6.2 Imputation of missing values
If there are missing values in a time series, one ought to handle them with caution. This section adresses this problem, and is there mostly for students whose project dataset features missing values. A simple call to summary will tell you if your object contains NAs.
Suppose we remove some values from sunspots.
sun_miss <- sunspots
# We remove 300 values at random
sun_miss[ints <- sample.int(length(sunspots), 300, replace = FALSE)] <- NA
# The acf function will return an error if we do nothing acf(sun_miss) Ask
# the function to omit those values from the calculations (correct way if we
# keep them)
correlo_pass <- acf(sun_miss, na.action = na.pass)
correlo_excl <- acf(sun_miss, na.action = na.exclude, plot = FALSE) #equivalent acf(na.omit(as.vector(sun_miss)))
# The second is incorrect, because it changes the labels
points(correlo_pass$lag + 0.01, correlo_excl$acf)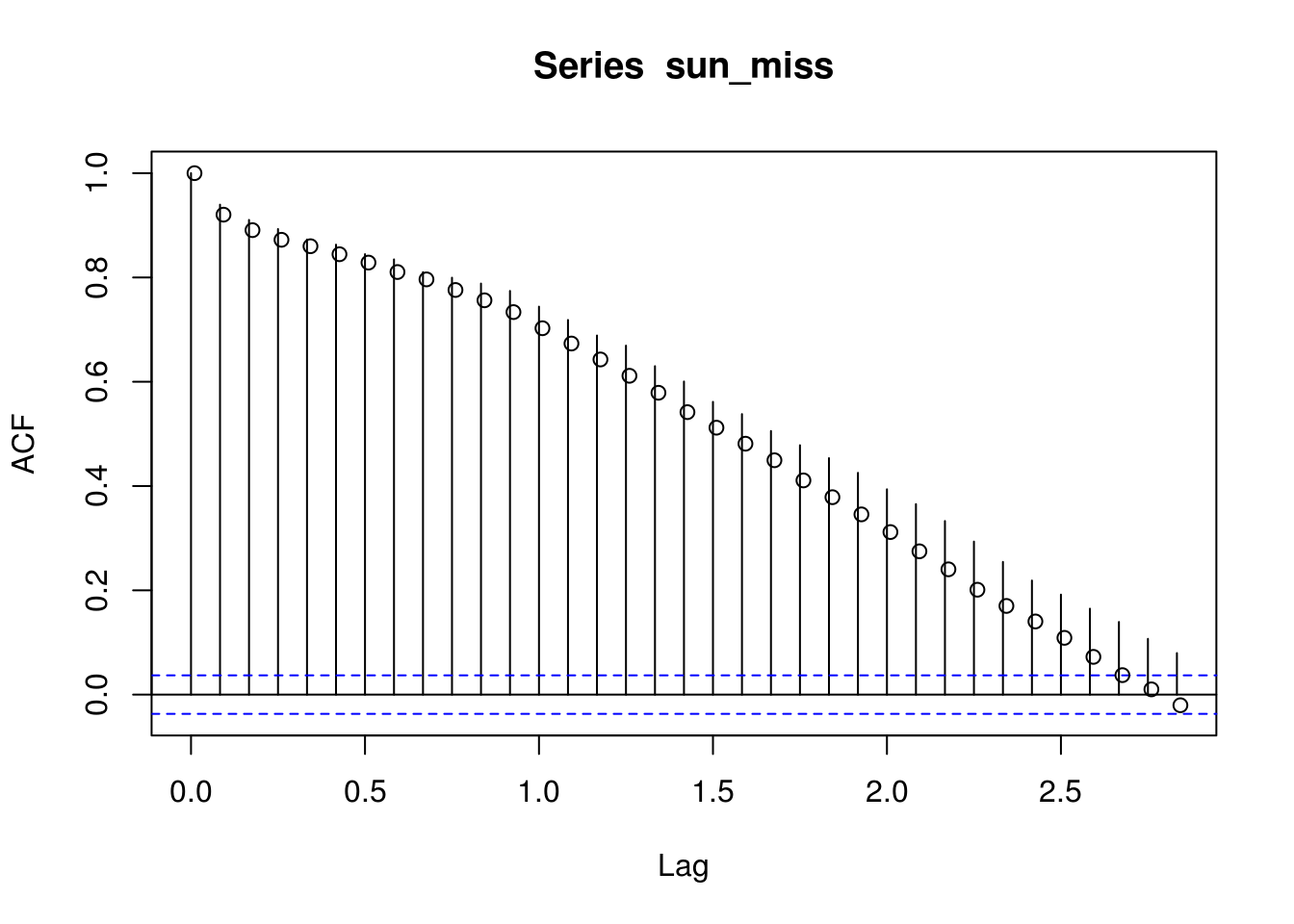
The output is slightly different, but moreover the time stamps are off! This loss of information is even more dramatic if there are multiple consecutive values missing, which may distort the seasonality. Some datasets, for example financial time series, are irregular. This is due to closure of the stock market on holydays and week-ends, so there are apriori no missing values there. Just work with the classes zoo or xts and use na.pass as argument. This way, however, you won’t ever compute lag one correlation between Friday and Monday, but will classify the empirical estimates as three days. You can also remove the weekly seasonality first and later use na.remove (just be careful with your interpretation then).
If your series has values that are missing at random and there is very few of them (1%), you could as a preliminary step impute them. Including new datapoints will bias your standard errors (you are adding information that was not present in the original dataset) unless you adjust for this carefully.