10 Effect sizes and power
In social studies, it is common to write a paper containing multiple studies on a similar topic. These may use different designs, with varying sample size. If the studies uses different questionnaires, or change the Likert scale, the results and the mean difference between groups are not directly comparable between experiments.
We may also wish replicate a study by using the same material and re-run an experiment. For the replication to be somewhat successful (or at least reliable), one needs to determine beforehand how many participants should be recruited in the study.
We could think for an example of comparing statistics or \(p\)-values, which are by construction standardized unit less measures, making them comparable across study. Test statistics show how outlying observed differences between experimental conditions relative to a null hypothesis, typically that of no effect (equal mean in each subgroup). However, statistics are usually a function of both the sample size (the number of observations in each experimental condition) and the effect size (how large the standardized differences between groups are), making them unsuitable for describing differences.
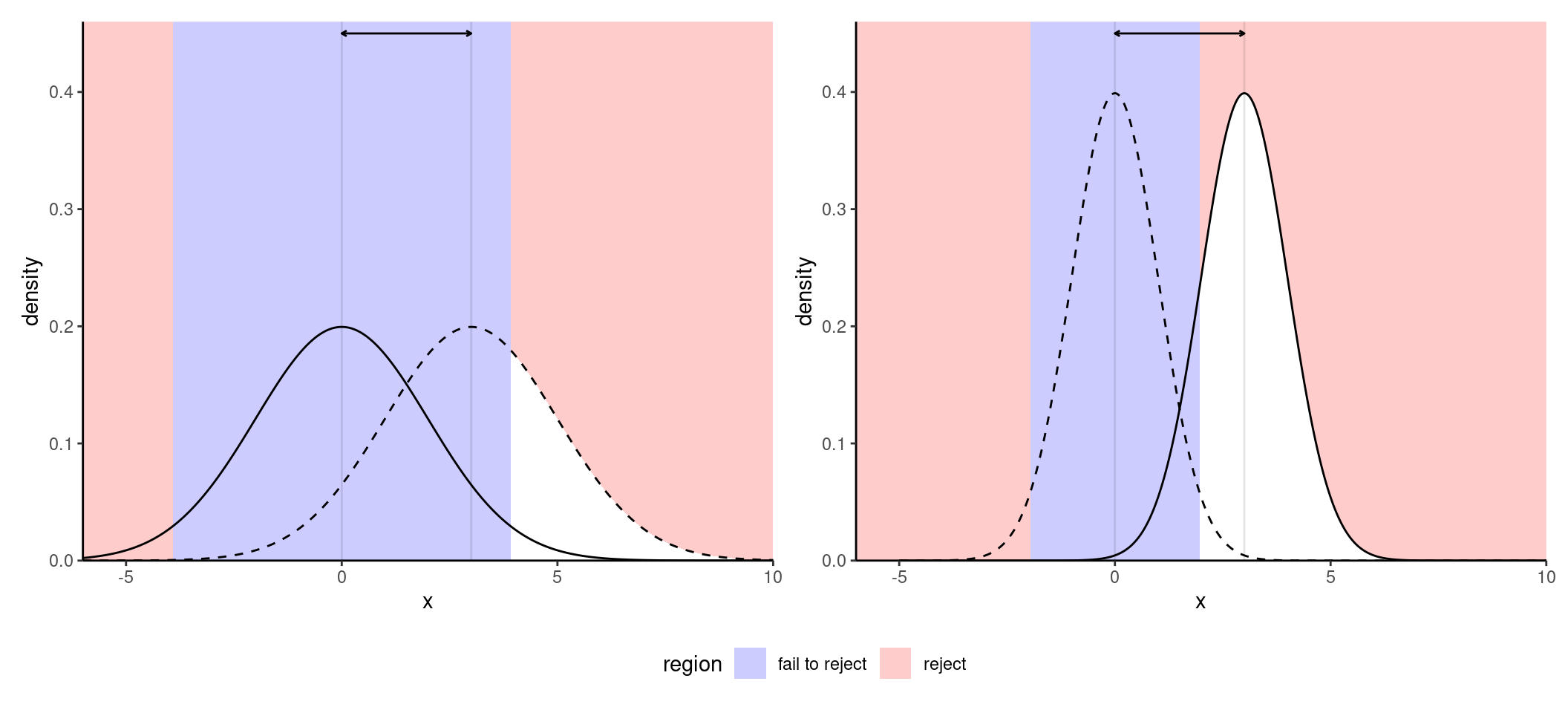
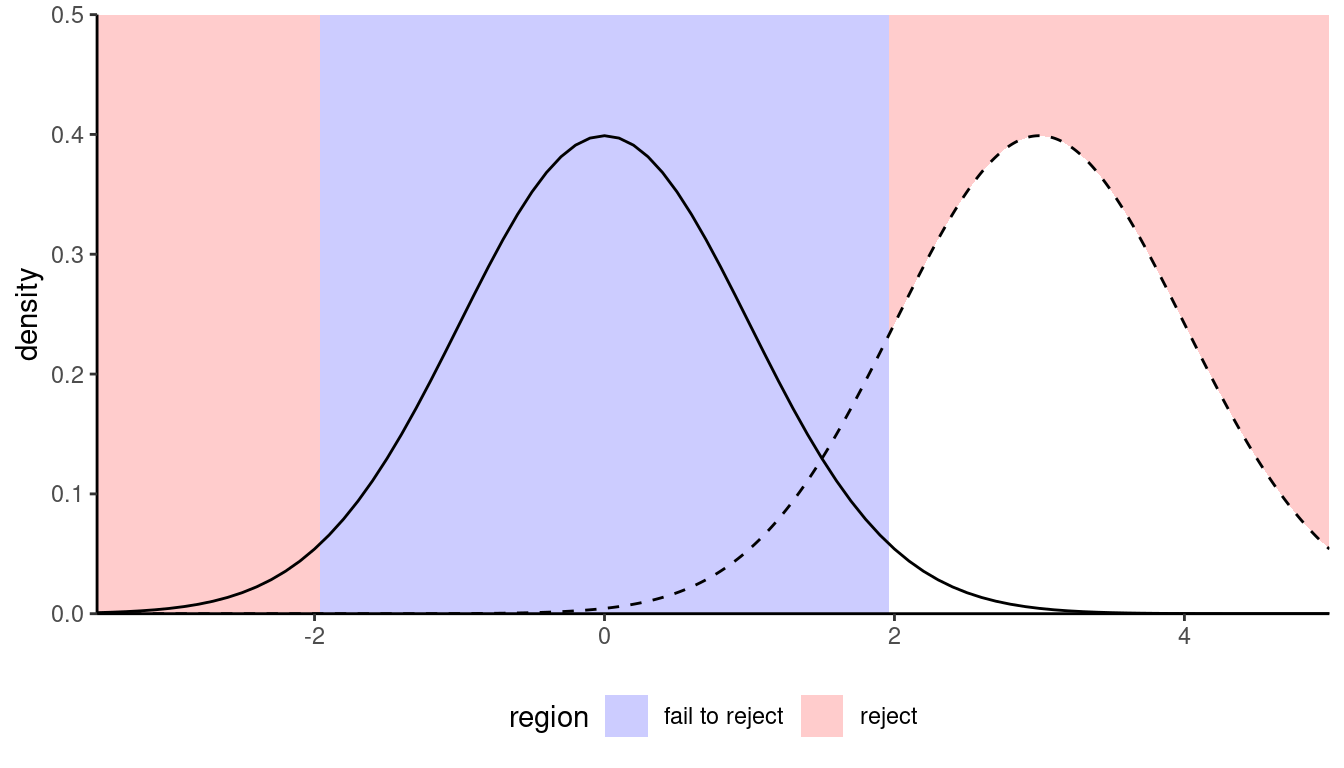
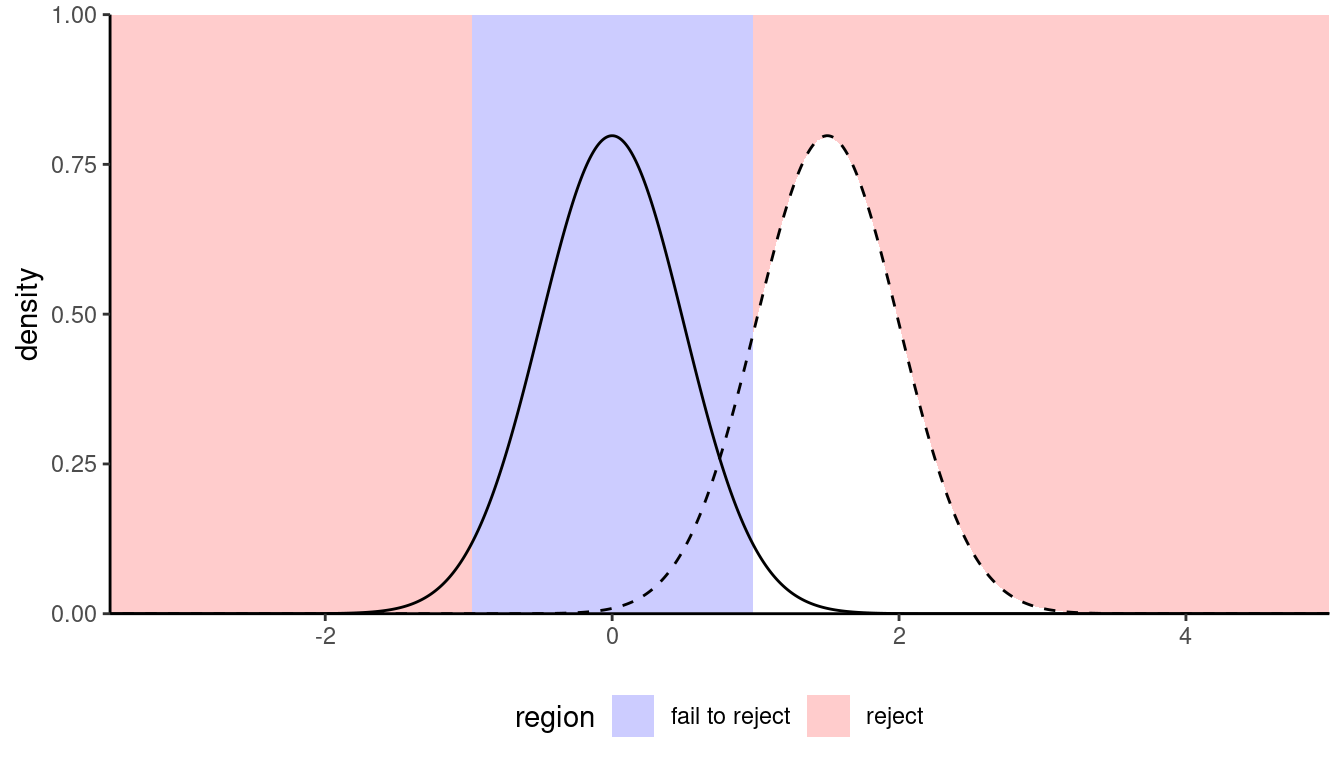
Figure 10.1 shows an example with the sampling distributions of the difference in mean under the null (curve centered at zero) and the true alternative (mean difference of two). The area in white under the curve represents the power, which is larger with larger sample size and coincides with smaller average \(p\)-values for the testing procedure.
One could argue that, on the surface, every null hypothesis is wrong and that, with a sufficiently large number of observation, all observed differences eventually become “statistically significant”. This has to do with the fact that we become more and more certain of the estimated means of each experimental sub-condition. Statistical significance of a testing procedure does not translate into practical relevance, which itself depends on the scientific question at hand. For example, consider the development of a new drug for commercialization by Health Canada: what is the minimum difference between two treatments that would be large enough to justify commercialization of the new drug? If the effect is small but it leads to many lives saved, would it still be relevant? Such decision involve a trade-off between efficacy of new treatment relative to the status quo, the cost of the drug, the magnitude of the improvement, etc.
Effect size are summaries to inform about the standardized magnitude of these differences; they are used to combine results of multiple experiments using meta-analysis, or to calculate sample size requirements to replicate an effect in power studies.
10.1 Effect sizes
There are two main classes of effect size: standardized mean differences and ratio (percentages) of explained variance. The latter are used in analysis of variance when there are multiple groups to compare.
Unfortunately, the literature on effect size is quite large. Researchers often fail to distinguish between estimand (unknown target) and the estimator that is being used, with frequent notational confusion arising due to conflicting standards and definitions. Terms are also overloaded: the same notation may be used to denote an effect size, but it will be calculated differently depending on whether the design is between-subject or within-subject (with repeated correlated measures per participant), or whether there are blocking factors.
10.1.1 Standardized mean differences
To gather intuition, we begin with the task of comparing the means of two groups using a two-sample \(t\)-test, with the null hypothesis of equality in means or \(\mathscr{H}_0: \mu_1 = \mu_2\). The test statistic is \[\begin{align*} T = \frac{\widehat{\mu}_2 - \widehat{\mu}_1}{\widehat{\sigma}} \left(\frac{1}{n_1}+\frac{1}{n_2}\right)^{-1/2} \end{align*}\] where \(\widehat{\sigma}\) is the pooled sample size estimator. The first term, \(\widehat{d}_s = (\widehat{\mu}_2 - \widehat{\mu}_1)/\widehat{\sigma},\) is termed Cohen’s \(d\) (Cohen 1988) and it measures the standardized difference between groups, a form of signal-to-noise ratio. As the sample size gets larger and larger, the sample mean and pooled sample variance become closer and closer to the true population values \(\mu_1\), \(\mu_2\) and \(\sigma;\) at the same time, the statistic \(T\) becomes bigger as \(n\) becomes larger because of the second term.1
The difference \(d=(\mu_1-\mu_2)/\sigma\) has an obvious interpretation: a distance of \(d=a\) indicates that the means of the two groups are \(a\) standard deviation apart. Cohen’s \(d\) is sometimes loosely categorized in terms of weak \((d = 0.2)\), medium \((d=0.5)\) and large \((d=0.8)\) effect size; these, much like arbitrary \(p\)-value cutoffs, are rules of thumbs. Alongside \(d\), there are many commonly reported metrics that are simple transformations of \(d\) describing the observed difference. This interactive applet by Kristoffer Magnusson (Magnusson 2021) shows the visual impact of changing the value of \(d\) along. There are different estimators of \(d\) depending on whether or not the pooled variance estimator is used. Cohen’s \(d,\) is upward biased, meaning it gives values that are on average larger than the truth. Hedge’s \(g\) (Hedges 1981) offers a bias-correction and should always be preferred as an estimator, but the bias is relatively small and vanishes quickly as the sample size increases.
For these different estimators, it is possible to obtain (asymmetric) confidence intervals or tolerance intervals.2
Example 10.1 (Effect sizes for “The Surprise of Reaching Out”) We consider a two-sample \(t\)-test for the study of Liu et al. (2023) discussed in Example 2.5. The difference in average response index is 0.371, indicating that the responder have a higher score. The \(p\)-value is 0.041, showing a small effect.
If we consider the standardized difference \(d\), the group means are \(-0.289\) standard deviations apart based on Hedge’s \(g\), with an associated 95% confidence interval of [\(-0.567, -0.011\)]: thus, the difference found is small (using Cohen (1988)’s convention) and there is a large uncertainty surrounding it.
There is a \(42\)% probability that an observation drawn at random from the responder condition will exceed an observation drawn at random of the initiator group (probability of superiority) and \(38.6\)% of the responder observations will exceed the median of the initiator (Cohen’s \(U_3\)).
data(LRMM23_S1, package = "hecedsm")
ttest <- t.test(
appreciation ~ role,
data = LRMM23_S1,
var.equal = TRUE)
effect <- effectsize::hedges_g(
appreciation ~ role,
data = LRMM23_S1,
pooled_sd = TRUE)10.1.2 Ratio and proportion of variance
Another class of effect sizes are obtained by considering either the ratio of the variance due to an effect (say differences in means relative to the overall mean) relative to the background level of noise as measured by the variance.
One common measure employed in software is Cohen’s f (Cohen 1988), the square of which for a one-way ANOVA with factor \(A\) (equal variance \(\sigma^2\)) with more than two groups, \[ f^2 = \frac{1}{\sigma^2} \sum_{j=1}^k \frac{n_j}{n}(\mu_j - \mu)^2 = \frac{\sigma^2_{A}}{\sigma^2}, \] a weighted sum of squared difference relative to the overall mean \(\mu\). \(\sigma^2_{A}\) is a measure of the variability that is due to the difference in mean, so standardizing it by the measurement variance gives us a ratio of variance with values higher than one indicating that more variability is explainable, leading to higher effect sizes. If the means of every subgroup is the same, then \(f=0\). For \(k=2\) groups, Cohen’s \(f\) and Cohen’s \(d\) are related via \(f=d/2\).
Cohen’s \(f\) can be directly related to the behaviour of the \(F\) statistic under an alternative, as explained in Section 10.2.1. However, since the interpretation isn’t straightforward, we typically consider proportions of variance (rather than ratios of variance).
To build such an effect size, we break down the variability that is explained by our experimental manipulation (\(\sigma^2_A\)), here denoted by effect, from the leftover unexplained part, or residual (\(\sigma^2_\text{resid}\)). In a one-way analysis of variance, \[\sigma^2_{\text{total}} = \sigma^2_{\text{resid}} + \sigma^2_{A}\] and the percentage of variability explained by the factor \(A\) is, so \[\eta^2 = \frac{\text{explained variability}}{\text{total variability}}= \frac{\sigma^2_{A}}{\sigma^2_{\text{resid}} + \sigma^2_{A}} = \frac{\sigma^2_{A}}{\sigma^2_{\text{total}}}.\] Simple arithmetic manipulations reveal that \(f^2 = \eta^2/(1-\eta^2)\), so we can relate any proportion of variance in terms of ratio and vice-versa.
Such an effect size depends on unknown population quantities (the true means of each subgroup, the overall mean and the variance). There are multiple alternative estimators to estimate \(\eta^2\), and researchers are often carefree when reporting as to which is used. To disambiguate, I will put \(\hat{\eta}^2\) to denote an estimator. To make an analogy, there are many different recipes (estimators) that can lead to a particular cake, but some may lead to a mixing that is on average too wet if they are not well calibrated.
The default estimator for \(\eta^2\) is the coefficient of determination of the linear regression, denoted \(\widehat{R}^2\) or \(\widehat{\eta}^2\). The latter can be reconstructed from the analysis of variance table using the formula \[ \widehat{R}{}^2 = \frac{F\nu_1}{F\nu_1 + \nu_2} \] where for the one-way ANOVA \(\nu_1 = K-1\) and \(\nu_2 = n-K\) are the degrees of freedom of a design with \(n\) observations and \(K\) experimental conditions. From this, we can build an estimator of Cohen’s \(f\), where for the omnibus test of the one-way ANOVA, we get \[ \widehat{f} = \sqrt{F\nu_1/\nu_2} \]
Unfortunately, \(\widehat{R}{}^2\) is an upward biased estimator (too large on average), leading to optimistic measures. Another estimator of \(\eta^2\) that is recommended in Keppel and Wickens (2004) for power calculations is \(\widehat{\omega}^2\), which is \[\widehat{\omega}^2 = \frac{\nu_1 (F-1)}{\nu_1(F-1)+n}.\] Since the \(F\) statistic is approximately 1 on average, this measure removes the mode. Both \(\widehat{\omega}^2\) and \(\widehat{\epsilon}^2\) have been reported to be less biased and thus preferable as estimators of the true proportion of variance (Lakens 2013). We can as before get an estimator of Cohen’s \(f\) for the variance ratio as \(\widetilde{f} = \sqrt{\nu_1(F-1)/n}\).
Example 10.2 (Computing effect size for a between-subject one-way ANOVA) Consider the one-way analysis of variance model for the “Degrees of Reading Power” cloze test, from Baumann, Seifert-Kessell, and Jones (1992). The response records the number of correctly answered items, ranging from 0 to 56.
data(BSJ92, package = "hecedsm")
# Fit ANOVA model
mod_post <- lm(posttest3 ~ group, data = BSJ92)
# Extract in data frame format the ANOVA table
anova_table <- broom::tidy(anova(mod_post))
Fstat <- anova_table$statistic[1]
dfs <- anova_table$df
# Output estimated value of eta-squared
(eta_sq <- Fstat * dfs[1] / (Fstat * dfs[1] + dfs[2]))[1] 0.1245399# Compare with coefficient of determination from regression
summary(mod_post)$r.squared[1] 0.1245399# Compare with output from R package 'effectsize'
effectsize::eta_squared(mod_post, partial = FALSE)$Eta2[1] 0.1245399# Compare with omega-squared value - the latter is smaller
(omega_sq <- pmax(0, dfs[1]*(Fstat-1)/ (dfs[1]*(Fstat-1) + nobs(mod_post))))[1] 0.0954215effectsize::omega_squared(mod_post)$Omega2[1] 0.0954215We can also compute effect size for contrasts. Since these take individual the form of \(t\)-tests, we can use emmeans to obtain corresponding effect sizes, which are Cohen’s \(d\).
emmeans::emmeans(mod_post, specs = "group") |>
emmeans::contrast(list(C1 = c(-1, 0.5, 0.5),
C2 = c(0, 1, -1))) |>
# Specify estimated std. deviation of data and degrees of freedom
emmeans::eff_size(sigma = sigma(mod_post), edf = dfs[2]) contrast effect.size SE df lower.CL upper.CL
C1 - C2 0.317 0.4 63 -0.482 1.12
sigma used for effect sizes: 6.314
Confidence level used: 0.95 10.1.3 Partial effects and variance decomposition
In a multiway design with several factors, we may want to estimate the effect of separate factors or interactions. In such cases, we can break down the variability explained by manipulations per effect. The effect size for such models are build by comparing the variance explained by the effect.
For example, say we have a completely randomized balanced design with two factors \(A\), \(B\) and their interaction \(AB\). We can decompose the total variance as \[\sigma^2_{\text{total}} = \sigma^2_A + \sigma^2_B + \sigma^2_{AB} + \sigma^2_{\text{resid}}.\] When the design is balanced, these variance terms can be estimated using the mean squared error from the analysis of variance table output. If the design is unbalanced, the sum of square decomposition is not unique and we will get different estimates when using Type II and Type III sum of squares.
We can get formula similar to the one-sample case with now what are termed partial effect sizes, e.g., \[\widehat{\omega}^2_{\langle \text{effect} \rangle} = \frac{\text{df}_{\text{effect}}(F_{\text{effect}}-1)}{\text{df}_{\text{effect}}(F_{\text{effect}}-1) + n},\] where \(n\) is the overall sample size and \(F_\text{effect}\) and the corresponding degrees of freedom could be the statistic associated to the main effects \(A\) and \(B\), or the interaction term \(AB\). In R, the effectsize package reports these estimates with one-sided confidence intervals derived using the pivot method (Steiger 2004).3
Software will typically return estimates of effect size alongside with the designs, but there are small things to keep in mind. One is that the decomposition of the variance is not unique with unbalanced data. The second is that, when using repeated measures and mixed models, the same notation is used to denote different quantities.
Lastly, it is customary to report effect sizes that include the variability of blocking factors and random effects, leading to so-called generalized effect sizes. Include the variance of all blocking factors and interactions (only with the effect!) in the denominator.4
For example, if \(A\) is the experimental factor whose main effect is of interest, \(B\) is a blocking factor and \(C\) is another experimental factor, use \[\eta_{\langle A \rangle}^2 = \frac{\sigma^2_A}{\sigma^2_A + \sigma^2_B + \sigma^2_{AB} + \sigma^2_{\text{resid}}}.\] as generalized partial effect. The reason for including blocking factors and random effects is that they would not necessarily be available in a replication. The correct effect size measure to calculate and to report depends on the design, and there are numerous estimators that can be utilized. Since they are related to one another, it is oftentimes possible to compute them directly from the output or convert. The formula highlight the importance of reporting (with enough precision) exactly the values of the test statistic.
Example 10.3 In R, the effectsize package functions, which are displayed prominently in this chapter, have a generalized argument to which the vector of names of blocking factor can be passed. We use the one-way analysis of variance from Example 12.1 for illustrating the calculation. Once again, the output matches the output of the package.
mod_block <- lm(apprec ~ role + dyad, data = LRMM23_S3l)
anova_tab <- broom::tidy(anova(mod_block))
# Compute the generalized effect size - variance are estimated
# based on sum of squared termes in the ANOVA table
with(anova_tab, sumsq[1]/sum(sumsq))[1] 0.08802785# We can use the 'effectsize' package, specifying the blocking factor
# through argument 'generalized'
eff <- effectsize::eta_squared(model = mod_block, generalized = "dyad")
# Extract the generalized eta-squared effect size for 'role' for comparison
eff$Eta2_generalized[1][1] 0.08802785
Pitfall
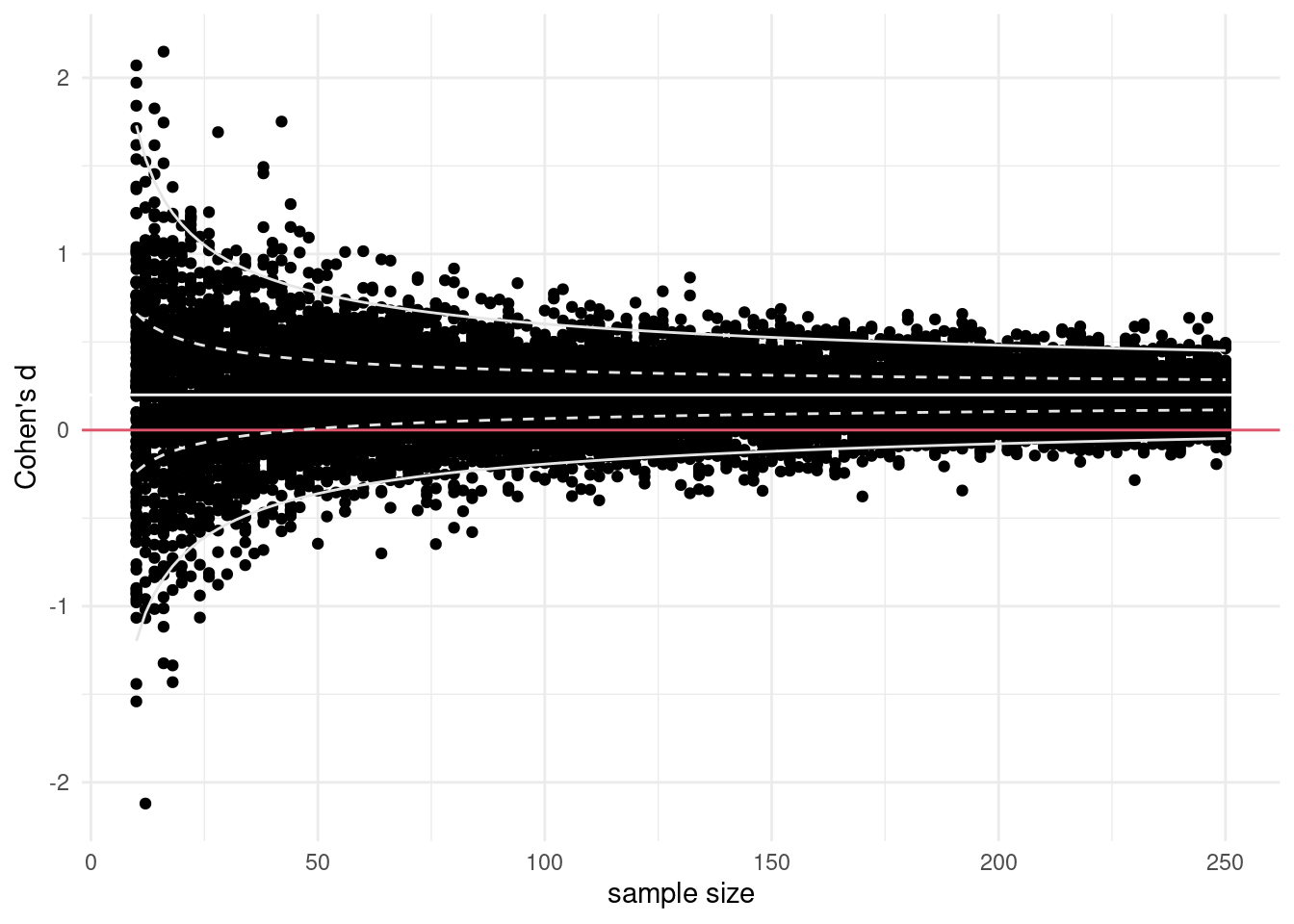
Measures of effect size are estimated based on data, but unlike summary statistics such as the mean and variance, tend to be very noisy in small samples and the uncertainty remains significant for larger samples. To show this, I simulated datasets for a two sample \(t\)-test: there is no effect for the control group, but the true effect for the treatment group is \(d=0.2\). With balanced data (\(n/2\) observations in each group) power is maximised. Figure 10.2 shows the estimated sample size for \(B=100\) replications of the experiment at samples of size \(n=10, 12, \ldots, 250\). The horizontal lines at \(0\) represent no effect: the proportion of values which show effects that are of opposite sign to the truth is still significant at \(n=250\) observations, and the variability seems to decrease very slowly. For smaller samples, the effect sizes are erratic and, although they are centered at the true value, most of them are severely inflated.
10.2 Power
There are typically two uses to hypothesis test: either we want to show it is not unreasonable to assume the null hypothesis (for example, assuming equal variance), or else we want to show beyond reasonable doubt that a difference or effect is significative: for example, one could wish to demonstrate that a new website design (alternative hypothesis) leads to a significant increase in sales relative to the status quo (null hypothesis).
Our ability make discoveries depends on the power of the test: the larger the power, the greater our ability to reject the null hypothesis \(\mathscr{H}_0\) when the latter is false.
The power of a test is the probability of correctly rejecting the null hypothesis \(\mathscr{H}_0\) when \(\mathscr{H}_0\) is false, i.e., \[\begin{align*} \mathsf{Pr}_a(\text{reject} \mathscr{H}_0) \end{align*}\] Whereas the null alternative corresponds to a single value (equality in mean), there are infinitely many alternatives… Depending on the alternative models, it is more or less easy to detect that the null hypothesis is false and reject in favour of an alternative. Power is thus a measure of our ability to detect real effects. Different test statistics can give broadly similar conclusions despite being based on different benchmark. Generally, however, there will be a tradeoff between the number of assumptions we make about our data or model (the fewer, the better) and the ability to draw conclusions when there is truly something going on when the null hypothesis is false.
We want to choose an experimental design and a test statistic that leads to high power, so that this power is as close as possible to one. Under various assumptions about the distribution of the original data, we can derive optimal tests that are most powerful, but some of the power comes from imposing more structure and these assumptions need not be satisfied in practice.
Minimally, the power of the test should be \(\alpha\) because we reject the null hypothesis \(\alpha\) fraction of the time even when \(\mathscr{H}_0\) is true. Power depends on many criteria, notably
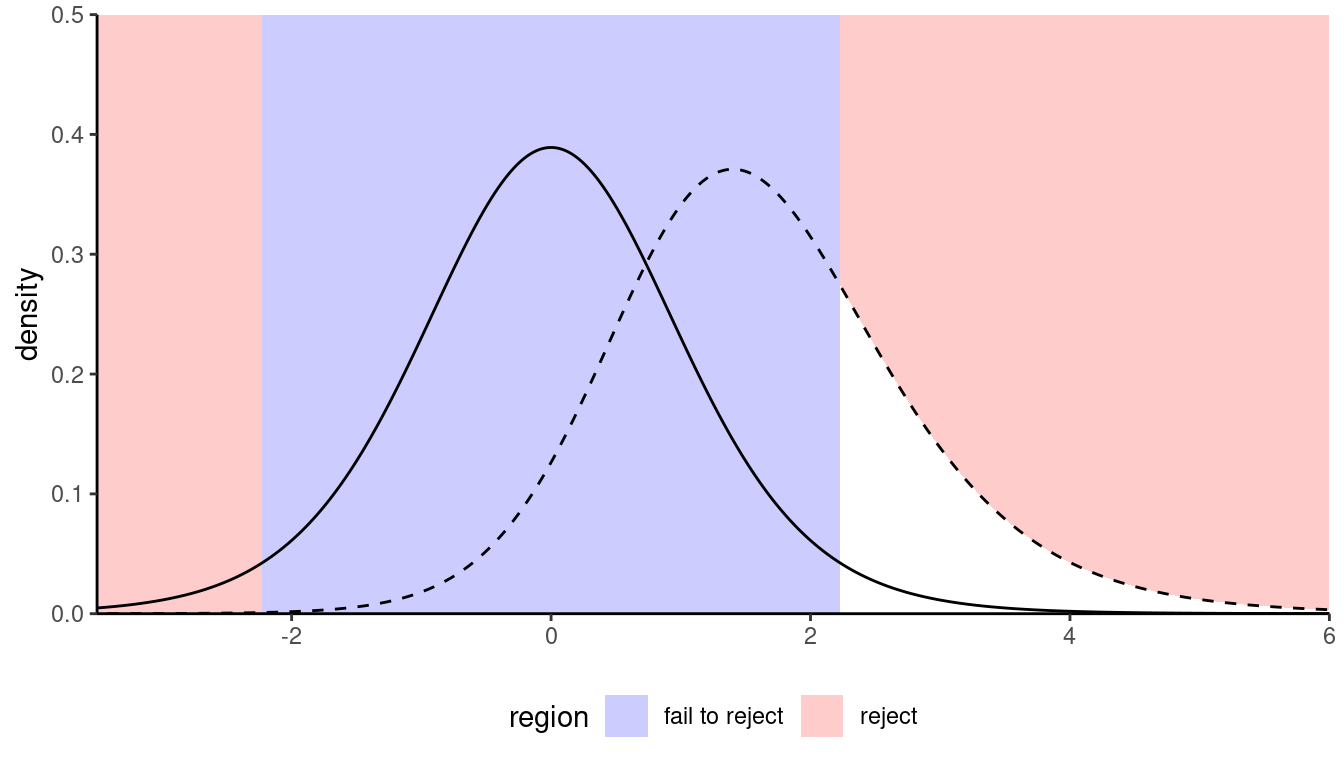
- the effect size: the bigger the difference between the postulated value for \(\theta_0\) under \(\mathscr{H}_0\) and the observed behaviour, the easier it is to detect departures from \(\theta_0\). (Figure 10.5); it’s easier to spot an elephant in a room than a mouse.
- variability: the less noisy your data, the easier it is to assess that the observed differences are genuine, as Figure 10.4 shows;
- the sample size: the more observation, the higher our ability to detect significative differences because the amount of evidence increases as we gather more observations.5 In experimental designs, the power also depends on how many observations are allocated to each group.6
- the choice of test statistic: there is a plethora of possible statistics to choose from as a summary of the evidence against the null hypothesis. Choosing and designing statistics is usually best left out to statisticians, as there may be tradeoffs. For example, rank-based statistics discard information about the observed values of the response, focusing instead on their relative ranking. The resulting tests are typically less powerful, but they are also less sensible to model assumptions, model misspecification and outliers.
Changing the value of \(\alpha\) also has an impact on the power, since larger values of \(\alpha\) move the cutoff towards the bulk of the distribution. However, it entails a higher percentage of rejection also when the alternative is false. Since the value of \(\alpha\) is fixed beforehand to control the type I error (avoid judicial mistakes), it’s not a parameter we consider.
There is an intricate relation between effect size, power and sample size. Journals and grant agencies oftentimes require an estimate of the latter before funding a study, so one needs to ensure that the sample size is large enough to pick-up effects of scientific interest (good signal-to-noise), but also not overly large as to minimize time and money and make an efficient allocation of resources. This is Goldilock’s principle, but having more never hurts.
If we run a pilot study to estimate the background level of noise and the estimated effect, or if we wish to perform a replication study, we will come up with a similar question in both cases: how many participants are needed to reliably detect such a difference? Setting a minimum value for the power (at least 80%, but typically 90% or 95% when feasible) ensures that the study is more reliable and ensures a high chance of success of finding an effect of at least the size specified. A power of 80% ensures that, on average, 4 in 5 experiments in which we study a phenomenon with the specified non-null effect size should lead to rejecting the null hypothesis.
In order to better understand the interplay between power, effect size and sample size, we consider a theoretical example. The purpose of displaying the formula is to (hopefully) more transparently confirm some of our intuitions about what leads to higher power. There are many things that can influence the power:
- the experimental design: a blocking design or repeated measures tend to filter out some of the unwanted variability in the population, thus increasing power relative to a completely randomized design
- the background variability \(\sigma\): the noise level is oftentimes intrinsic to the measurement. It depends on the phenomenon under study, but instrumentation and the choice of scale, etc. can have an impact. Running experiments in a controlled environment helps reduce this, but researchers typically have limited control on the variability inherent to each observation.
- the sample size: as more data are gathered, information accumulates. The precision of measurements (e.g., differences in mean) is normally determined by the group with the smallest sample size, so (approximate) balancing increases power if the variance in each group is the same.
- the size of the effect: the bigger the effect, the easier it is to accurately detect (it’s easier to spot an elephant than a mouse hiding in a classroom).
- the level of the test, \(\alpha\): if we increase the rejection region, we technically increase power when we run an experiment under an alternative regime. However, the level is oftentimes prespecified to avoid type I errors. We may consider multiplicity correction within the power function, such as Bonferonni’s method, which is equivalent to reducing \(\alpha\).
10.2.1 Power for one-way ANOVA
To fix ideas, we consider the one-way analysis of variance model. In the usual setup, we consider \(K\) experimental conditions with \(n_k\) observations in group \(k\), whose population average we denote by \(\mu_k\). We can parametrize the model in terms of the overall sample average, \[\begin{align*} \mu = \frac{1}{n}\sum_{j=1}^K\sum_{i=1}^{n_j} \mu_j = \frac{1}{n}\sum_{j=1}^K n_j \mu_j, \end{align*}\] where \(n=n_1 + \cdots +n_K\) is the total sample size. The \(F\)-statistic of the one-way ANOVA is \[\begin{align*} F = \frac{\text{between sum of squares}/(K-1)}{\text{within sum of squares}/(n-K)} \end{align*}\] The null distribution is \(F(K-1, n-K)\). Our interest is in understanding how the F-statistic behaves under an alternative.
During the construction, we stressed out that the denominator is an estimator of \(\sigma^2\) under both the null and alternative. What happens to the numerator? We can write the population average for the between sum of square as \[ \mathsf{E}(\text{between sum of squares}) = \sigma^2\{(K-1) + \Delta\}. \] where \[ \Delta = \dfrac{\sum_{j=1}^K n_j(\mu_j - \mu)^2}{\sigma^2} = nf^2. \] and where \(f^2\) is the square of Cohen’s \(f\). Under the null hypothesis, all group means are equal and \(\mu_j=\mu\) for \(j=1, \ldots, K\) and \(\Delta=0\), but if some groups have different average the displacement will be non-zero. The greater \(\Delta\), the further the mode (peak of the distribution) is from unity and the greater the power.
Closer examination reveals that \(\Delta\) increases with \(n_j\) (sample size) and with the true squared mean difference \((\mu_j-\mu)^2\) increases effect size represented by the difference in mean, but decreases as the observation variance increases.
Under the alternative, the distribution of the \(F\) statistic is a noncentral Fisher distribution, denoted \(\mathsf{F}(\nu_1, \nu_2, \Delta)\) with degrees of freedom \(\nu_1\) and \(\nu_2\) and noncentrality parameter \(\Delta\).7 To calculate the power of a test, we need to single out a specific alternative hypothesis.
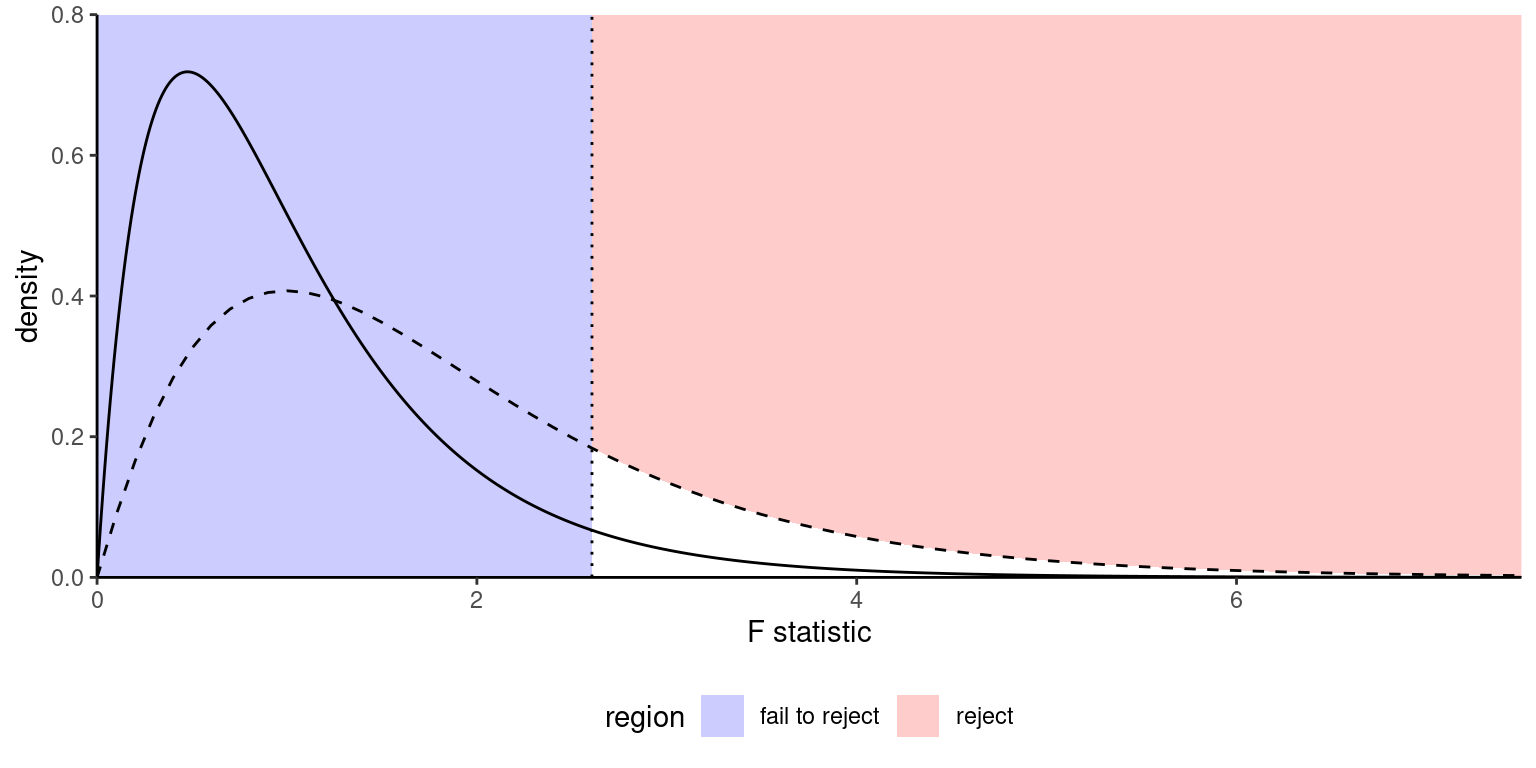
The plot in Figure 10.6 shows the null (full line) distribution and the true distribution (dashed line) for a particular alternative. The noncentral \(\mathsf{F}\) is shifted to the right and right skewed, so the mode (peak) is further away from 1.
Given a value of \(\Delta=nf^2\) and information about the effect of interest (degrees of freedom of the effect and the residuals), we can compute the tail probability as follows
- Compute the cutoff point: the value under \(\mathscr{H}_0\) that leads to rejection at level \(\alpha\)
- Compute probability below the alternative curve, from the cutoff onwards.
cutoff <- qf(p = 1-alpha, df1 = df1, df2 = df2)
pf(q = cutoff, df1 = df1, df2 = df2,
ncp = Delta, lower.tail = FALSE)10.2.2 Power calculations
In practice, a software will return these quantities and inform us about the power. Note that these results are trustworthy provided the model assumptions are met, otherwise they may be misleading.
The most difficult question when trying to estimate sample size for a study is determining which value to use for the effect size. One could opt for a value reported elsewhere for a similar scale to estimate the variability and provide educated guesses for the mean differences. Another option is to run a pilot study and use the resulting estimates to inform about sensible values, perhaps using confidence intervals to see the range of plausible effect sizes. Keep in mind the findings from Figure 10.2.
Reliance on estimated effect sizes reported in the literature is debatable: many such effects are inflated as a result of the file-drawer problem and, as such, can lead to unreasonably high expectations about power.
The WebPower package in R offers a comprehensive solution for conducting power studies, as does the free software G*Power. We present a range of examples from a replication study: the following quotes are taken from the Reproducibility Project: Psychology.
Example 10.4 (Power calculation for between subject ANOVA) The following extract of Jesse Chandler’s replication concerns Study 4b by Janiszewski and Uy (2008), which considers a \(2 \times 2\) between-subject ANOVA.
In Study 4a there are two effects of theoretical interest, a substantial main effect of anchor precision that replicates the first three studies and a small interaction (between precision and motivation within which people can adjust) that is not central to the paper. The main effect of anchor precision (effect size \(\eta^2_p=0.55\)) would require a sample size of \(10\) for \(80\)% power, \(12\) for \(90\)% power, and \(14\) for \(95\)% power. The interaction (effect size \(\eta^2_p=0.11\)) would require a sample size of \(65\) for \(80\)% power, \(87\) for \(90\)% power, and \(107\) for \(95\)% power. There was also a theoretically uninteresting main effect of motivation (people adjust more when told to adjust more).
In order to replicate, we must first convert estimates of \(\eta^2_p\) to Cohen’s \(f\), which is the input accepted by both WebPower and G*Power. We compute the sample size for power 95% for both the main effect and the interaction: in practice, we would pick the smaller of the two (or equivalently the larger resulting sample size estimate) should we wish to replicate both findings.
f <- effectsize::eta2_to_f(0.55) # convert eta-squared to Cohen's f
ng <- 4 # number of groups for the ANOVA
ceiling(WebPower::wp.kanova(ndf = 1, ng = ng, f = f, power = 0.95)$n)[1] 14f <- effectsize::eta2_to_f(0.11)
ceiling(WebPower::wp.kanova(ndf = 1, ng = ng, f = f, power = 0.95)$n)[1] 108We can see that the numbers match the calculations from the replication (up to rounding).
Example 10.5 (Power calculation for mixed design) Repeated measures ANOVA have different characteristics from between-subject design in that measurements are correlated, and we can also provide correction for sphericity. These additional parameters need to specified by users. In WebPower, the wp.rmanova function. We need to specify the number of measurements per person, the number of groups, the value \(\epsilon\) for the sphericity correction, e.g., the output of Greenhouse–Geisser or Huynh–Feldt and the type of effect for between-subject factor, within-subject factor or an interaction between the two.
The result that is object of this replication is the interaction between item strength (massed vs. spaced presentation) and condition (directed forgetting vs. control). The dependent variable is the proportion of correctly remembered items from the stimulus set (List 1). “(..) The interaction was significant, \(F(1,94)=4.97\), \(p <.05\), \(\mathrm{MSE} =0.029\), \(\eta^2=0.05\), (…)”. (p. 412). Power analysis (G*Power (Version 3.1): ANOVA: Repeated measures, within-between interaction with a zero correlation between the repeated measures) indicated that sample sizes for \(80\)%, \(90\)% and \(95\)% power were respectively \(78\), \(102\) and \(126\).
We are thus considering a \(2 \times 2\) within-between design. The estimated effect size is \(\widehat{\eta}^2_p=0.05\), with Cohen’s \(f\), where the value is multiplied by a constant \(C\); see the WebPower page which depends on the number of groups, the number of repeated measurements \(K\) and their correlation \(\rho\). For the interaction, the correction factor is \(C = \sqrt{K/(1-\rho)}\): taking \(K=2\) and \(\rho=0\), we get a Cohen’s \(f\) of 0.23. We calculate the sample size for a power of 90% changing \(\rho\): if we change the correlation in the calculation from zero to \(0.5\), we can see that there is a significant decrease in the sample size.
f <- effectsize::eta2_to_f(0.05) # convert eta-squared to Cohen's f
rho <- 0 # correlation between measurements
K <- 2L # number of repeated measurements
round(WebPower::wp.rmanova(type = 2, # interaction
nm = K, # number of measurement per subject
ng = 2, # number of groups for between,
f = f*sqrt(K/(1-rho)), # scaled effect size
power = 0.9)$n) # requested power[1] 102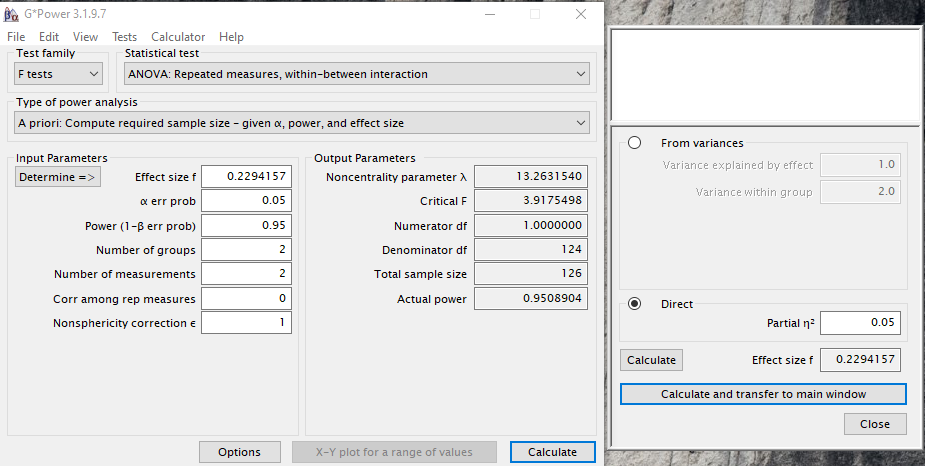
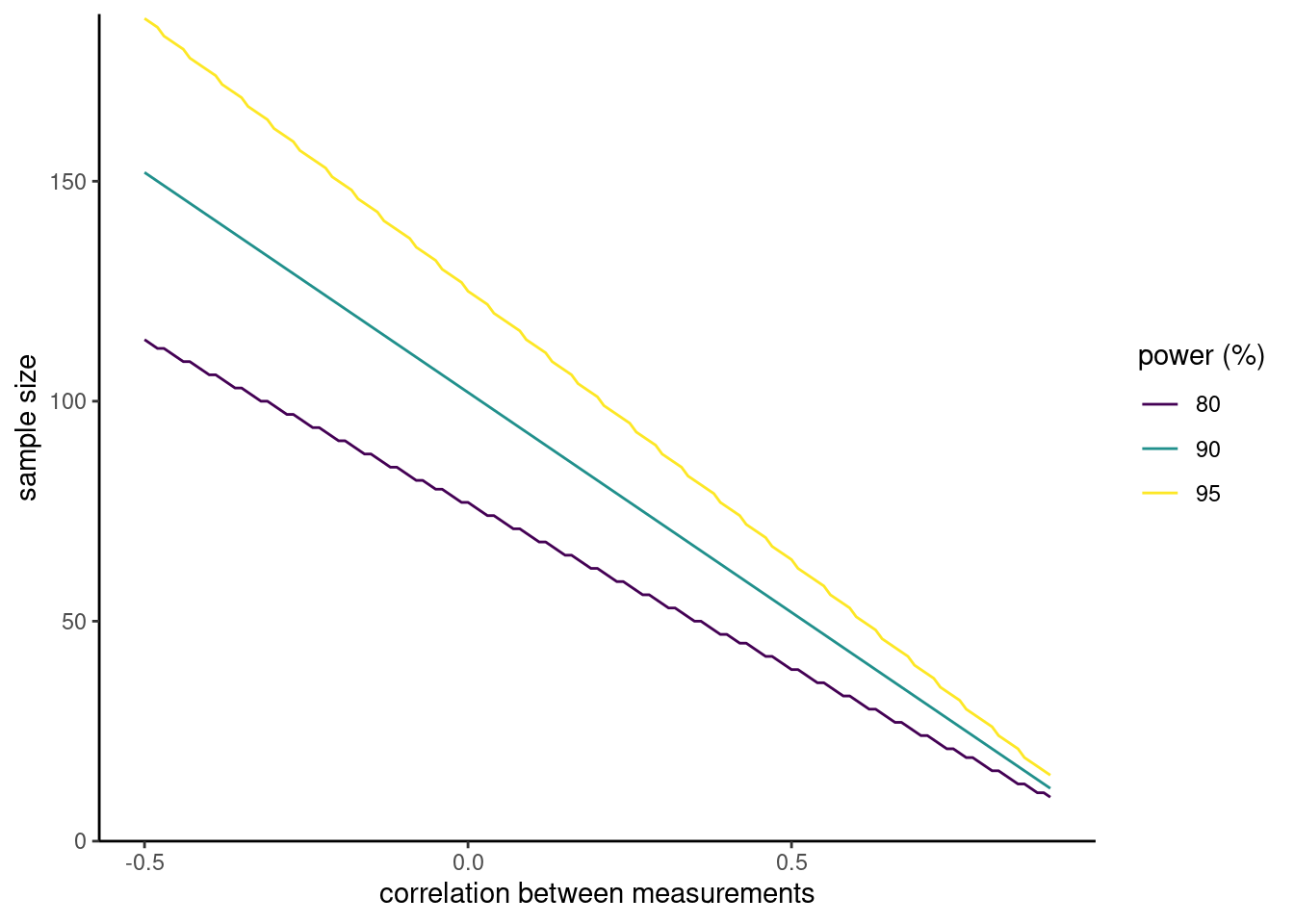
We can see that the more correlated the response, the smaller sample size requirement according to Figure 10.8. Higher power requirement leads to larger data collection efforts.
Example 10.6 (Power calculation for a two sample \(t\)-test) We consider a two-sample comparison, as these arise frequently from contrasts. The replication wishes to replicate a study whose estimated effect size was a Cohen’s \(d\) of \(\widehat{d} = 0.451\). Using a two-tailed test with a balanced sample and \(\alpha = 0.05\) type I error rate, we obtain \(258\) participants. Note that some software, as below, report the sample size by group so the total sample size is twice the number reported.
2*ceiling(WebPower::wp.t(
type = "two.sample",
alternative = "two.sided",
d = 0.451, # Cohen's f
power = 0.95)$n) # power requirement[1] 258The function also allows us to figure out the effect size one could obtain for given power and fixed sample size, by replacing d with the latter via arguments n1 and n2.
10.2.3 Power in complex designs
In cases where an analytic derivations isn’t possible, we can resort to simulations to approximate the power. For a given alternative, we
- simulate repeatedly samples from the model from the hypothetical alternative world
- we compute the test statistic for each of these new samples
- we transform these to the associated p-values based on the postulated null hypothesis.
At the end, we calculate the proportion of tests that lead to a rejection of the null hypothesis at level \(\alpha\), namely the percentage of p-values smaller than \(\alpha\). We can vary the sample size and see how many observations we need per group to achieve the desired level of power.
10.3 Additional R examples
Effect size typically serve three purpose:
- inform readers of the magnitude of the effect,
- provide a standardized quantity that can be combined with others in a meta-analysis, or
- serve as proxy in a power study to estimate the minimum number of observations needed.
If you report the exact value of the test statistic, the null distribution and (in short) all elements of an analysis of variance table in a complex design, it is possible by using suitable formulae to recover effect sizes, as they are functions of the test statistic summaries, degrees of freedom and correlation between observations (in the case of repeated measures).
The effectsize package includes a variety of estimators for standardized difference or ratio of variance. For example, for the latter, we can retrieve Cohen’s \(f\) via cohens_f, \(\widehat{\epsilon}^2\) via epsilon_squared or \(\widehat{\omega}^2\) via omega_squared. By default, in a design with more than one factor, the partial effects are returned (argument partial = TRUE) — if there is a single factor, these coincide with the total effects and the distinction is immaterial.
The effectsize package reports confidence intervals8 calculated using the pivot method described in Steiger (2004). Check the documentation at ?effectsize::effectsize_CIs for more technical details.9
In general, confidence intervals for effect sizes are very wide, including a large range of potential values and sometimes zero. This reflects the large uncertainty surrounding their estimation and should not be taken to mean that the estimated effect is null.
Example 10.7 (Effect size and power for a one-way ANOVA) We begin with the result of another one-way ANOVA using data from Baumann, Seifert-Kessell, and Jones (1992). If we consider the global \(F\)-test of equality in means, we can report as corresponding effect size the percentage of variance that is explained by the experimental condition, group.
library(effectsize)
data(BSJ92, package = "hecedsm")
mod <- aov(posttest2 - pretest2 ~ group,
data = BSJ92)
print_md(omega_squared(anova(mod), partial = FALSE))| Parameter | Omega2 | 95% CI |
|---|---|---|
| group | 0.16 | [0.03, 1.00] |
One-sided CIs: upper bound fixed at [1.00].
The estimator employed is \(\widehat{\omega}^2\) and could be obtained directly using the formula provided in the slides. For a proportion of variance, the number is medium according to Cohen (1988) definition. Using \(\widehat{R}^2 \equiv \widehat{\eta}^2\) as estimator instead would give an estimated proportion of variance of 0.188, a slightly higher number.
Having found a significant difference in mean between groups, one could be interested in computing estimated marginal means and contrasts based on the latter. The emmeans function has a method for computing effect size (Cohen’s \(d\)) for pairwise differences if provided with the denominator standard deviation \(\sigma\) and the degrees of freedom associated with the latter (i.e., how many observations were left from the total sample size after subtracting the number of subgroup means).
The confidence intervals reported by emmeans for \(t\)-tests are symmetric and different in nature from the one obtained previously.
Technical aside: while it is possible to create a \(t\)-statistic for a constrast by dividing the contrast estimator by it’s standard error, the construction of Cohen’s \(d\) here for the contrast consisting of, e.g., the pairwise difference between DRTA and TA would take the form \[
d_{\text{DRTA}- \text{TA}} = \frac{\mu_{\text{DRTA}}- \mu_{\text{TA}}}{\sigma},
\] where the denominator stands for the standard deviation of the observations.10
Example 10.8 (Sample size for replication studies) Armed with effect sizes and a desired level of power, it is possible to determine the minimum number of observations that would yield such effect. Johnson, Cheung, and Donnellan (2014) performs a replication study of Schnall, Benton, and Harvey (2008) who conjectured that physical cleanliness reduces the severity of moral judgments. The following excerpt from the paper explain how sample size for the replication were calculated.
In Experiment 2, the critical test of the cleanliness manipulation on ratings of morality was significant, \(F(1, 41) = 7.81\), \(p=0.01\), \(d=0.87\), \(N=44\). Assuming \(\alpha=0.05\), the achieved power in this experiment was \(0.80\). Our proposed research will attempt to replicate this experiment with a level of power = \(0.99\). This will require a minimum of 100 participants (assuming equal sized groups with \(d=0.87\)) so we will collect data from 115 participants to ensure a properly powered sample in case of errors.
The first step is to try and compute the effect size, here Cohen’s \(d\), from the reported \(F\) statistic to make sure it matches the quoted value.
This indeed coincides with the value reported for Cohen’s \(d\) estimator. We can then plug-in this value in the power function with the desired power level \(0.99\) to find out a minimal number of 50 participants in each group, for a total of 100 if we do a pairwise comparison using a two-sample \(t\)-test.
Two-sample t-test
n d alpha power
49.53039 0.87 0.05 0.99
NOTE: n is number in *each* group
URL: http://psychstat.org/ttestThe effectsize package includes many functions to convert \(F\) and \(t\) statistics to effect sizes.11
Example 10.9 (Power calculation for a two-way ANOVA with unbalanced data) While software can easily compute effect sizes, the user should not blindly rely on the output, but rather think about various elements using the following guiding principles:
- we are interested in partial effects when there are multiple factors
- the denominator should consist of the variance of the effect of interest (say factor \(A\)), the variance of blocking factors and random effects and that of all interactions associated with them.
Consider next the unbalanced two-way ANOVA example in Study 1 of Maglio and Polman (2014). We pass here directly the output of the model. We use the lm function with the mean-to-zero parametrization, since we have unbalanced data.
By default, the variance terms for each factor and interaction are estimated using the anova call. When the data aren’t balanced and you have multiple factors in the mean equation, these are the sequential sum of square estimates (type I). This means that the resulting effect size would depend on the order in which you specify the terms, an unappealing feature. The model can alternatively take as argument the analysis of variance table produced by the Anova function in package car, e.g., car::Anova(..., type = 3). Note that it is of paramount importance to pass the correct arguments and to use the mean-to-zero parametrization in order to get sensible results. The package warns users about this.
Type 3 ANOVAs only give sensible and informative results when covariates
are mean-centered and factors are coded with orthogonal contrasts (such
as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
*not* by the default `contr.treatment`).The estimated effect size for the main effect of direction is negative with \(\widehat{\omega}^2_{\langle \text{direction}\rangle}\): either reporting a negative value or zero. This reflects that the estimated effect is very insignificant.
Equipped with the estimated effect size, we can now transform our partial \(\widehat{\omega}^2_{\langle\text{AB}\rangle}\) measure into an estimated Cohen’s \(f\) via \[\widetilde{f} = \left( \frac{\widehat{\omega}^2}{1-\widehat{\omega}^2}\right)^{1/2},\] which is then fed into WebPower package functionality to compute the post-hoc power. Since we are dealing with a two-way ANOVA with 8 subgroups, we set ng=8 and then ndf corresponding to the degrees of freedom of the estimated interaction (here \((n_a-1)\times (n_b-1)=3\), the number of coefficients needed to capture the interaction).
Given all but one of the following collection
- the power,
- the number of groups and degrees of freedom from the design,
- the effect size and
- the sample size,
it is possible to deduce the last one assuming a balanced sample. Below, we use the information to compute the so-called post-hoc power. Such terminology is misleading because there is no guarantee that we are under the alternative, and effect sizes are really noisy proxy so the range of potential values for the missing ingredient is oftentimes quite large. Because studies in the literature have inflated effect size, the power measures are more often than not misleading.
Multiple way ANOVA analysis
n ndf ddf f ng alpha power
202 3 194 0.4764222 8 0.05 0.9999821
NOTE: Sample size is the total sample size
URL: http://psychstat.org/kanovaHere, the interaction is unusually strong (a fifth of the variance is explained by it!) and we have an extremely large post-hoc power estimate. This is rather unsurprising given the way the experiment was set up.
We can use the same function to determine how many observations the study would need to minimally achieve a certain power, below of 99% — the number reported must be rounded up to the nearest integer. Depending on the design or function, this number may be the overall sample size or the sample size per group.
Type 3 ANOVAs only give sensible and informative results when covariates
are mean-centered and factors are coded with orthogonal contrasts (such
as those produced by `contr.sum`, `contr.poly`, or `contr.helmert`, but
*not* by the default `contr.treatment`).Multiple way ANOVA analysis
n ndf ddf f ng alpha power
107.8 3 99.80004 0.4764222 8 0.05 0.99
NOTE: Sample size is the total sample size
URL: http://psychstat.org/kanovaMultiple way ANOVA analysis
n ndf ddf f ng alpha power
97.61394 3 89.61394 0.5017988 8 0.05 0.99
NOTE: Sample size is the total sample size
URL: http://psychstat.org/kanovaThe total sample size using \(\widehat{\omega}^2\) is 108, whereas using the biased estimator \(\widehat{f}\) directly (itself obtained from \(\widehat{\eta}^2\)) gives 98: this difference of 10 individuals can have practical implications.
Example 10.10 (Sample size calculation for a replication with a mixed design) You can download G*Power to perform these calculations. The following quote is taken from the Reproducibility Project: Psychology
The result that is object of this replication is the interaction between item strength (massed vs. spaced presentation) and condition (directed forgetting vs. control). The dependent variable is the proportion of correctly remembered items from the stimulus set (List 1). “(..) The interaction was significant, \(F(1,94)=4.97\), \(p <.05\), \(\mathrm{MSE} =0.029\), \(\eta^2=0.05\), (…)”. (p. 412). Power analysis (G*Power (Version 3.1): ANOVA: Repeated measures, within-between interaction with a zero correlation between the repeated measures) indicated that sample sizes for \(80\)%, \(90\)% and \(95\)% power were respectively \(78\), \(102\) and \(126\).
Not all software accept the same input, so we need to tweak the effect size to get the same answers. The user must specify whether we are looking at a within-subjet, between-subject contrast, or an interaction between the two, as is the case here. The latter in WebPower (for an interaction effect) should be \(\sigma_{\text{effect}}/\sigma_{\text{resid}} \times C\), where \(C = \sqrt{K/(1-\rho)}\), and where \(K\) is the number of groups and \(\rho\) the correlation of within-subject measurements. We use the wp.rmanova function, specify the type (2 for interaction), the number of groups \(K=2\), the number of repeated measurements \(2\). The description uses a correlation \(\rho=0\), which is a worst-case scenario: in practice, more correlation leads to reduced sample size requirements.
Repeated-measures ANOVA analysis
n f ng nm nscor alpha power
76.53314 0.3244428 2 2 1 0.05 0.8
NOTE: Power analysis for interaction-effect test
URL: http://psychstat.org/rmanovaRepeated-measures ANOVA analysis
n f ng nm nscor alpha power
101.7801 0.3244428 2 2 1 0.05 0.9
NOTE: Power analysis for interaction-effect test
URL: http://psychstat.org/rmanovaRepeated-measures ANOVA analysis
n f ng nm nscor alpha power
125.4038 0.3244428 2 2 1 0.05 0.95
NOTE: Power analysis for interaction-effect test
URL: http://psychstat.org/rmanovaConsider next a similar calculation for a repeated measure design:
We aim at testing the two main effects of prediction 1 and prediction 3. Given the \(2 \times 3\) within factors design for both main effects, we calculated \(\eta^2_p\) based on \(F\)-Values and degrees of freedom. This procedure resulted in \(\eta^2_p=0.427\) and \(\eta^2_p=0.389\) for the effect of prediction 1 (\(F(1, 36)=22.88\)) and prediction 3 (\(F(1, 36)=26.88\)), respectively. Accordingly, G*Power (Version 3.1) indicates that a power of \(80\)%, \(90\)%, and \(95\)% is achieved with sample sizes of \(3\), \(4\), and \(4\) participants, respectively, for both effects (assuming a correlation of \(r=0.5\) between repeated measures in all power calculations).
f <- effectsize::eta2_to_f(0.389) * sqrt(6/(1-0.5))We get an error message because the sample size is smaller than the number of measurements, but we can still compute the power for a given sample size.
Repeated-measures ANOVA analysis
n f ng nm nscor alpha power
3 2.764043 1 6 1 0.05 0.8231387
4 2.764043 1 6 1 0.05 0.9631782
NOTE: Power analysis for within-effect test
URL: http://psychstat.org/rmanovaRepeated-measures ANOVA analysis
n f ng nm nscor alpha power
3 2.990386 1 6 1 0.05 0.8835981
4 2.990386 1 6 1 0.05 0.9836138
NOTE: Power analysis for within-effect test
URL: http://psychstat.org/rmanovaThe WebPower package also has a graphical interface online for effect size calculations.
Summary
- Effect sizes are used to provide a standardized measure of the strength of a result, independent of the design and the sample size.
- There are two classes: standardized differences and proportions of variance.
- Multiple estimators exists: report the latter along with the software used to compute confidence intervals.
- The adequate measure of variability to use for the effect size depends on the design: we normally include the variability of blocking factors and residual variance.
- Given a design, we can deduce either the sample size, the power or the effect size from the other two metrics. This allows us to compute sample size for a study or replication.
If we consider a balanced sample, \(n_1 = n_2 = n/2\) we can rewrite the statistic as \(T = \sqrt{n} \widehat{d}_s/2\) and the statement that \(T\) increases with \(n\) on average becomes more obvious.↩︎
By using the pivot method, e.g., Steiger (2004), and relating the effect size to the noncentrality parameter of the null distribution, whether \(\mathsf{St}\), \(\mathsf{F}\) or \(\chi^2\).↩︎
The confidence intervals are based on the \(\mathsf{F}\) distribution, by changing the non-centrality parameter and inverting the distribution function (pivot method). This yields asymmetric intervals.↩︎
Typically, there won’t be any interaction with blocking factors, but it there was for some reason, it should be included in the total.↩︎
Specifically, the standard error decreases with sample size \(n\) at a rate (typically) of \(n^{-1/2}\). The null distribution also becomes more concentrated as the sample size increase.↩︎
While the default is to assign an equal number to each subgroup, power may be maximized by specifying different sample size in each group if the variability of the measurement differ in these groups.↩︎
Note that the \(F(\nu_1, \nu_2)\) distribution is indistinguishable from \(\chi^2(\nu_1)\) for \(\nu_2\) large. A similar result holds for tests with \(\chi^2\) null distributions.↩︎
Really, these are fiducial intervals based on confidence distributions.↩︎
Note that, when the test statistic representing the proportion of variance explained is strictly positive, like a \(F\) or \(\chi^2\) statistic, the corresponding effect size is an estimated percentage of variance returned by, e.g., \(\widehat{\omega}^2\). To ensure consistency, the confidence intervals are one-sided, giving a lower bound (for the minimum effect size compatible with the data), while the upper bound is set to the maximum value, e.g., 1 for a proportion.↩︎
It isn’t always obvious when marginalizing out a one-way ANOVA from a complex design or when we have random effects or blocking factor what the estimated standard deviation should be, so it is left to the user to specify the correct quantity.↩︎
As the example of Baumann, Seifert-Kessell, and Jones (1992) showed, however, not all statistics can be meaningfully converted to effect size.↩︎