint probability is the product of the probability of the events, \(\Pr(A \cup B) = \Pr(A)\Pr(B).\) The same holds for density or mass function, since the latter are defined as the derivative of the distribution function.↩︎
Since in most instances we deal with a product of densities, taking the log leads to a sum of log density contributions, which facilitates optimization.↩︎
Using for example a symbolic calculator.↩︎
Most optimization algorithms minimize functions with respect to their arguments, so we minimize the negative log likelihood, which is equivalent to maximizing the log likelihood.↩︎